引言 当想要压缩一张彩色图像时,彩色图像通常由数百万个颜色值组成,每个颜色值都由红、绿、蓝三个分量组成。因此,如果我们直接对图像的每个像素进行编码,会导致非常大的数据量。为了减少数据量,我们可以尝试减少颜色的数量,从而降低存储需求。 1.主要原理 (一)颜色聚类(Color Clustering):
核心概念 主键索引/二级索引 聚簇索引/非聚簇索引 回表/索引覆盖 索引下推 联合索引/最左联合匹配 前缀索引 explain 一、[索引定义] 1.索引定义 在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法
众所周知,个性化推荐系统能够根据用户的兴趣、偏好等信息向用户推荐相关内容,使得用户更感兴趣,从而提升用户体验,提高用户粘度,之前我们曾经使用协同过滤算法构建过个性化推荐系统,但基于显式反馈的算法就会有一定的局限性,本次我们使用无监督的Lda文本聚类方式来构建文本的个性化推荐系统。 推荐算法:协同过滤
1. 背景 推荐系统的推荐请求追踪日志,通过ELK收集,方便遇到问题时,可以通过唯一标识sid来复现推荐过程 最近在碰到了几个bad case,需要通过sid来查询推荐日志,但发现部分无法在kibana查询到 2. 分析 推荐日志的整个收集流程如下: flowchart LR 线上机器日志 -->
https://www.cnblogs.com/pachongshangdexuebi/p/11507298.html 1、聚合报告添加 聚合报告是常用的监听器之一,添加路径: 点击线程组->添加->监听器->聚合报告 2、聚合报告界面及说明 Label:请求的名称,就是我们在进行测试的httpre
有一个IList()对象列表, 示例数据为[{id:'1',fieldName:'field1',value:'1'},{id:'1',fieldName:'field2',value:'2'},{id:'2',fieldName:'field1',value:'1'},{id:'2',f
之前数据分层处理,最后把轻度聚合的结果保存到 ClickHouse 中,主要的目的就是提供即时的数据查询、统计、分析服务。这些统计服务一般会用两种形式展现,一种是为专业的数据分析人员的 BI 工具,一种是面向非专业人员的更加直观的数据大屏。 以下主要是面向百度的 sugar 的数据大屏服务的接口开发
[TOC] 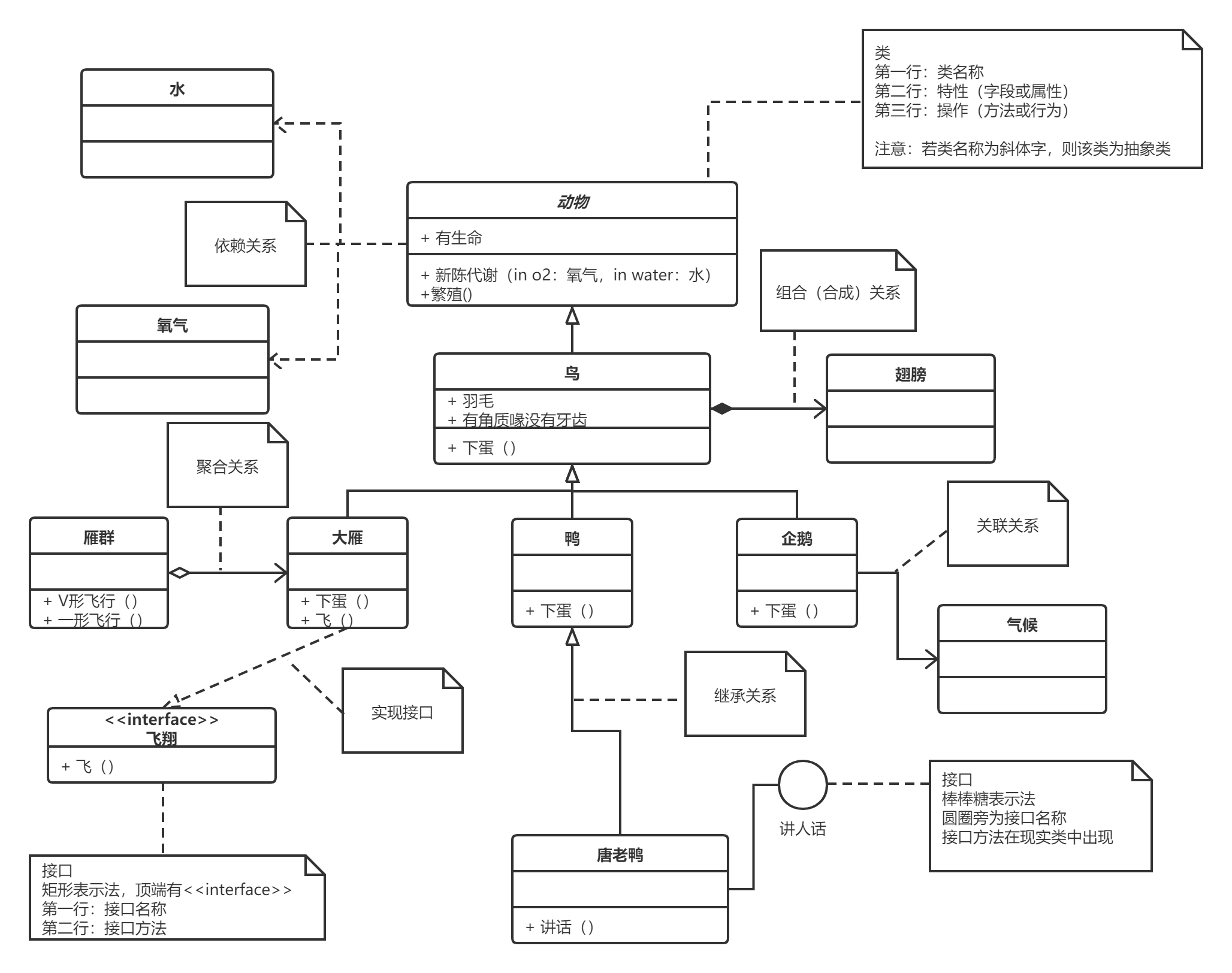 ## 类的表示(Class) 第一层:显示类的名称,如果是抽象类,则就用斜体显示。 第二层:是类的
在许多情况下,你可能不希望分析项目中每个源文件的各个方面。例如,项目可能包含生成的代码、库中的源代码或有意复制的代码。在这种情况下,跳过这些文件分析的部分或全部方面是有意义的,从而消除干扰并将焦点缩小到真正重要的问题上。 如果SonarQube的结果不相关,那么没有人会想要使用它。这就是为什么精确配
本文分享自华为云社区《2个RoCE网卡Bond聚合,实现带宽X2》,作者: tsjsdbd 。 我们知道操作系统里面,可以将2个实际的物理网卡,合体形成一个“逻辑网卡”,从而达到如主备/提升带宽等目的。但是RoCE网卡,是否也跟普通网卡一样,支持Bond能力呢?答案是的,RoCE也可以组Bond,只
