冷知识:Mysql最大列限制和行限制 一、Mysql列数限制1.Mysql限制每个表的最大列数为4096列2.InnoDB限制每个表的最大列数为1017列 二、Mysql行大小限制 一、Mysql列数限制 这里说的限制分为两种,一种是Mysql的限制,一种是存储引擎的限制,比如Innodb、MyIS
知识普及 jmx JMX(java Management Extensions)是一个Java平台的管理和监控接口。任何程序,只要按JMX规范访问这个接口,就可以获取所有管理与监控信息,jconsole与Java VisualVM等常见监测工具都是基于jmx,JMX不但可以用于管理JVM,还可以管理
技术人当遇到具体问题,能给出的各种解决方案,有一种类型叫做workaround,翻译过来通常为“应变方法”、“变通方法”; 其实这种方式通常是没有找到根本的解决方案,但是为了快速恢复业务而采用的一种巧妙规避/跳过的方式。 举个具体的例子:我有测试需求要在主库创建一个新的PDB: 1.创建新的PDB
在上一篇 优化利器In-Memory开启和效果 中,提到的两个SQL对比,使用的是传统的dbms_xplan.display_cursor方式来查看执行计划,好处是文本输出的通用性强,基本信息也都有。 但如果大家参加过我们的RWP培训,就会发现O原厂强烈推荐大家使用的一个工具是 SQL Monito
环境: Oracle 19.16 多租户架构 经常会在网上看到有人写exists和in的效率区别,其实在新版本的数据库中,是不存在这个问题的,优化器会自己判断选择最优的执行计划。 为了直观的说明,我在PDB中构造如下测试用例: vi 1.sql select count(*) from v$acti
有客户遇到ORA-2289的报错,同事协助去现场排查,我帮着远程共同check下。 客户只是应用端报出的错误,为了进一步定位,服务端需要开errorstack协助定位具体问题。 下面就以这个ORA-2289为例,示范下errorstack的使用方法。 --开启errorstack alter sys
