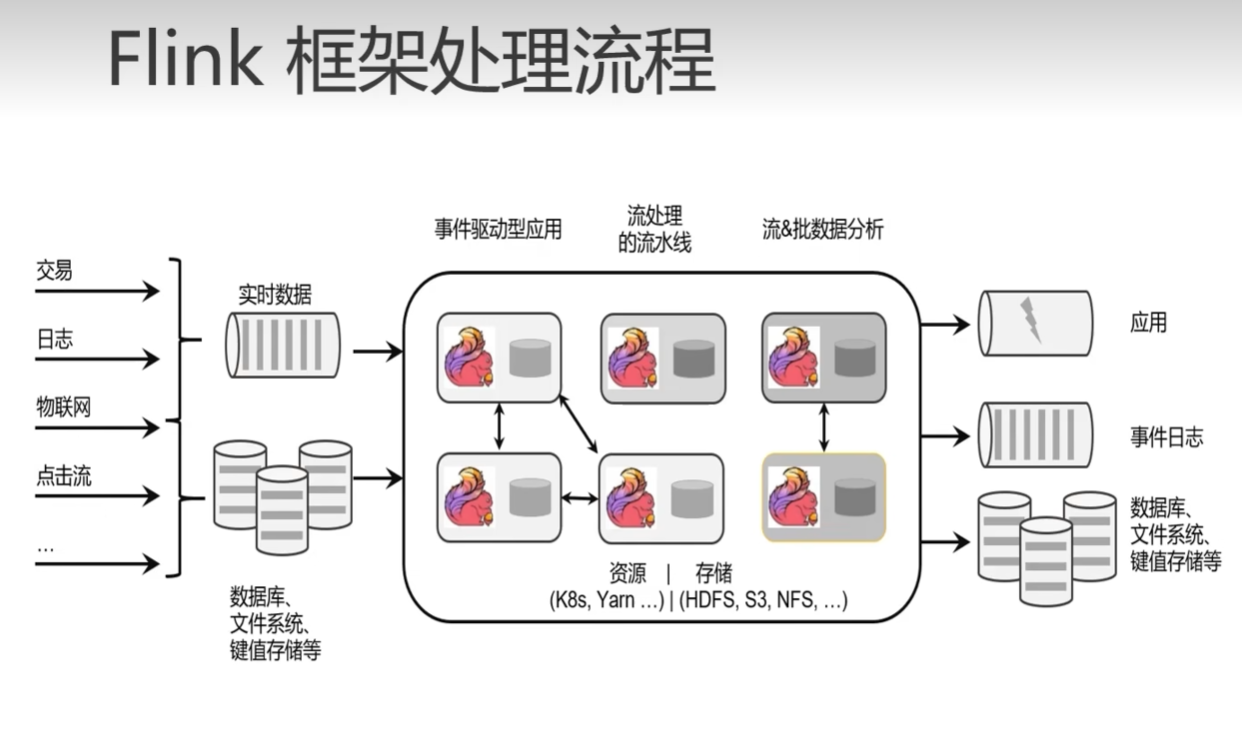
我们现在来研究网络中的传播。事实上,在网络中存在许多从节点到节点级联的行为,就像传染病一样。这在不同领域中都有所体现,比如生物中的传染性疾病;信息技术中的级联故障与信息的传播;社会学中的谣言、新闻、新技术的传播以及虚拟市场。其中在信息技术中信息就会经由媒体来进行扩散(diffusion)。接下来我们看如何基于网络构建传播模型。以传染病为例,传染病会沿着网络的边进行传播。这种传播形成了一个传播树,也
这篇博客让我们来介绍基于概率的传播模型,这种模型基于对数据的观测来构建,不过不能对因果性进行建模。基于随机树的传染病模型是分支过程(branching processes)的一种变种。在这种模型中,一个病人可能接触d个其他人,对他们中的每一个都有概率q>0将其传染,接下来我们来看当d和q取何值时,流行病最终会消失(die out)
我们发现,现实世界许多网络的节点度分布与幂函数乘正比。事实上,航空网络的度分布常常满足幂律分布;而高速公路网络的度分布则常常满足泊松分布(指数族分布的一种),其均值为平均度。幂律分布就是一种典型的重尾分布(就像我们前面所展示的节点度高度倾斜)。但需要注意的是,正态分布和指数分布不是重尾分布。
数据抽象屏障是控制复杂性的强有力工具,然而这种类型的数据抽象还不够强大有力。从一个另一个角度看,对于一个数据对象可能存在多种有用的表示方式,且我们希望所设计的系统能够处理多种表示形式。比如,复数就可以表示为两种几乎等价的形式:直角坐标形式(实部和虚部)和极坐标形式(模和幅角)。有时采用直角坐标更方便,有时采用幅角更方便。我们希望设计的过程能够对具有任意表示形式的复数工作。
数据类型是编程语言中的一个重要概念,它定义了数据的类型和提供了特定的操作和方法。在 python 中,数据类型的作用是将不同类型的数据进行分类和定义,例如数字、字符串、列表、元组、集合、字典等。这些数据类型不仅定义了数据的类型,还为数据提供了一些特定的操作和方法,例如字符串支持连接和分割,列表支持排序和添加元素,字典支持查找和更新等。因此,选择合适的数据类型是 python 编程的重要组成部分。
 的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。 CDC 的种类 CDC 主要分为基于查询和基于 Binl
Caused by: org.apache.kafka.connect.errors.ConnectException: Error reading MySQL variables: The server time zone value '�й���ʱ��' is unrecognized or
Caused by: org.apache.kafka.connect.errors.ConnectException: The MySQL server is not configured to use a ROW binlog_format, which is required for this
| 目录 | 作用 | | | | | app | 产生各层数据的 flink 任务 | | bean | 数据对象 | | common | 公共常量 | | utils | 工具类 | app.ods.FlinkCDC.java package com.atguigu.app.ods; impo
