本文全面回顾了机器学习的发展历史,从早期的基本算法到当代的深度学习模型,再到未来的可解释AI和伦理考虑。文章深入探讨了各个时期的关键技术和理念,揭示了机器学习在不同领域的广泛应用和潜力。最后,总结部分强调了机器学习作为一种思维方式和解决问题的工具,呼吁所有参与者共同探索更智能、更可持续的未来,同时关注其潜在的伦理和社会影响。
机器学习作为人工智能的核心部分,已经成为现代科技发展不可或缺的重要组成。随着大数据的兴起和计算能力的增强,机器学习技术逐渐渗透到我们生活的方方面面。本章节将简要介绍机器学习的基本定义、其重要性以及在各领域的应用场景。
机器学习是一门研究计算机如何利用经验改善性能的科学。它的主要目的是通过从数据中学习模式并作出预测或决策。在技术层面上,机器学习可以分为监督学习、无监督学习、半监督学习和强化学习等。
机器学习已经变得极其重要,它不仅推动了科学研究的进展,还促进了许多工业领域的创新。通过自动化和智能化的手段,机器学习正在不断改变我们的工作和生活方式。

机器学习的应用已经渗透到许多领域,包括但不限于:
机器学习的早期历史反映了人类对自动化和智能计算的初步探索。在这个时期,许多基本的算法和理论框架得以提出,为后续的研究奠定了坚实的基础。
在20世纪50年代至70年代,机器学习的早期阶段,许多核心的理论和算法得以形成。
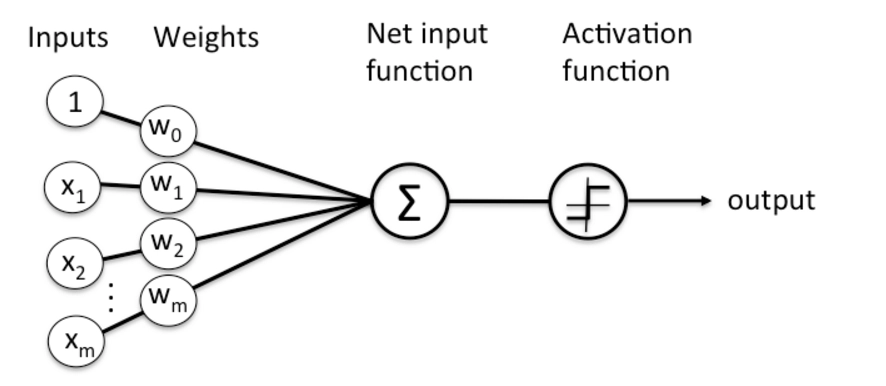
感知机是一种简单的人工神经网络,由Frank Rosenblatt于1957年提出。它是二分类线性分类器的基础,并开启了神经网络的研究。
# 感知机算法示例
def perceptron(training_data, iterations):
weights = [0] * len(training_data[0][0])
