https://zhuanlan.zhihu.com/p/561501585
2022/9/9更新:经过和评论区大佬的交流,准备研读一下JEDEC标准,主要是加深自己对banking和访存加速的理解(对应本文的第五节,主要问题集中在提出banking是为了隐藏row缺失造成的损失还是为了隐藏CPU和总线的工作时间),之后有了新的认识就更新一下文章。
正文:
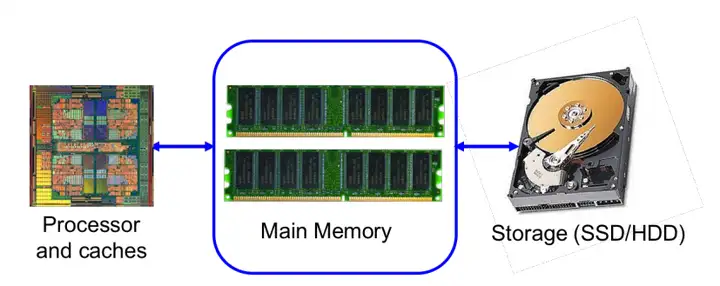
如果你是一个EECS专业的学生或领域内从业者,你一定经常听到别人谈论DRAM、内存和DDR——学数字电路和计算机组成的时候绕不过DRAM,讨论电脑性能的时候离不开内存,围观领域内公司发布新产品时,总是看到产品使用了所谓的xx通道DDR4/DDR5技术。那么,DRAM、内存、DDR到底是什么?
本文接下来会从问题出发,主要探讨DRAM的应用(用作内存)、基本结构(晶体管+电容)、读写原理(重点)、系统层次(bank、chip、rank、内存条和DDR)和CPU访问DRAM时的加速方法(猝发和交错,也是重点),有助于解开初学者的一些疑惑。
如果读者在阅读文章时感到困难,那么请试着继续往下读,文章内容是渐进的,前面避而不谈的内容很可能在后面被讨论到。
DRAM,全称为Dynamic Random Access Memory,中文名是“动态随机存取存储器”。所谓“动态”是和“静态”相对应的,芯片世界里还有一种SRAM静态随机存取存储器的存在。
笼统地说,DRAM的结构比SRAM更简单,面积占用更小,适合制作大容量的存储芯片;而SRAM结构复杂一些,一般使用六个晶体管,面积消耗大,但是读写速度快,而且因为SRAM只用到晶体管,所以在工艺上和逻辑芯片相兼容,我们可以在逻辑芯片上直接集成SRAM。
因为DRAM结构简单、面积消耗小,所以一般用DRAM制作逻辑芯片外的大容量存储芯片,比如内存芯片。如果学过计算机组成或微机原理的相关内容,大家一定知道内存芯片和CPU是分离的,CPU通过总线访问内存芯片,从内存芯片中读取数据,而这个内存芯片就是用DRAM制成的。
所谓DRAM,是指图一所示的一个电路,为了和DRAM芯片相区分,本文把图一的电路称作一个cell。图中的CMOS晶体管涉及到数字电路的知识。简单来说,CMOS晶体管是一个电子开关,当给晶体管最上面的一端(称作栅极)加上电压或是取消电压,晶体管两端就可以流过电流。cell中的小电容是存储信息的关键,小电容可以存储电荷,现在规定当电容存有电荷,cell存储比特信息“1”;当电容不存有电荷,存储比特信息“0”.
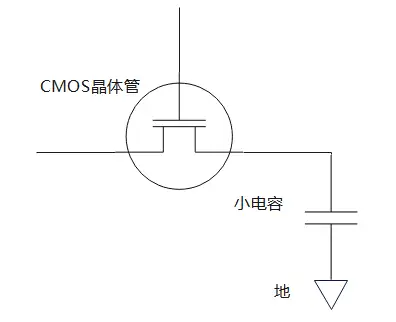
当要读取cell的存储值,首先打开电子开关(即晶体管),然后根据电容的充放电信息获得存储值。如果cell保存“1”,即电容存有电荷,那么当打开开关,电容就会放电;如果cell保存“0”,即电容不保存电荷,那么打开开关之后电容不会放电。
当要向cell中写入值,仍然先打开电子开关,然后在电子开关的另一侧施加电压。如果要写入“1”,则施加高电压,此时电流会通过晶体管向电容充电;如果要写“0”,则让电子开关另一端接地。施加电压一段时间后即可断开开关,此时cell已经保存好写入值,因为电容很小,所以施加电压的时间会很短。
一个cell只能存储一比特信息,即“0”和“1”,为了存储大量信息,我们必须构建起cell阵列。cell阵列的视觉图如图二。读者可能看不清图二中的小字,图二左侧的小字是“word line”,即字线;上面的小字是“bit line”,即位线。
