RTO 和 RPO 都是企业灾难恢复(Disaster Recovery, DR)需要考虑的关键指标,这两个指标可以用来指导企业来制定合适的业务系统服务或数据的恢复方案。 RPO(Recovery Point Objective):即数据恢复点目标,主要指的是业务系统所能容忍的数据丢失量。 如果以定
# Windows 和 linux 下面 Redis 性能比较 ## 问题来源 ``` 公司里面有一些环境还是使用Windows来跑 对应的. Redis和nginx 也是跑在Windows上面 但是微软官网自从 3.2.100 之后就再也没有编译过Windows版本的redis 网上能找到的基本上
tcpdump 和 Wireshark 是最常用的网络抓包和分析工具,更是分析网络性能必不可少的利器。 tcpdump 仅支持命令行格式使用,常用在服务器中抓取和分析网络包。Wireshark 除了可以抓包,还提供了强大的图形界面和汇总分析工具,在分析复杂的网络情景时,尤为简单和实用。因而,在实际分
现在已经出现了 Task 和 PLinq 等更高效率的并发类,线程和线程池在实际开发中逐渐减少了,但是别人用了你也得能看懂,所以本文简单梳理一下。
抽象类和接口的相似之处还是很多的,但是它们的侧重点不同,本文将简单梳理下。
开发者和其他行业的从业人员一样,面对一个月前所完成的工作可能印象模糊,甚至不记得工作的内容。而不同于其他行业,开发者们则需要锻炼更好的抽象和文本记忆能力,来帮助他们在开发过程中更顺利地完成工作。 在本篇文章中,我将和大家一起探讨如何培养开发人员的记忆能力,以及这类能力如何帮助开发人员更好地完成开发工
AI 时代,DevOps 与 AI 共价结合。AI 由业务需求驱动,提高软件质量,而 DevOps 则从整体提升系统功能。DevOps 团队可以使用 AI 来进行测试、开发、监控、增强和系统发布。AI 能够有效地增强 DevOps 驱动流程,从开发人员的业务实用性和支持的角度来看,评估 AI 在 D
DevOps和 GitOps 之间的关系是什么? 哪种方法更适合你的企业采用?
activated和deactivated是Vue3中的两个生命周期钩子函数。 activated钩子函数在组件被激活时调用,通常用于恢复组件的状态或执行一些初始化操作。例如,如果一个组件被从路由中激活,你可能需要在该组件被激活时从本地存储中加载一些数据。 下面是一个示例代码:
在数学中,线性关系和非线性关系是描述两个变量之间函数关系的两种不同类型。 线性关系是指两个变量之间可以用一条直线来表示的关系。具体来说,如果存在一个一次函数 y = kx + b,其中k和b是常数,使得对于每一个x的值,都有唯一的y值与之对应,那么这两个变量之间就是线性关系。例如,如果x表示时间,y
本博客将测试MessagePack 和System.Text.Json 序列化和反序列化性能 项目文件: Program.cs代码: using BenchmarkDotNet.Running; using Demo; var summary = BenchmarkRunner.Run