for _ in range(iterations):
for inputs, label in training_data:
prediction = int(dot_product(inputs, weights) > 0)
update = label - prediction
weights = [w + update * x for w, x in zip(weights, inputs)]
return weights
# 输出: 最终学习到的权重

决策树的构建可以使用许多现成的库,如Scikit-learn。
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
# 加载数据
iris = load_iris()
X, y = iris.data, iris.target
# 创建决策树分类器
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(X, y)
# 预测新数据
prediction = clf.predict([[5.1, 3.5, 1.4, 0.2]])
# 输出: 预测类别
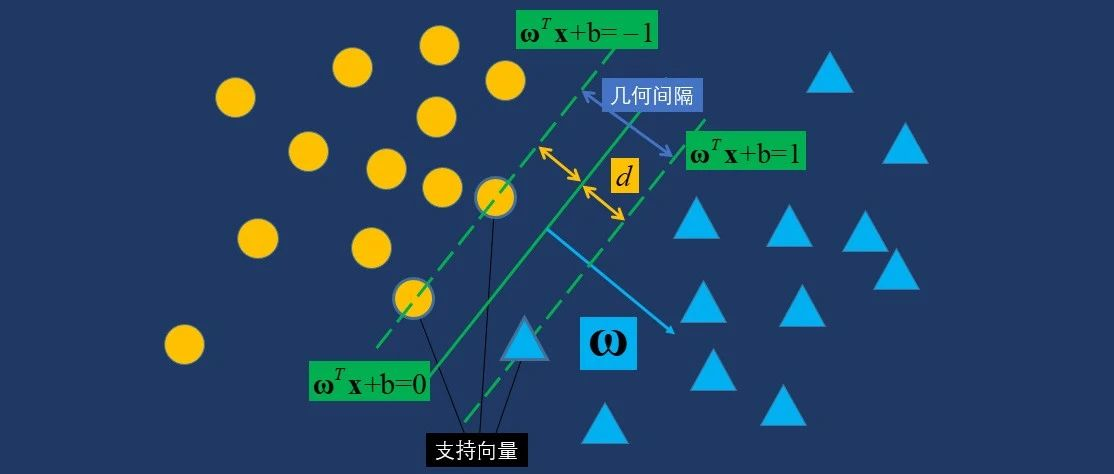
支持向量机的实现也可以使用Scikit-learn库。
from sklearn import svm
# 创建SVM分类器
clf = svm.SVC()
# 训练SVM分类器
clf.fit(X, y)
# 预测新数据
prediction = clf.predict([[5.1, 3.5, 1.4, 0.2]])
# 输出: 预测类别
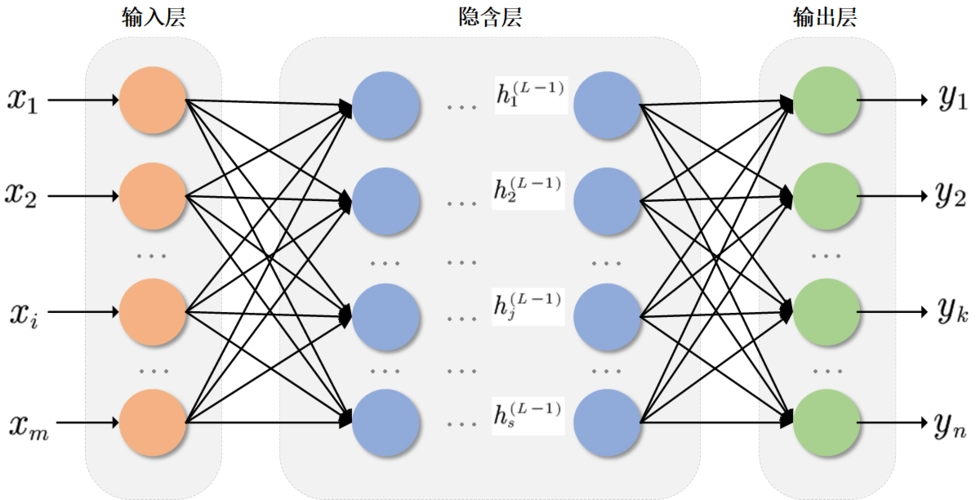