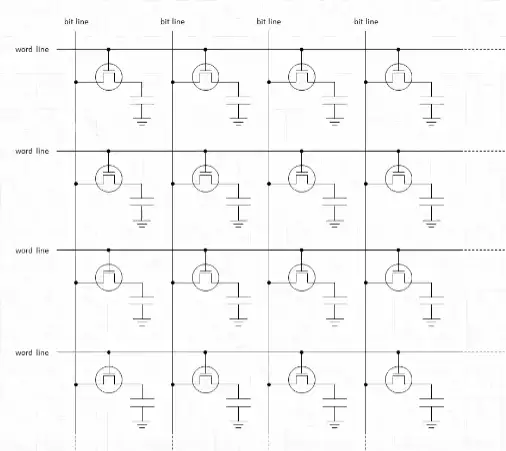
详细看看这个阵列是如何组织的。可以看到每行cell的晶体管的栅极都是连在一起的,即都连在字线上,这意味着给字线施加电压,字线对应的一行cell都会被打开。当一行cell被打开,cell电容就会向位线充放电,一行中的每个cell都与一条位线直接相连,读取位线的电压变化,即可知道cell的存储信息。
位线之所以叫位线,是因为在读取信息时,每一根线上的电压波动都代表一位比特信息,一根线代表一位,所以叫做位线;
字线之所以叫字线,是因为给这根线通电,一行cell都会被打开,在计算机里八位等于一个字节,多个字节等于一个字,因此多个cell组合起来就是多个字,因为这根线可以打开多个字,所以叫字线。
cell的读取依靠小电容充放电,电容充放电导致位线产生电压波动,通过读取位线电压波动即可获取信息。小电容充放电所产生的电压波动是很微弱的,充放电所造成的电压波动的时间也是很短的,因此很难直接读取充放电信息,为此cell阵列的读取使用到了“sense amplifier”,即读出放大器。
读出放大器可以捕捉到微弱的电压波动,并根据电压波动的情况在本地还原出cell的电容电压,而且放大器内还有锁存器,可以把还原出来的电容电压值保存起来,这样一来cell保存的信息就从cell电容转移到了放大器本地。
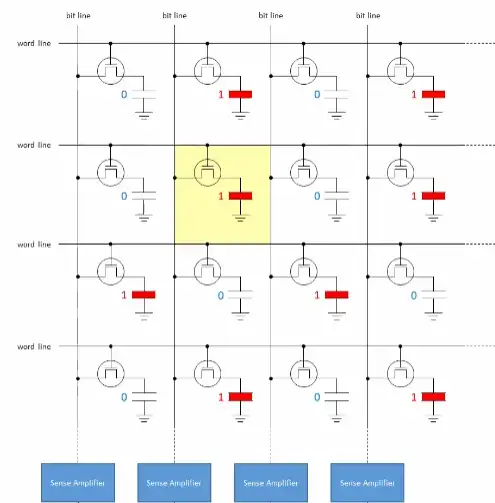
每条位线都要接到一个放大器中,效果图如图三。在读取cell行(之后也称作单元行)前,需要把每根位线都precharge(预充电)到电容电压/供电电压最大值的一半,如果供电电压是3V,那么就预充电到1.5V。预充电完毕后打开字线,单元行中每个cell电容或是向位线放电,或是由位线充电。放电者位线电压上升一点,充电者位线电压下降一点。放大器可以捕捉位线上的电压波动,继而在本地还原、暂存对应cell电压。
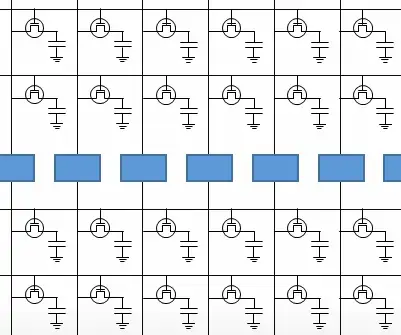
有的读者可能好奇放大器是如何捕捉微弱电压波动并还原cell电容电压的,实际上放大器涉及到模拟电路的知识,因为模拟电路不是本文的重点,所以这里不会展开。不过有一件事很重要:在DRAM芯片中,读出放大器把cell阵列分成了两半。
分成两半的效果图如图四。为什么要把cell阵列分成两半?因为一个放大器需要同时接入两根位线。为什么一个放大器要接两根位线?因为放大器在捕捉、放大其中一条位线的电压波动时需要另一条位线的帮助。DRAM芯片用到的放大器是“差分感测放大器”,它在放大信号波动时需要用一个基准和待测线作“比较”,此时接到放大器上的两条位线的其中一条就是所谓的基准,这条基准线经过预充电之后,其电压恒等于供电电压的一半。
更多关于存储芯片中差分放大器的内容可以参考《数字集成电路——电路、系统与设计》(第二版)的457~462页。
到这里我们清楚了cell阵列的读取,但是还有一个问题:在读取单元行时,读取行的cell电容经过充/放电之后,原本的信息就丢失了,即原来有的电荷现在放掉了,而原来没有电荷的现在却有了电荷。这种会造成信息丢失的读取行为称为“破坏性读出”。
破坏性读出是不行的,因此在读取单元行之后我们还要恢复单元行的信息。如何恢复?在读取时,放大器还原并暂存了单元行每个cell的电容电压,因此可以在输出完毕之后再把这些暂存电压写回原单元行。