摘要:在开发初期开发者往往聚焦在模型的精度上,性能关注较少,但随着业务量不断增加,AI应用的性能往往成为瓶颈,此时对于没有性能优化经验的开发者来说往往需要耗费大量精力做优化性能,本文为开发者介绍一些常用的优化方法和经验。 本文分享自华为云社区《如何使用ModelBox快速提升AI应用性能》,作者:
摘要:RPA可以模拟人工进行操作,比如平时的登录,操作文件,抓取数据,调用api,与数据库进行交互等操作,从而实现一系列自动化的实现。 本文分享自华为云社区《智能流程机器人助你“聚划算”》,作者: 华为云社区精选 。 相信大家都知道最近的数字员工非常火,比如我们中国的商飞上飞院三所的数字员工“思睿”
本文属于OData系列 Introduction ODATA v4提出了新的聚合查询功能,这对于ODATA的基本查询能力($expand等)是一个非常大的补充。ODATA支持的聚合查询功能,可以对数据进行统计分析,例如求和、平均值、最大/最小值、分组等。 聚合查询是通过$apply关键字实现的。使用
一文让你彻底了解:主键索引/二级索引,聚簇索引/非聚簇索引,回表/索引覆盖,索引下推,联合索引/最左联合匹配,前缀索引,explain
Karpor 是一个现代化的 Kubernetes 可视化工具,核心特性聚焦在 搜索、 洞察、✨ AI ,目标是更方便快捷地连接平台和多集群,并用 AI 赋能 Kubernetes,从大量集群资源中提炼关键性的洞察提供给开发者和平台团队,帮助他们更好地理解集群并做出决策。
摘要:该文指南详述了Nuxt 3的概况与安装,聚焦于在Nuxt 3框架下运用Vuex进行高效的状态管理,涵盖基础配置、模块化实践至高阶策略,助力开发者构建高性能前后端分离应用。
这篇文章介绍了微前端架构概念,聚焦于如何在Vue.js项目中应用Qiankun框架实现模块化和组件化,以达到高效开发和维护的目的。讨论了Qiankun的原理、如何设置主应用与子应用的通信,以及如何解决跨域问题和优化集成过程,从而实现前端应用的灵活扩展与组织。
https://zhuanlan.zhihu.com/p/602627000 寒假和朋友小聚,每当就专业问题展开谈话,很容易形成“一边热火朝天,一边大脑宕机”的局面。俗话说隔行如隔山,虽然和不同专业的朋友彼此之间隔了座山,但还是希望不要因为这座山隔阂了彼此的交流,另外也想一次性回答完朋友对我专业(全
https://cloud.tencent.com/developer/article/1988629 背景 本系列会聚焦在 TiFlash 自身,读者需要有一些对 TiDB 基本的知识。可以通过这三篇文章了解 TiDB 体系里的一些概念《 说存储 》、《 说计算 》、《 谈调度 》。 今天的主角
Health Kit文档全新升级,开发场景更清晰,聚焦你关心的问题,快来一起尝鲜! 文档入口请戳:[文档入口~](https://developer.huawei.com/consumer/cn/doc/development/HMSCore-Guides/description-000000155