在Python中,可以使用库如TensorFlow或PyTorch来实现神经网络。以下是一个简单的多层感知机(MLP)示例:
import tensorflow as tf
# 定义模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(4,)),
tf.keras.layers.Dense(3, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(X, y, epochs=10)
# 预测新数据
prediction = model.predict([[5.1, 3.5, 1.4, 0.2]])
# 输出: 预测概率
这些代码段提供了早期机器学习算法的基本实现,并使用现代工具库进行了演示。
进入21世纪,随着计算能力的大幅提升和大数据的兴起,机器学习得到了空前的发展。这一时期出现了许多现代机器学习方法,如随机森林、深度学习、XGBoost等。
21世纪初期,集成学习方法得到了广泛的关注和研究,其中随机森林和XGBoost成为了该领域的代表算法。
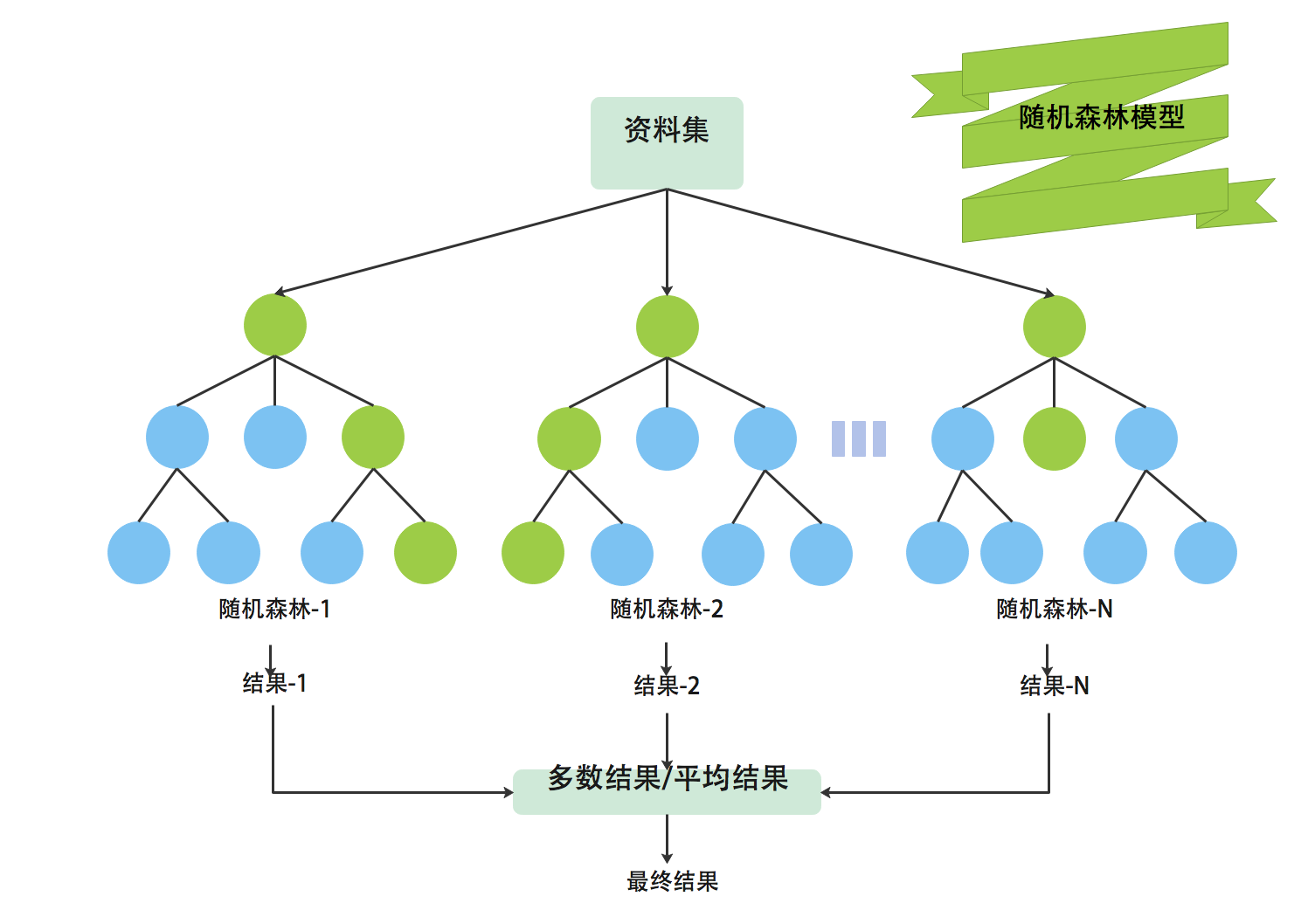
随机森林是一种集成学习方法,通过构建多个决策树并集成其结果,提供了较高的准确率和鲁棒性。
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器
clf = RandomForestClassifier()
# 训练模型
clf.fit(X, y)
# 预测新数据
prediction = clf.predict([[5.1, 3.5, 1.4, 0.2]])