具体做法是在读出数据之后,根据放大器锁存的值,把各条位线拉到供电电压或接到地,然后cell电容就会根据位线电压进行充电或放电,当cell电容充放电结束,就可以断开字线,断开字线也就宣告本次DRAM读取结束。
DRAM叫做动态随机存储器,“动态”从何而来?前面说过,cell电容的电容值很小,存储电荷不多,无论是充电还是放电都很快,而先进CMOS工艺有“电流泄漏”问题,因此即使不打开字线,cell电容也会缓慢损失电荷,久而久之信息就丢失了。解决这个问题的办法是“刷新”电容,即根据电容的旧值重新向cell写入数据。因为要经常动态地刷新电容,所以DRAM叫做动态随机存储器。
“电流泄漏”是指即使晶体管没有打开,晶体管仍然可以通过极小的电流
刷新电容如何实现的?在谈论“破坏性读出”时说过放大器可以还原并暂存cell信息,并把暂存的信息写回到cell电容,因此刷新电容也可以借助放大器。具体做法是对于每个单元行,每过一段时间就自主地进行读取,等放大器暂存好信息后就立刻写回。关于单元行的刷新时机也很有讲究,一般每64ms内就要对cell阵列进行一次全面刷新,有关“刷新”的更多内容这里不展开,有兴趣的朋友可以查看计算机组成的相关内容。
第一节讨论过cell阵列的读取,在实际应用中,不会直接把一整行数据全部读出,因为一整行数据太多,真实世界中我们往往只需要其中一个比特位,因此这一节主要谈谈实际DRAM芯片中单个比特的读写过程。
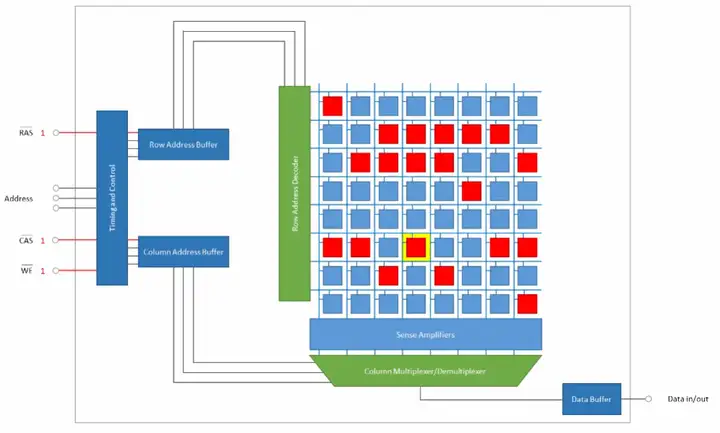
为实现单个比特的读写,必须为cell阵列配备一系列周围逻辑电路。图五是一个简单的示范。读者可能看不清里面的文字,cell阵列左边的绿色标记模块是“字线译码模块”,下面的蓝色模块是“读出放大器”,读出放大器下面的模块是“多到一选择器”和“一到多分配器”的集合,最左边的蓝色模块依次是“行地址缓存”、“列地址缓存”。
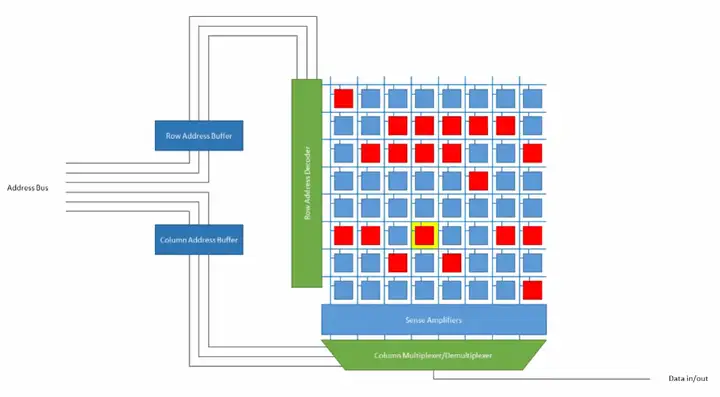
为找到二维阵列中的某一个单元,必须给出该单元的行号/行地址和列号/列地址,行地址缓存保存从地址总线上获取的行号,列地址缓存保存从地址总线上获取的列号。
其中,行地址会送往“字线译码模块”。字线译码模块是一个译码器,可以把短行号译码成长的独热码,独热码会开启一条字线,并打开该字线对应的单元行。
独热码是一串只有1位是1,其余全是0的二进制码字
单元行开启后,放大器捕捉位线上的电压波动,从而还原、暂存数据到放大器本地。
之后放大器把暂存的数据送到选择器,同时列地址也会被送到选择器,选择器根据列地址把数据中的某一位送到输出线。
输出数据之后,还要把单元行数据写回。
在图五的示范中,行地址和列地址是分别用两组总线送到DRAM芯片上的,这意味着DRAM芯片要为行地址和列地址准备两组输入口/pin口。而cell阵列越大,地址的位数就越多,当cell阵列很大时,准备两组输入口的代价十分昂贵,因此现代DRAM芯片让行地址和列地址共用一组总线,其效果图如图六。
图六行、列地址线各有三条,但它们对外只需要三个pin口,外界到DRAM芯片的三根地址线直接接到“时序控制模块”上,这个模块会选择性地把地址送到行地址缓存或是列地址缓存。在实际操作时,可以先给DRAM芯片输入行地址,然后再输入列地址。
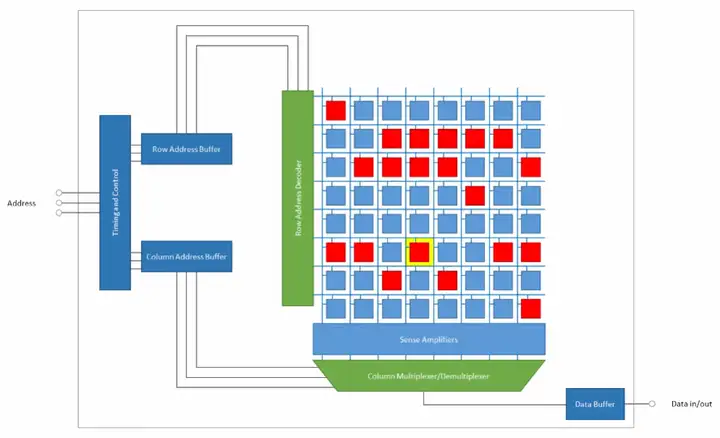
想要把地址选择性地送到地址缓存中,还需要一些控制线,即RAS(row address select)和CAS(colum address select),这两个控制信号指出当前地址线上的地址是行地址还是列地址。另外,为了向DRAM芯片写入数据,还需要“写使能”信号(WE,write enable)。把控制线和写使能加入芯片,效果图如图七。
