本文将通过展示 NodeJS 应用里环境变量的提取过程,来一窥 DevOps 技术是如何应用在现在云平台上的运维工作中的。同时我也想让大家在这里看到 DevOps 的另外一面,即它并非全能,从本地开发到持续部署再到实际运行,有一些运维鸿沟依然还未被填平。“人工操作”依然是工作中的最大风险。
实战系列来自于个人开发以及运维 site2share 网站过程中的经验
有一件事我想我们都会同意,那就是不应该在代码中硬编码(hard code)环境变量,比如生产环境数据库的用户名和密码。之所以称之为环境变量,是因为这些变量是依据你代码部署的环境而定的,例如生产环境和本地环境数据库用户名和密码就多半不会相同。下面就是一段使用 sequelize 连接数据库的代码的反例,其中硬编码了用户名和密码:
const connectionCfg = {
username: "admin",
password: "!password",
database: "order_db",
dialect: "mysql",
}
new Sequelize(connectionCfg);
将环境变量硬编码在代码中会产生几个问题:
所有我们应该利用 process.env 或者是 dotenv 工具,来将环境变量独立管理,让代码与环境解耦。
思路我们有了,本地开发的时候如果你使用了 dotnev,它默认会读取 .env 里的内容作为环境变量。但是当考虑到下一步我们把应用部署到生产环节时,你要面临的问题就是如何在你的云服务商环境上管理你的环境变量了。
这取决于你选择云服务解决方案。以 site2share 为例,因为我选择将它部署在 Azure App Service(App Service 简单来说是一个托管性质的服务部署平台,我可以快速部署代码而不用去维护背后的运行环境,并且它还提供了诸如监控、灰度部署等常用功能) 上,所以我可以直接使用 App Service 为我准备的环境变量解决方案。我只需要在我环境的 UI 界面上填写我的环境变量即可:
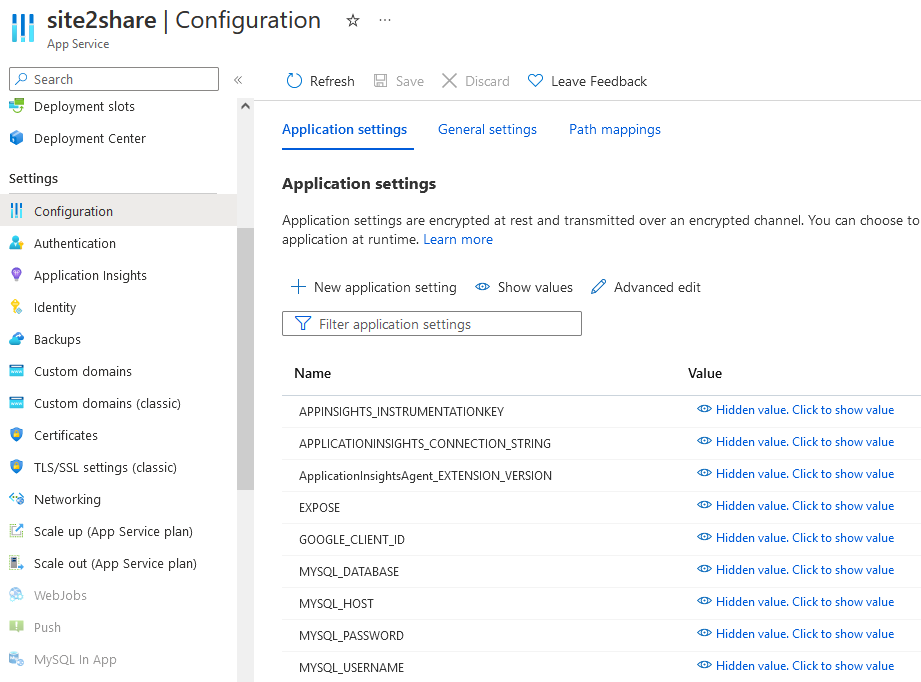
基本上目前主流云服务厂商提供的完全托管服务(full managed service)都提供类似的机制,下面是 Digital Ocean 的 App Platform 方案提供的环境变量管理界面:

到这里看似完美了——这样会带来一个风险:它并非是 IaC(Infrastructure as Code) 的。
什么是 IaC 我在这里举个例子,例如每次代码提交之后都会触发流水线运行测试,这里我把“需要运行测试”这件事记录在一个 yaml 文件里并且提交:
- script: |