# 输出: 预测类别

XGBoost是一种梯度提升树算法,因其高效和可扩展性而受到欢迎。
import xgboost as xgb
# 创建XGBoost分类器
clf = xgb.XGBClassifier()
# 训练模型
clf.fit(X, y)
# 预测新数据
prediction = clf.predict([[5.1, 3.5, 1.4, 0.2]])
# 输出: 预测类别
深度学习成为了21世纪初期的一项重要技术,特别是在图像识别、语音处理和自然语言理解等领域取得了重大突破。
卷积神经网络(CNN)特别适用于图像分类和分析任务。
from tensorflow.keras import layers, models
# 构建CNN模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(10, activation='softmax'))
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs=5)
# 输出: 训练准确率
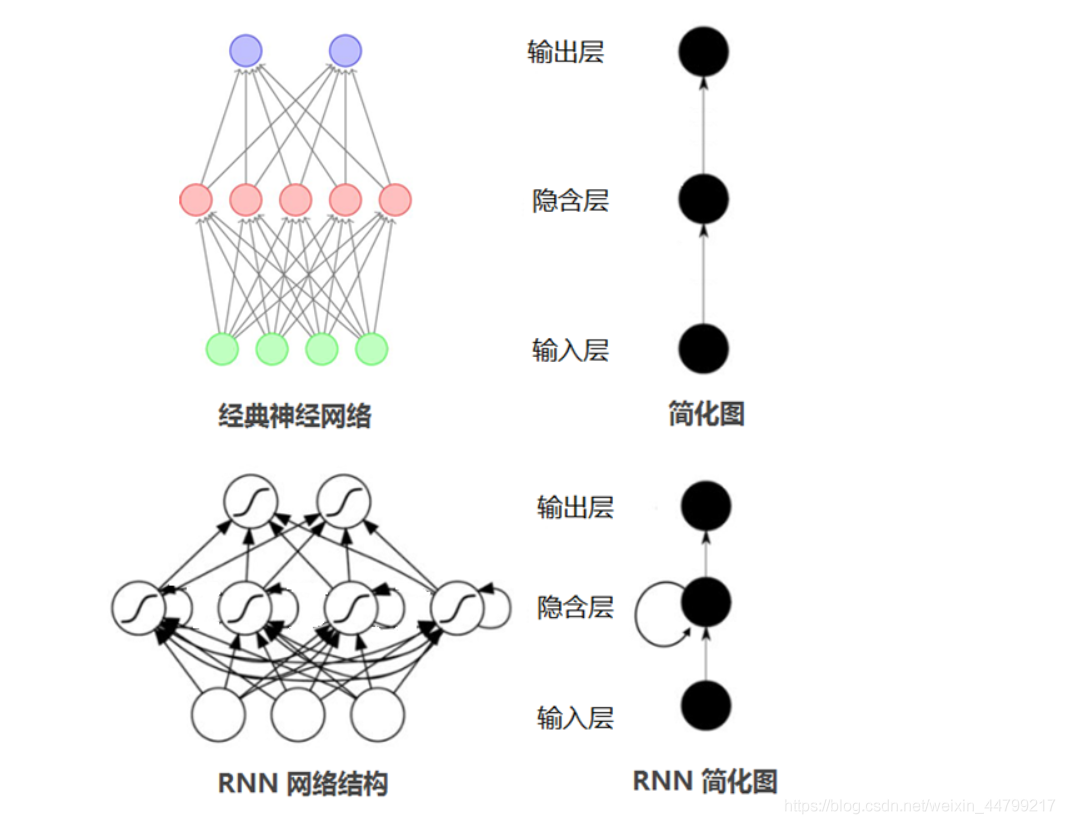
循环神经网络(RNN)在处理序列数据,如时间序列分析和语音识别等方面具有优势。
from tensorflow.keras import layers
# 构建RNN模型
model = tf.keras.Sequential([
layers.SimpleRNN(64, input_shape=(None, 28)),
layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs=5)