既然说到了写使能,那我们是如何往DRAM芯片写入数据的呢?写入数据时,首先输入行号,打开目标单元行,把单元行数据缓存到放大器本地;然后输入列地址和写入数据,一到多分配器根据列地址把写入数据写入到放大器中,然后放大器把本地缓存写到单元行;写完后关闭单元行字线。
上面乱糟糟地这里说一通,那里说一通,可能读者还是不很清楚DRAM芯片是如何读写数据的,因此这里做一个完整过程的梳理。
在读取DRAM芯片单个比特数据时:
1、读取前,首先给各条位线预充电(也称为precharge),即把位线电压拉高到供电电压的一半,拉高到一半的目的是和cell电容电压形成电压差,从而在打开单元行时产生电压波动,注意,预充电完成后,就可以断开位线与预充电电源的连接,此时位线处于悬空态,电压仍然保持为供电电压的一半;
2、开始读取,首先在地址总线上输入行地址,稍后立刻置“行地址选通”(即RAS)有效,置RAS有效后,DRAM芯片就把行地址缓存下来;
3、缓存好行地址之后,就把行地址送入译码模块,译码模块把行地址译码成独热码,独热码的每一位都接到对应的字线,理所当然的,独热码会把其中一条字线的电压值拉高;
4、拉高的字线所对应的单元行被打开,即单元行的晶体管导通,单元行的各个cell电容和位线连通。如果cell保存比特信息1,即cell电容的电压等于供电电压,此时cell电容电压高于位线电压,电容放电,位线的电压稍稍上升;如果cell保存比特信息0,即cell电容的电压等于地电压,即0电压,此时位线电压高于cell电容电压,位线向cell电容充电,位线电压稍稍下降;
5、放大器捕捉位线上的微弱电压波动,通过“差分感测”在本地生成并暂存cell电容电压。举个例子,如果cell电容等于供电电压,那么位线电压稍稍上升,放大器比较此位线和另一条基准线的电压,通过模拟电路的反馈来放大两者的电压差,最终在本地生成一个等于供电电压的输出电压,并用锁存器把输出电压锁存下来。同理,如果cell电容电压等于0,放大器最终生成等于0的输出电压,并用锁存器把0电压锁存下来;
6、放大器锁存好行数据之后,把行数据送往多到一选择器;
7、多到一选择器根据列地址,把单元行中的某一位送到输出线;
8、输出之后,还需要把放大器的数据写回到单元行,即根据放大器的锁存值把位线拉高到供电电压或是0电压,位线向cell电容充放电,充放电结束之后,就可以关闭字线;
9、写回数据并关闭字线之后,连接位线和预充电电源,给位线预充电到供电电压的一半,为下一次读写做好准备。
请注意,上面的过程没有提到列地址哪里来的,实际上,在行地址被缓存下来之后,外界会把地址线上的地址从行地址转换成列地址,转换成列地址之后外界会置“列地址选通”有效,然后DRAM会把列地址缓存起来,等到第6步放大器送数据过来时,列地址缓存就把列地址送到多到一选择器,参与输出比特的选择。更清楚地说,列地址的缓存发生在第2步之后、第7步之前。
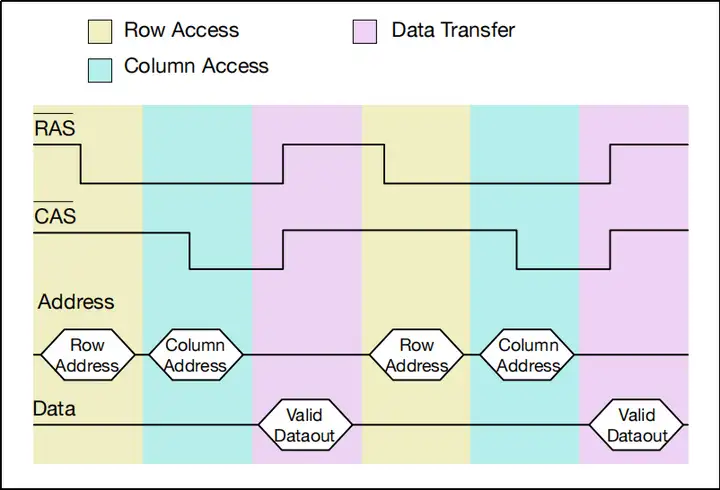
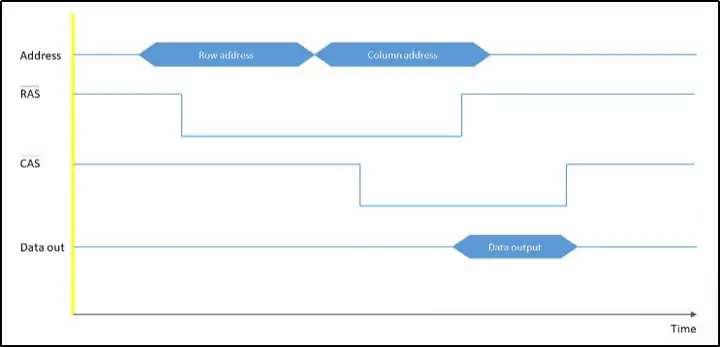
图八、图九是DRAM芯片读过程的简略信号时序图,不完全一样,但都是正确的读过程,通过结合时序图和上面的文字,相信大家能更好地理解DRAM读的过程。其中第一张图中色块和色块的边界代表时钟的有效边沿,相信有数字电路基础的朋友很容易get到这一点。注意,RAS和CAS头上有一条横线,这代表它们是低电平有效信号。