我们前面采集的日志数据已经保存到 Kafka 中,作为日志数据的 ODS 层,从 Kafka 的ODS 层读取的日志数据分为 3 类, 页面日志、启动日志和曝光日志。这三类数据虽然都是用户行为数据,但是有着完全不一样的数据结构,所以要拆分处理。将拆分后的不同的日志写回 Kafka 不同主题中,作为日
业务数据的变化,我们可以通过 FlinkCDC 采集到,但是 FlinkCDC 是把全部数据统一写入一个 Topic 中, 这些数据包括事实数据,也包含维度数据,这样显然不利于日后的数据处理,所以这个功能是从 Kafka 的业务数据 ODS 层读取数据,经过处理后,将维度数据保存到 HBase,将事
大数据 ODS&DWD&DIM-SQL分享 需求 思路一:等差数列 断2天、3天,嵌套太多 1.1 开窗,按照 id 分组,同时按照 dt 排序,求 Rank -- linux 中空格不能用 tab 键 select id,dt,rank() over(partition by id order b
DWM 建表,需要看 DWS 需求。 DWS 来自维度(访客、商品、地区、关键词),为了出最终的指标 ADS 需求指标 DWT 为什么实时数仓没有DWT,因为它是历史的聚集,累积结果,实时数仓中不需要 DWD 不需要加工 DWM 需要加工的数据 统计主题 需求指标【ADS】输出方式计算来源来源层级
统计主题 需求指标【ADS】输出方式计算来源来源层级 访客【DWS】pv可视化大屏page_log 直接可求dwd UV(DAU)可视化大屏需要用 page_log 过滤去重dwm UJ 跳出率可视化大屏需要通过 page_log 行为判断dwm 进入页面数可视化大屏需要识别开始访问标识dwd 连续
之前数据分层处理,最后把轻度聚合的结果保存到 ClickHouse 中,主要的目的就是提供即时的数据查询、统计、分析服务。这些统计服务一般会用两种形式展现,一种是为专业的数据分析人员的 BI 工具,一种是面向非专业人员的更加直观的数据大屏。 以下主要是面向百度的 sugar 的数据大屏服务的接口开发
https://clickhouse.com/ 概念 ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),使用 C++语言编写,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。 OLAP:一次写入,多次读取 ClickH
缺失值指数据集中某些变量的值有缺少的情况,缺失值也被称为NA(not available)值。在pandas里使用浮点值NaN(Not a Number)表示浮点数和非浮点数中的缺失值,用NaT表示时间序列中的缺失值,此外python内置的None值也会被当作是缺失值。需要注意的是,有些缺失值也会以
Label-Studio导出数据后可通过label_studio.py脚本轻松将数据转换为输入模型时需要的形式,实现无缝衔接。 items["text"] = line["data"]["text"]
数据基于: [知识图谱(Knowledge Graph)- Neo4j 5.10.0 使用 - CQL - 太极拳传承谱系表](https://www.cnblogs.com/vipsoft/p/17631347.html) 这是一个非常简单的web应用程序,它使用我们的Movie图形数据集来提供列