# 输出: 训练准确率
21世纪初期的发展将机器学习推向了新的高度。通过集成学习方法的进一步发展和深度学习的崛起,机器学习技术在许多领域实现了前所未有的突破。
当代机器学习的发展迅速,涉及的领域和应用范围不断扩大,具体可以概括为以下几个方面。
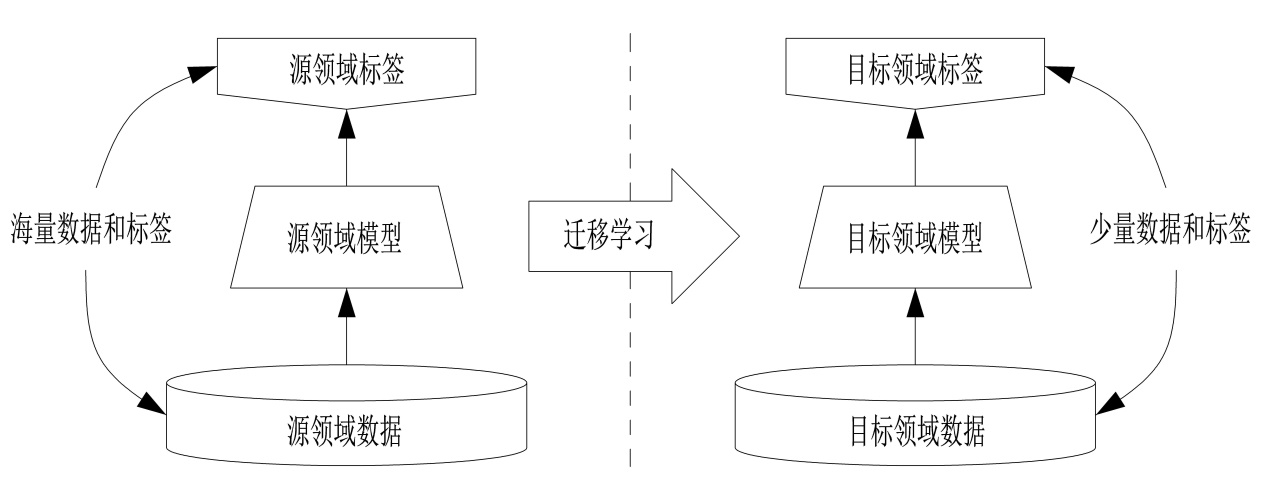
迁移学习是一种通过借用预先训练的模型参数来提高学习效率和性能的方法,特别受到深度学习社区的欢迎。
Fine-Tuning技术允许开发者在预训练的神经网络上进行微调,以适应特定任务。
from tensorflow.keras.applications import VGG16
# 加载预训练的VGG16模型
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 添加自定义层
model = tf.keras.Sequential([
base_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 冻结预训练层
base_model.trainable = False
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs=5)
# 输出: 训练准确率
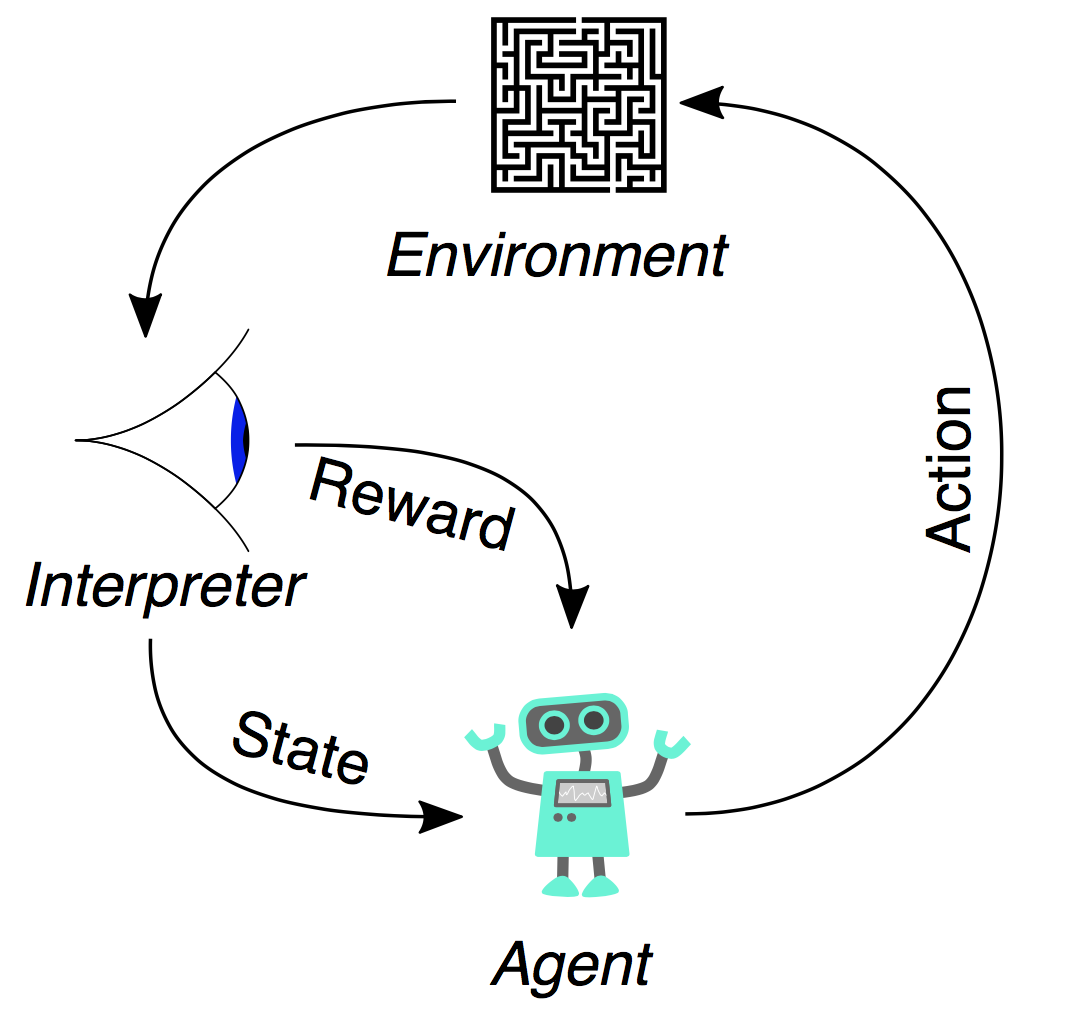
强化学习是一种使代理能够在与环境的互动中学习如何实现某些目标的方法。这在许多应用领域,如自动驾驶和游戏等方面表现出强大的潜力。
Q-Learning是一种强化学习算法,可用于许多不同类型的问题。
import numpy as np
# Q表初始化
Q = np.zeros((state_space, action_space))