写过程和读过程有很多相似之处:
1、位线预充电到供电电压的一半;
2、输入、缓存行地址,译码行地址,开通单元行,开通单元行后位线产生电压波动,放大器捕捉电压波动并还原、暂存行数据到本地;
3、输入、缓存列地址,与此同时置写使能有效,并在Data Buffer存进写入比特,注意,Data Buffer在读取DRAM时用来暂存输出比特,而在写DRAM时则用来暂存写入比特;
4、把写入比特送到一到多分配器,分配器根据列地址把写入比特送到对应的放大器中,放大器根据写入比特改写本地暂存值;
5、放大器根据暂存的电压值刷新单元行,刷新完毕后断开单元行的字线;
6、刷新完毕后,重新给位线预充电,为下一次读写做好准备。
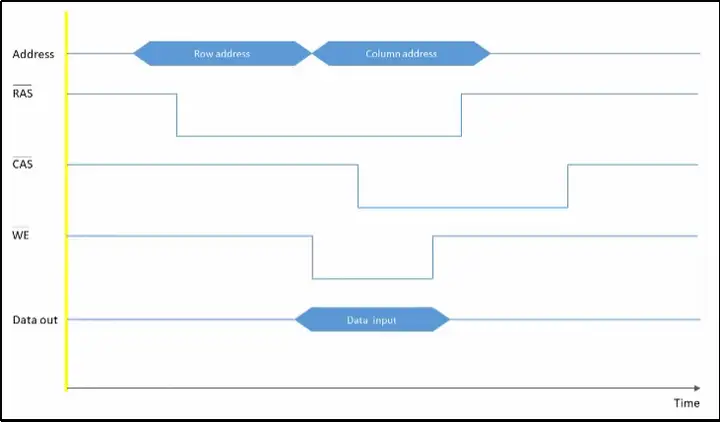
图十是一张写过程的信号时序图(最好用电脑查看),结合文字和图,可以更好地理解这个过程。
前面解读了DRAM读写一个比特的完整流程,现在我们来聊聊读写过程的时间花费。
总的来说,读取一个比特的总体流程是:获得行号,译码行号,开启单元行,放大位线电压波动并暂存数据到放大器,获得列号并根据列号选择一位进行输出,写回数据,关闭字线,重新预充电。
而写一个比特的总体流程是:获得行号,译码行号,开启单元行,放大位线电压波动并暂存数据到放大器,获得列号并输入写入数据,根据列号把写入数据送到放大器并改写暂存值,写回数据,关闭字线,重新预充电。
在以上两个流程中,时间花费的大头是“开启单元行”、“放大电压波动并暂存数据”。
“开启单元行”之所以花费时间,是因为行地址译码器需要拉高一条字线,然后用这一条字线拉高单元行上所有晶体管的栅极电压,而拉高这么多的栅极电压很耗时间。为什么?现在我们可以把这些栅极抽象成一个一个电容,如果大家学过电路分析,就知道拉高电容的电压是需要时间的,电容越大,所需时间越长,而单元行上的栅极可以整体抽象成一个很大的电容,DRAM读写就是用一根字线给这个很大的电容充电,因此时间消耗很大。如果cell阵列设计的不合理,即单元行上的cell数量太多,那么“开启单元行”会变得很昂贵。
放大器放大电压波动并暂存数据也很消耗时间,因为放大器大部分是模拟电路,工作速度不快。
通过上面的分析,我们可以推导出一个结论:在读写DRAM时,最好不要频繁地开启新单元行和使用放大器。可是怎样才能避免这么做呢?上面的读写过程不是包含有这两步操作吗?
解密的关键在于放大器的缓存区。我们前面总在说数据会被缓存到放大器本地,用术语来说,这个本地缓存叫做row buffer,即“行缓存”。前面说的读写过程都是针对一个比特的,读写一个比特需要把一行数据全部读下来,并在操作完毕之后写回单元行,这么做就相当于每次读写操作都要经历“开启单元行、放大、读数写数、写回”的全流程,这太浪费时间,为节省时间我们应当尽可能多地利用这一行数据,具体方法就是不要每读写完一个比特就把row buffer里的数据写回,而是先保持row buffer数据,等待后续指令,如果后续指令还要读写这一行的数据,那么就可以直接操作row buffer,而不需要开启单元行并抓取数据。下面两张图依次是“读一个比特就写回”和“保持row buffer并连续读一行中的多个比特”的时序图,显然第二个办法效率更高。
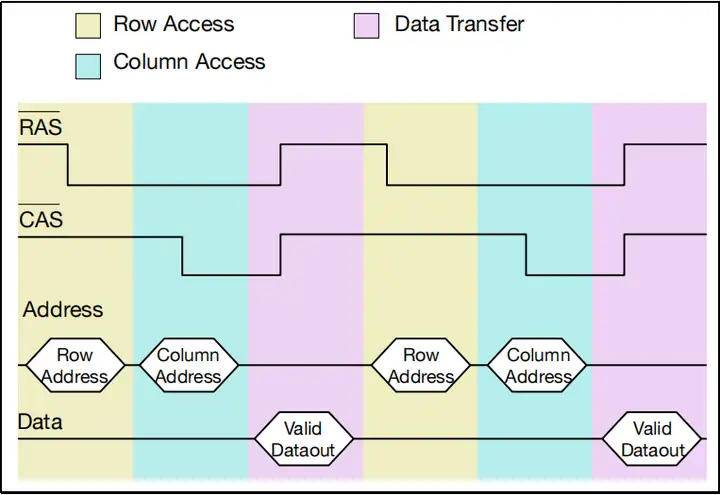
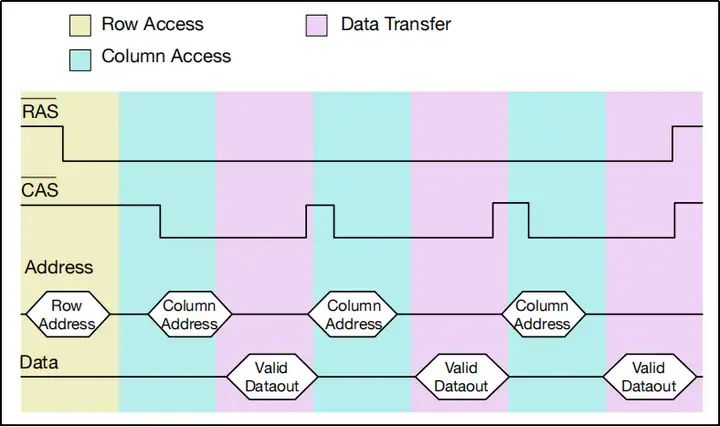