正常情况按照标准配置的环境变量,只能grid用户查看RAC集群资源状态。 crsctl stat res -t 但是绝大部分操作其实都是oracle用户来操作,比如启停数据库,操作完成以后就需要检查下集群资源状态。 看到好多DBA在现场操作时就是来回各种切换或开多个窗口。 其实有两个简单的解决方法可
为客户测试一个ADG场景问题,发现测试环境的日志切换频率过低,总是需要定期手工切换,这非常影响测试心情。 实际上,可以设置archive_lag_target参数强制日志切换。 比如设置: alter system set archive_lag_target=1800; 这样即使库没任何压力,半小
xtts的配置文件,有很多注释不想直接去掉的情况下,想清楚的看到目前设置了哪些参数,可以用grep过滤查看: `grep -vE '^#|^$' xtt.properties` 效果如下: ```shell [oracle@db11gcas xtt]$ grep -vE '^#|^$' xtt.pr
我的一套测试环境发现时间慢了10分钟,影响我做各类测试。 首先就想到NTP服务,发现已安装NTP安装包,也有默认的NTP配置文件,只是没有启用。 用到的相关命令参考如下: ```shell [root@bogon ~]# vi /etc/ntp.conf systemctl status ntpd
最近给某客户讲课时,碰到了幻灯片自动翻页的情况,发现是因为之前做过粗略的计时演练,有些片子就快速过了。 **问题现象:** 结果导致放映时也出现了某些片子快速被自动翻页。 **解决方案:** 设置成手动推进幻灯片的方式即可解决,具体如下图所示: ,但是在实际场景下可能并没有那么多种子给我们使用。为了解决这个问题,有许多无监督/自监督的知识图谱对齐方法被提出。其中包括基于GAN的方法,基于对比学习的方法等。他们在不需要事先给定锚点的情况下将来自不同知识图谱实体embeddings映射到一个统一的空间。