# Q-Learning过程
for episode in range(episodes):
state = env.reset()
done = False
while not done:
action = np.argmax(Q[state, :] + np.random.randn(1, action_space) * (1.0 / (episode + 1)))
next_state, reward, done, _ = env.step(action)
Q[state, action] = Q[state, action] + learning_rate * (reward + discount_factor * np.max(Q[next_state, :]) - Q[state, action])
state = next_state
# 输出: Q表,表示学习到的策略
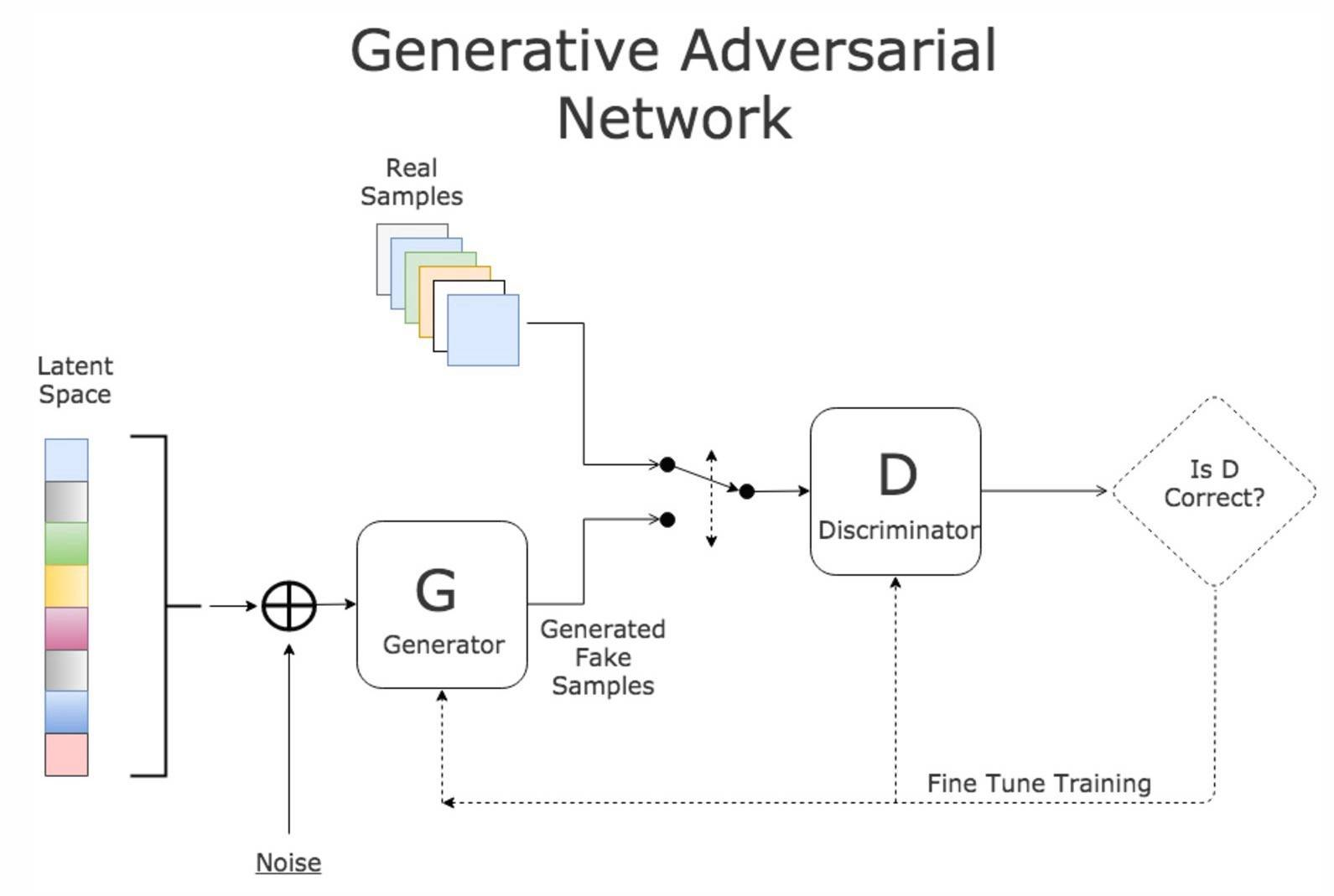
生成对抗网络(GANs)是一种可以生成与真实数据相似的新数据的神经网络。
以下是一个简单的GAN的构建示例。
from tensorflow.keras.layers import Dense, Flatten, Reshape
# 生成器
generator = tf.keras.Sequential([
Dense(128, activation='relu', input_shape=(noise_dim,)),
Dense(784, activation='sigmoid'),
Reshape((28, 28))
])
# 判别器
discriminator = tf.keras.Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(1, activation='sigmoid')