了解到上面一段的内容之后,自然而然得出总结:在允许row buffer长时间保持行数据的情况下,如果读写请求发生在row buffer保存的单元行中(这种情况称为“行命中”),那么DRAM的读写速度会很快,因为DRAM可以直接操作row buffer,而不需要读取新的单元行;而如果读写请求发生在row buffer之外的单元行中(这种情况称为“行缺失”),那么DRAM就要把row buffer写回并读取新的单元行,这样做速度会很慢。
第二大节简单说明了如何读写cell阵列中的一个比特,并简单讨论了读写时间和row buffer的话题。读者在阅读的时候可能会想到一个问题,即CPU在读写数据的时候都是面向“字”的,而一个cell阵列一次只能读取一个比特,那现实世界中的存储芯片实际上是如何向CPU提供字的呢。本节会解答这个问题。
一个cell阵列一次可以提供一个比特,那么多个cell阵列就可以一次提供多个比特。假如CPU一次读写8个比特,那么我们就可以用8个cell阵列。查找cell阵列中的一个单元需要有其行号和列号,那CPU是否需要给8个cell阵列提供8组地址呢?不需要,8个cell阵列可以共享一组行地址和列地址。共享行、列地址的一组cell阵列被称作一个bank,下图展示了一个含有8个cell阵列的bank。它们共用行地址、列地址和地址选通、写使能,每个阵列提供一条输出线,8个阵列最终组成8根输出线,可以输出8个比特。
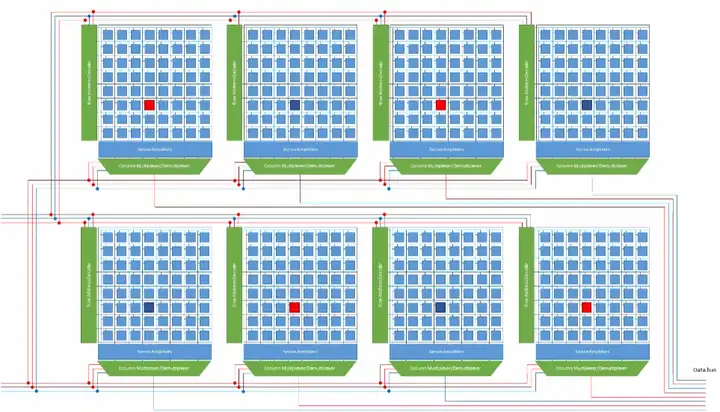
一个8阵列bank一次读写8个比特,一颗存储芯片上一般含有多个bank,下图是一颗含有8个bank的存储芯片的示意图。芯片每次读写都只针对一个bank,因此读写地址必须包含一个bank号,bank号用于开启目标bank,目标bank之外的bank是不工作的。
拆过电脑的朋友知道电脑用的内存芯片都嵌在一个电路板上,把这个电路板插入内存插槽后,就可增加电脑内存。电路板加板上的芯片,这就是所谓的内存条,也称为DIMM条(全称Dual-Inline-Memory-Modules,中文名叫双列直插式存储模块)。内存条通过“内存通道”连接到内存控制器,一组可以被一个内存通道同时访问的芯片称作一个rank。一个rank中的每个芯片都共用内存通道提供的地址线、控制线和数据线,同时每个芯片都提供一组输出线,这些输出线组合起来就是内存条的输出线。
下图是一个包含8颗芯片的DIMM条。这8颗芯片被一个内存通道同时访问,所以它们合称为一个rank。有的DIMM条有两面,即两面都有内存芯片,这种DIMM条拥有两个rank。
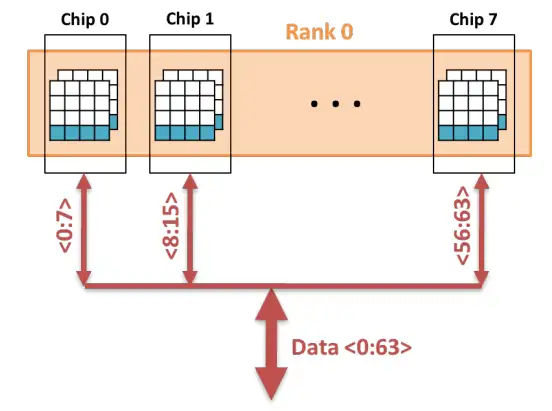
假设上图中的每个芯片都包含8个bank,每个bank都包含8个阵列,那么这条内存条就可以一次读写8×8=64比特,其中第一个8是指每个芯片输出8位,第二个8是指这个rank总共有8颗芯片,因为这8颗芯片被同一个内存通道访问,所以其被访问的bank和bank内的行地址、列地址都是完全一致的。下图是一个描述这个过程的简图:显然,我们在读写8颗芯片同一个bank同一个位置的cell,注意,图中没有显示不在工作状态的bank。
电脑有时候可以插入多个内存条,多个内存条有助于提升电脑的内存容量,但是未必能提高电脑的速度。电脑的速度受“内存通道”数限制,如果电脑有四个插槽,却只有一个内存通道,那么CPU仍然只能一次访问一个rank;但如果电脑有四个插槽的同时还有四个内存通道,那么CPU就可以一次访问四个rank,很显然,四并行访问明显比串行访问快,假设每个rank可以输出64比特,那么四通道就可以一次访问4×64=256比特,而单通道只能访问64比特。