VGGNet和GoogLeNet等网络都表明有足够的深度是模型表现良好的前提,但是在网络深度增加到一定程度时,更深的网络意味着更高的训练误差。误差升高的原因是网络越深,梯度弥散[还有梯度爆炸的可能性]的现象就越明显,所以在后向传播的时候,无法有效的把梯度更新到前面的网络层,靠前的网络层参数无法更新,
1.TextCNN原理 CNN的核心点在于可以捕获信息的局部相关性,具体到文本分类任务中可以利用CNN来提取句子中类似N-Gram的关键信息。 (1)一维卷积:使用不同尺寸的kernel_size来模拟语言模型中的N-Gram,提取句子中的信息。即TextCNN中的卷积用的是一维卷积,通过不同ker
DevOps、SRE和平台工程的概念在不同时期出现,并由不同的个人和组织开发。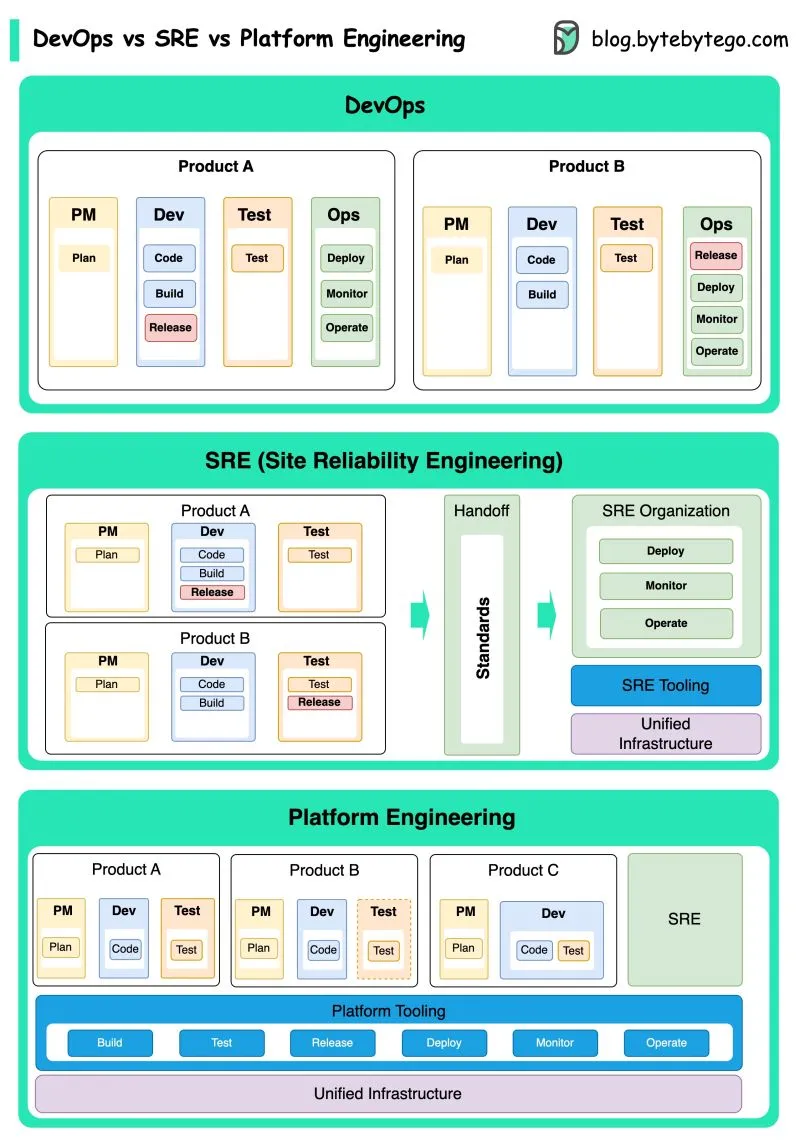 - DevOps作为一
GMT 和 UTC 时间有何区别?Unix 时间例程为何不处理闰秒?系统时区是如何设置的?哪些时间例程受夏时制影响?localtime 和 gmtime 是否共享内部存储区?strftime 获取第几周使用的 %U/%V/%W 有何区别?linux date 和 mac date 语法有何区别?本文一一为你解答
累加和为 K 的子数组问题 作者:Grey 原文地址: 博客园:累加和为 K 的子数组问题 CSDN:累加和为 K 的子数组问题 题目说明 数组全为正数,且每个数各不相同,求累加和为K的子数组组合有哪些, 注:数组中同一个数字可以无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的
# 算法和数据结构学习中的一些小的工具函数 作者:[Grey](https://www.cnblogs.com/greyzeng/) 原文地址: [博客园:算法和数据结构学习中的一些小的工具函数](https://www.cnblogs.com/greyzeng/p/17118195.html) [
随着技术的不断的发展,大数据领域对于海量数据的存储和处理的技术框架越来越多。在离线数据处理生态系统最具代表性的分布式处理引擎当属Hive和Spark,它们在分区策略方面有着一些相似之处,但也存在一些不同之处。
List和SList都是C++ STL中的容器,都是基于双向链表实现的,可以存储可重复元素的特点。其中,List内部的节点结构包含两个指针一个指向前一个节点,一个指向后一个节点,而SList只有一个指针指向后一个节点,因此相对来说更节省存储空间,但不支持反向遍历,同时也没有List的排序功能。双向链表的数据元素可以通过链表指针串接成逻辑意义上的线性表,不同于采用线性表顺序存储结构的`Vector`
感觉和放到一个 yaml 文件中,用 分隔,操作繁琐程度上,没有太大区别 创建自定义 Chart # 创建自定义的 chart 名为 mychart [root@k8smaster ~]# helm create mychart Creating mychart [root@k8smaster ~]