])
# GAN模型
gan = tf.keras.Sequential([generator, discriminator])
# 编译模型
discriminator.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
discriminator.trainable = False
gan.compile(optimizer='adam', loss='binary_crossentropy')
# 训练GAN
# 输出: 生成的图像示例
当代机器学习包括了一系列先进和强大的方法和框架,不仅增强了现有应用的功能和效率,还促使新的应用领域的出现。
随着科技的进步和研究的不断深入,机器学习正快速推动着众多领域的创新和变革。从目前的趋势来看,机器学习的未来充满机遇和挑战。以下几个方面可能是未来机器学习发展的主要方向。
虽然深度学习模型在许多任务上表现出色,但它们的“黑盒”性质常常使得模型的决策难以解释。未来的研究可能会集中在开发可解释的模型上,以增加人们对模型决策的理解和信任。
目前的机器学习模型通常缺乏对世界基本常识的理解。未来可能会有更多的研究集中在如何将常识融入机器学习模型中,使其能够进行更为合理和人性化的推理。
虽然现代机器学习模型在大数据集上训练可以达到令人印象深刻的性能,但在低资源环境下,其性能可能会大大下降。未来的研究可能会专注于开发能够在少量数据上有效学习的算法。
随着机器学习的广泛应用,伦理和隐私问题也日益凸显。未来可能会有更多的研究致力于确保机器学习的发展符合伦理准则,并且充分保护个人隐私。
机器学习与其他学科如生物学、物理学、医学等的交叉可能将带来新的突破。未来的研究可能会更加强调这些学科之间的整合,推动新技术和新应用的出现。