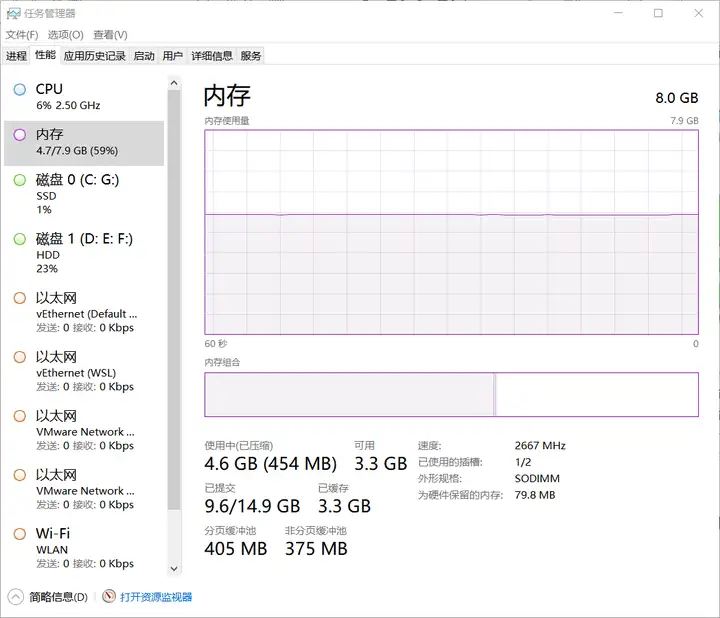
平常听到的所谓x通道内存就是指电脑有x个内存通道,很显然,这个x越大越好,不过仅有通道也不够,还得为通道提供rank,即为电脑插上足够多的内存条。我们可以打开电脑的“任务管理器”查看自己电脑的内存插槽数,下面是我的电脑的内存情况,图中显示我的电脑有两个插槽,但是只插了一个DIMM条。
在网上下载CPU-Z软件即可查看自己电脑的内存通道数,下面是我的电脑的参数图,图中显示我的电脑只有一个内存通道(悲)。
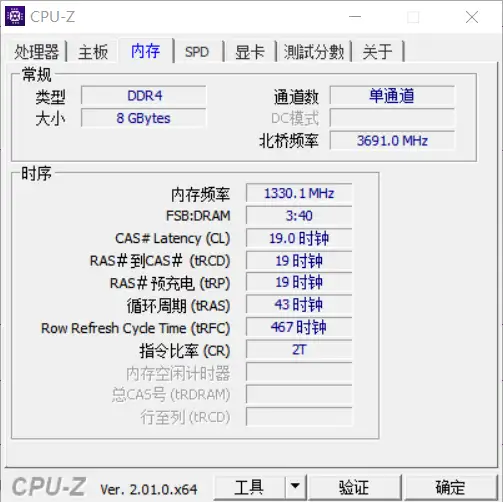
有仔细看图的小伙伴可能发现一个问题,即任务管理器里面的内存频率是2600+MHz,而CPU-Z却显示内存频率只有1300+MHz,这是怎么回事?原因是我们现在的电脑都使用所谓的DDR内存,DDR内存可以同时在时钟上升沿和下降沿读写数据,因此DDR的工作频率其实是内存频率的两倍。
第三大节说明了CPU如何向内存条中的一个rank读写64比特,而如果读者对现代处理器有更多的了解,即了解cache的话,就会想到CPU在访问内存单个字的时候,不仅需要访问这个字,还需要把这个字所在的缓存行全部搬进cache中,因此内存不仅要一次提供一个字,还要提供一个缓存行(cache line)。
缓存行一般比较大,比如8个64比特,因此实际上内存要一次提供8×64=512比特数据。但如果按照第三节的模式访问内存,那么一次只能提取出64比特,即提取一个字,这并不满足缓存行的要求,为此,我们提出对内存使用“猝发模式”。
首先明确一点,缓存行内的各个字在内存上是紧邻的。有了这个基础,我们就可以灵活地使用cell阵列中的行缓存(row buffer)。第二节说到单元行进入放大器的行缓存之后,并不会在读写一个比特后立刻写回cell阵列,而是待在行缓存里等待下一个读写命令,如果下一个读写命令仍然发生在该单元行,那就可以直接操作row buffer。
在猝发模式里,我们更进一步,每当我们读取cell阵列中的一个比特,我们不仅把这个比特送到输出缓存中,而且紧接着把这个比特所在缓存行的各个比特都送到输出缓存,这样就完成了一次“猝发”,即把目标比特周围的多个比特连续地读出。
在第二大节中我们比较详细地聊了在一个cell阵列中读取数据的过程(对应下面5个步骤的第3步),而CPU在访问内存时,还需要一些别的操作。总的来说,CPU访存大概要经过5个步骤:
1、CPU发送指令给内存控制器;
2、内存控制器解析指令,并把“解析到的控制信息”发送到控制总线;
3、bank接收控制信息,并读取数据;
4、内存芯片把读取出的数据放到数据总线;
5、内存控制器收取数据,并将其交给CPU。
如果CPU连续访问同一bank,那么CPU、内存控制器、总线和bank就必须串行操作。可想而知,串行操作会让访存效率下降。
注意,这里我认为CPU不可以在一个bank工作时再给它发送新的指令,如果CPU连续不断地给一个bank发送指令,那么很可能前一个指令还没完成,后一个指令就改变了bank内的row buffer、列地址缓存或输出缓冲,这样是不行的。
有的朋友可能对1、2、4、5步的时间消耗和因此造成的效率下降不以为然,为了说明问题,下面以“总线延迟”为例:
众所周知,光速是3×10^8m/s,而高性能CPU的频率可达3GHz,即3×10^9Hz,那么在CPU的一个时钟周期内,光可以运动10cm。“But electricity travels about fifth as far as light in sillicon”,即“但是电在硅中的传播距离大约是光的五分之一”,内容参考自Stephen Jones GTC 2021的7min24s起,这里的 electricity 我认为其实是指电压最高点,Stephen总结道:“而在电子线路中 electricity 的运动则更加受限,经过测量,在电子线路中 electricity 在一个CPU时钟周期内只能运动20mm左右。”换句话说,每个时钟周期线路上的电压只能向前推进20mm,而CPU和内存芯片之间的距离远不止20mm,因此数据在总线上移动需要花费多个CPU时钟周期。
上面的计算说明,在CPU访存的5个步骤中,第2、第4步是要花很多时间的,而没有详细讨论的第1、第5步大概率比这两步还要慢。因此让CPU、内存控制器、总线和bank串行操作是不明智的。实际上,我们完全可以在一个bank进行第3步时,让CPU、内存控制器、总线去操作新的bank,以此隐藏起它们的工作时间,从而营造起一种CPU、内存控制器和总线不需要消耗时间的假象。上面这种做法实际上实现了“bank间并行”。
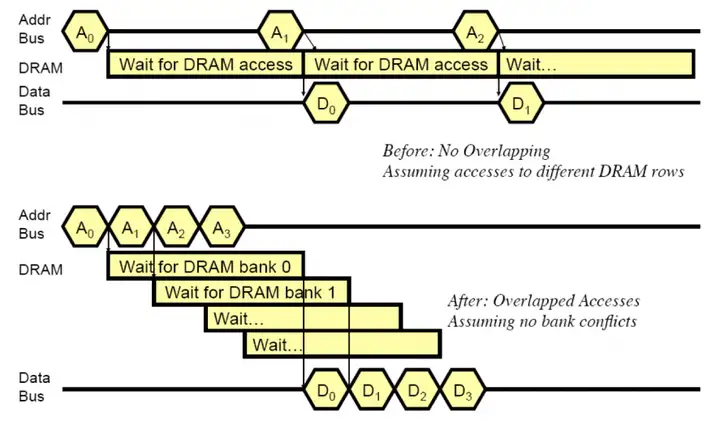
所谓在“bank间并行”就是让一个chip内的不同bank并行工作,让它们各干各的。为此CPU要连续、依次向不同的bank发送读取指令,这样在同一时间很多bank都在工作,第一个bank可能在输出,第二个bank可能在放大电压,第三个bank可能在开启单元行。当第一个bank猝发输出完毕,第二个bank刚好可以输出;当第二个bank猝发输出完毕,第三个bank刚好可以输出.......通过这样让“bank读取”和“CPU、内存控制器、总线工作”在时间上相互重叠的方式,我们可以成功地把CPU、内存控制器和总线的工作时间隐藏起来,从而打造出一种CPU无延迟访问内存、多个bank连续、依次“泵”出数据的理想情况。这种通过“bank间并行”实现“连续泵出数据”的方法,就是所谓的“内存交错”。
注意到,内存交错不仅隐藏了CPU、内存控制器和总线的工作时间,还隐藏了对单个bank而言row缺失所造成的多余访问时间(所谓“多余”是相对“row 命中”情况而言的),关于这个问题的更多内容,可以参考为什么banking能提高memory throughput。
下图是一个示范:上面的时序图是不使用内存交错时CPU接收数据的时序,下面的时序图是使用内存交错时CPU接收数据的时序。很容易看到在第一种串行方法里,数据总线的利用率是很低的,而内存交错方法则可以让各个bank连续泵出数据。
到这里为止,文章的内容就结束了,回顾一下,本文主要讨论了DRAM基本单元的结构、基本单元的读写原理、普通DRAM芯片的读写过程、读写时间消耗、row buffer、DRAM系统层次、猝发模式和内存交错等内容。
通过阅读本文,读者可以建立起对DRAM芯片的基本认识,了解CPU访存时存储芯片内部的动作,也有可能受到本文启发,发掘出自己对高性能内存系统的兴趣(×)。另外,读者还可以看看自己电脑的内存插槽数和内存通道数,更好地了解自己电脑的性能。咳咳。
文章主要参考的资料有两个,一个是油管上一个大哥(id:Computer Science)的系列视频,另一个是南京大学计算机系王炜老师的体系结构课课件,课件不便分享,不过油管视频大家感兴趣的可以看看(就不放油管链接了,放个国内小伙伴的中文翻译版的链接,链接如下),油管大哥做得确实好啊!