[TOC] 2012年5月17日,Google 正式提出了知识图谱(Knowledge Graph)的概念,其初衷是为了优化搜索引擎返回的结果,增强用户搜索质量及体验。 假设我们想知道 “王健林的儿子” 是谁,百度或谷歌一下,搜索引擎会准确返回王思聪的信息,说明搜索引擎理解了用户的意图,知道我们要找
[知识图谱(Knowledge Graph)- Neo4j 5.10.0 Docker 安装](https://www.cnblogs.com/vipsoft/p/17623086.html) [知识图谱(Knowledge Graph)- Neo4j 5.10.0 CentOS 安装](https
目录创建节点删除节点查询节点创建关系新节点无属性关系删除关系案例 -- 太极拳传承谱系表创建传承人创建师徒关系创建第N代传承人案例 -- 批量执行 看到后面的案例再实操作 删除数据库中以往的图 MATCH (n) DETACH DELETE n 创建节点 CREATE命令语法 Neo4j CQL“C
下载地址:https://neo4j.com/download/ ## 安装 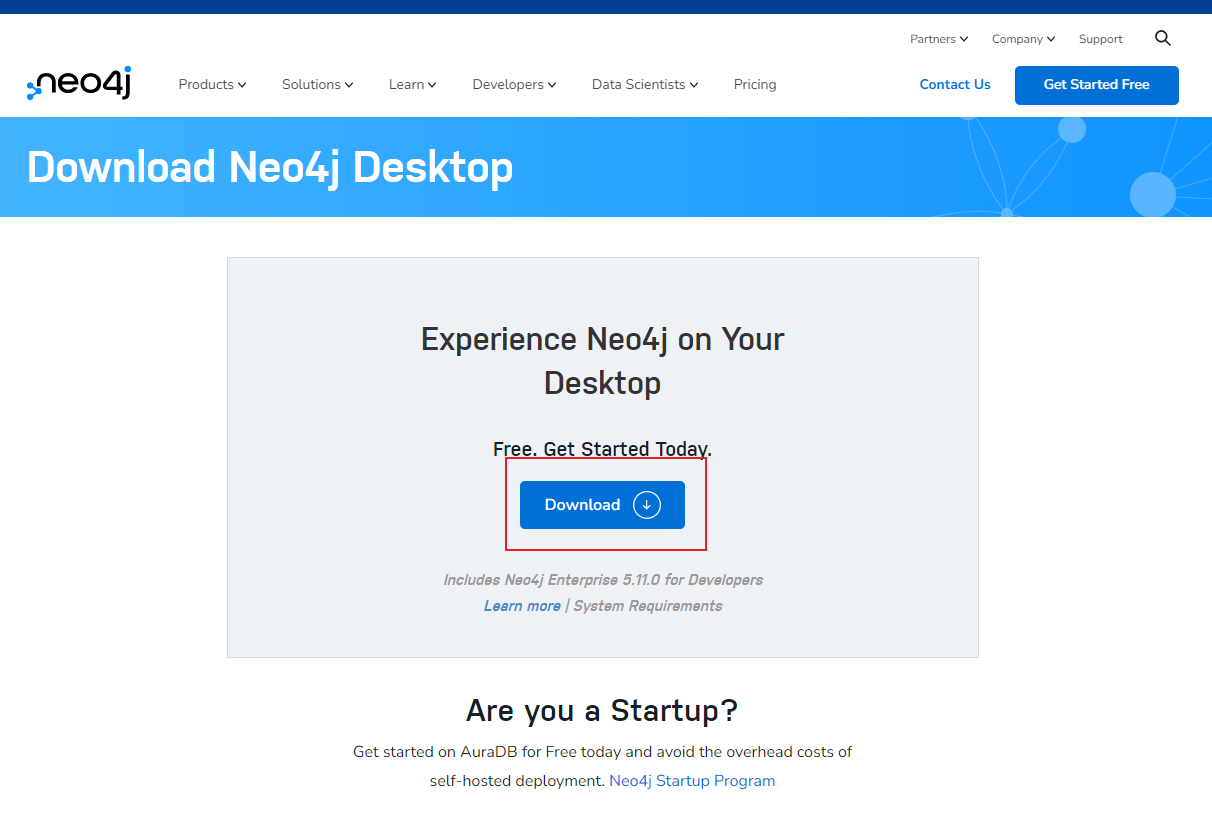 下载时会产生激活码(保存下来)
``` #输入查看数据库连接 neo4j$ :server status ``` 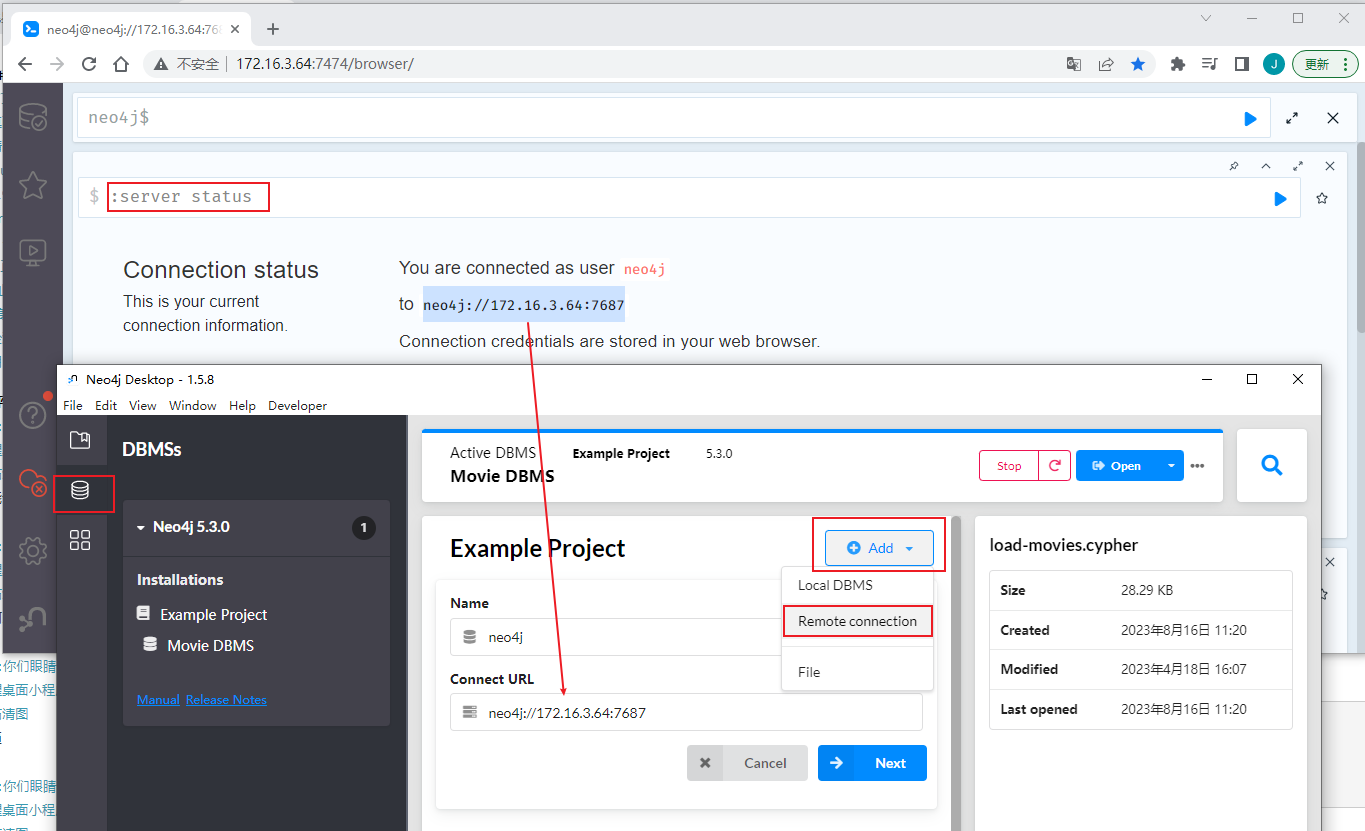 添加 远程连接,输入连接地址 !
上一篇使用了 CQL 实现了太极拳传承谱,这次使用JAVA SpringBoot 实现,只演示获取信息,源码连接在文章最后 三要素 在知识图谱中,通过三元组 集合的形式来描述事物之间的关系: - 实体:又叫作本体,指客观存在并可相互区别的事物,可以是具体的人、事、物,也可以是抽象的概念或联系,实体是
数据基于: [知识图谱(Knowledge Graph)- Neo4j 5.10.0 使用 - CQL - 太极拳传承谱系表](https://www.cnblogs.com/vipsoft/p/17631347.html) 这是一个非常简单的web应用程序,它使用我们的Movie图形数据集来提供列