时间序列数据是数据分析中经常遇到的类型,为了更多的挖掘出数据内部的信息,
我们常常依据原始数据中的时间周期,将其转换成不同跨度的周期,
然后再看数据是否会在新的周期上产生新的特性。
下面以模拟的K线数据为例,演示如何使用pandas来进行周期转换。
首先创建测试数据,下面创建一天的K线数据,数据的间隔为1分钟(1min)。
import pandas as pd
import numpy as np
# 创建时间序列的列,时间间隔1分钟
date_col = pd.date_range("2024-01-01", "2024-01-02", freq="1min")
data_len = len(date_col)
# 模拟的K线数据
df = pd.DataFrame(
np.random.randint(1, 10, size=(data_len, 5)),
columns=["open", "close", "high", "low", "volumn"],
)
df.insert(0, "begin_time", date_col)
df
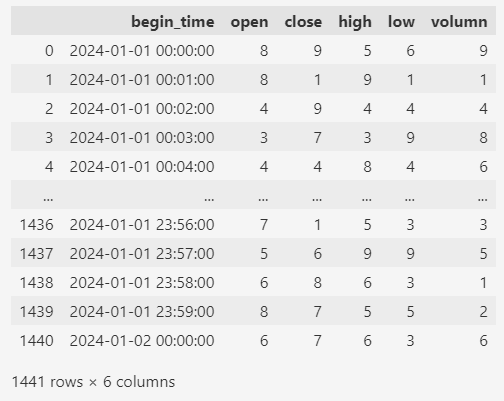
其中各个字段的含义:open(开盘价),close(收盘价),high(最高价),low(最低价),volumn(成交量)。
如果有股票或者类似交易的朋友都知道,K线的时间间隔是不固定的,不一定像上面的测试数据那样间隔1分钟,
一般根据自己的买卖频率会查看不同时间间隔的K线。
但是采集数据时,一般不会去采集各种时间间隔的K线,我们可以根据1分钟的K线,去转换其他不同时间间隔的K线。
转换的方法,就是使用pandas的resample函数。
通过resample周期转换其实就是以一定的周期对数据进行groupby,所以,resample也像groupby一样,需要对新周期中的数据进行聚合。
比如,下面的数据我们将1分钟的K线转换为5分钟的K线。
df.resample("5min", on="begin_time").agg({
"open": "first",
"close": "last",
"high": "max",
"low": "min",
"volumn": "sum",
})
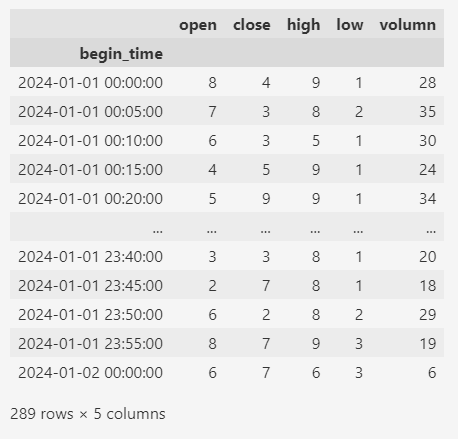
比如,原始数据每5个聚合成一个。
以前5个数据(2024-01-01 00:00:00~2024-01-01 00:04:00)为例。
open取第一个值,close取最后一个值,high取最大值,low取最小值,volumn取合计值。
除了上面的5分钟的数据,通过resample还可以聚合15分钟的K线,1小时,4小时等等各种时间间隔的K线。
方法类似,这里不再一一赘述。
对于完整的数据,就像上面那样转换即可,然而实际情况下的数据,部分缺失的情况是很常见的,
特别是上面的1分钟K线数据,极有可能1分钟没有交易,出现缺失的情况,有可能连续5分钟都没有数据。
下面看看数据缺失时,resample转换的情况。
先从上面的测试数据中取20个再进行一些删减,构造数据缺失的情况:
df_ = df.copy()
df_ = df_.iloc[:20]
df_ = df_.drop([3, 5, 6, 7, 8, 9, 10, 15, 16])
df_ = df_.reset_index(drop=True)
df_
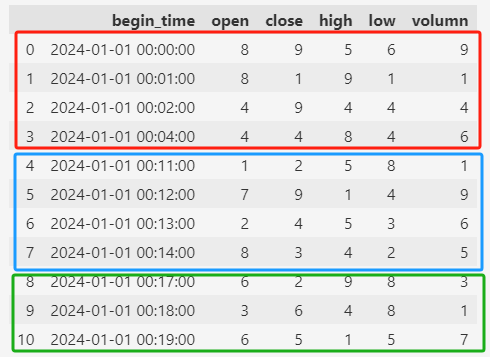
每组都有一些缺失,其中(2024-01-01 00:06:00~2024-01-01 00:10:00)整个5分钟的数据都缺失了。
此时,再按照5分钟间隔来resample,得到:
df_.resample("5min", on="begin_time").agg({
"open": "first",
"close": "last",
"high": "max",
"low": "min",
"volumn": "sum",
})
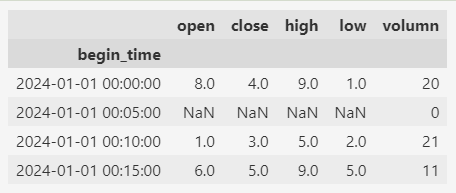
从中可以得出两个结论:
2024-01-01 00:05:00这条时间序列数据的分析过程中,周期转换是一个很常用的操作。
不过,不是简单的用resample来转换就完事了,
周期转换之后也会带来新的问题,比如上面示例中由于转换形成的空值,
这些空值是要直接丢弃?还是要插值?
如果要插值的话,是用基准数据来填充?还是用平均值?用移动平均值?用中位数?等等来插值,
这些都需要根据具体的分析场景和使用的分析算法来进一步讨论。
本文主要介绍使用resample来转换数据,而关于插值方法的详细讨论将另文阐述。