机器学习的未来展望是令人兴奋和富有挑战的。它不仅将继续推动技术的边界,还可能重塑许多传统领域的工作方式和思维方式。
机器学习作为人工智能的关键部分,在过去的几十年中取得了显著的进展。从最初的简单算法,到复杂的深度学习模型,再到当前的跨学科整合和伦理考虑,机器学习不断推动科技的前沿,影响着我们的生活方式和工作方式。
从本文的梳理可以看出,机器学习的发展是多元化和跨学科的。其演变不仅涉及算法和数学基础的革新,还与硬件、软件、数据可用性等众多方面紧密相连。
机器学习已经渗透到许多领域,从消费电子产品到先进的科研项目。然而,这一领域的潜力远未被完全挖掘。随着计算能力的增长、数据的积累和算法的不断创新,机器学习将继续拓宽其在科技和社会中的影响范围。
在这个快速发展的时代,我们作为研究者、开发者和消费者,都应认识到机器学习不仅是一项技术,更是一种思维方式和解决问题的工具。它促使我们更加深入地了解自然和人类行为的复杂性,并为我们提供了前所未有的分析和预测能力。
最后,不可忽视的是,随着机器学习的广泛应用,我们也需要认真考虑其潜在的伦理和社会影响。确保技术的发展符合人类价值观和利益,将是所有参与者共同的责任和挑战。
总的来说,机器学习代表了人类对智能和自动化的追求,它的未来充满希望,但也充满挑战。借助合适的工具和方法,加上对社会和人类需求的深刻理解,我们有望在这一领域继续取得重大突破,开创更智能、更可持续的未来。
如有帮助,请多关注
个人微信公众号:【TechLead】分享AI与云服务研发的全维度知识,谈谈我作为TechLead对技术的独特洞察。
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。