npm run test
displayName: 'npm test'
这样将来无论是我自己回忆,还是新同学加入,都可以通过阅读这个文件判断流水线干了什么。如果有一天测试不小心被删掉了,也能追溯为什么被删以及被谁删掉的
非 IaC 的风险在于,如果你将来本地开发时新增了环境变量 REDIS_HOST,你需要保证云平台上的每个环境也需要新增 REDIS_HOST 变量(反过来说不用的环境变量也应该删除来避免将来给维护人员带来疑惑),然而这个步骤目前看来完全是依赖人工来完成的,因为云平台无法自动识别到你新增了变量
这里我们遇到了第一道鸿沟:开发环境与云平台的环境变量同步问题
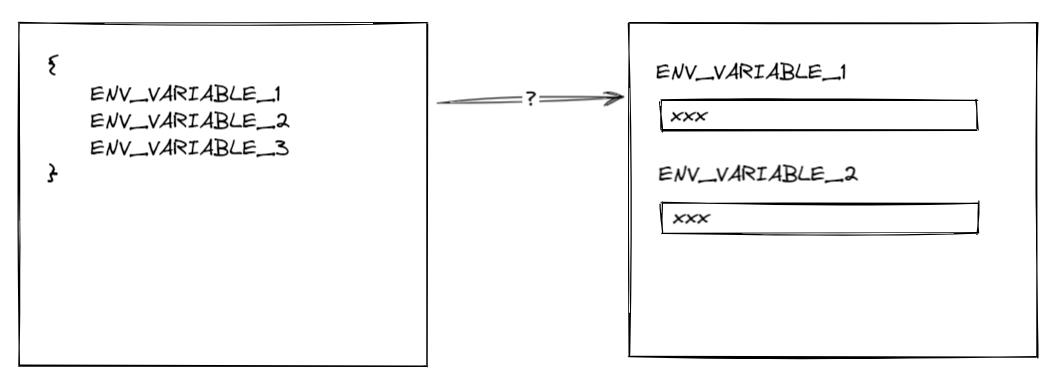
问题才刚刚开始
“人” 是DevOps 想要解决的问题之一,如果每次上线的成功都依赖自资深工程师的经验,那出错不过是早晚的事情而已。 把难的事情频繁做就是 CI(持续集成)/CD(持续交付) 的背后思想。
例如我们常常需要对数据库做变更,新增表或者列。把这类操作交给程序员手工去每个环境手工执行并非明智选择,我们应该把它交给持续交付的流水线去完成,这样会推动我们部署环境的标准化和自动化,减少风险。这一步骤我们将它命名为数据迁移( migration),我们看看 site2share 的数据迁移是如何做的。
因为我在代码中选择了 sequelize 作为数据库框架,所以理想情况是我只需要创建好数据迁移文件之后执行 sequelize 提供的命令工具即可:sequelize-cli db:migrate
第一个问题是:它怎么知道应该连接哪个数据库以及如何连接数据库?
sequelize 允许我们在目录添加一个名为 .sequelizerc 的配置文件来对 sequelize 进行配置,我们可以在其中设定数据库的连接字符串和数据迁移文件目录,比如
const path = require('path');
const migrationDir = path.join(__dirname, "migration");
require('dotenv').config();
module.exports = {
'config': path.join(migrationDir, 'config.js'),
'migrations-path': path.join(migrationDir, 'migrations'),
'seeders-path': path.join(migrationDir, 'seeders'),
};
其中 config.js 文件存储的就是数据库的连接配置,如用户名和密码:
第二个问题是:我们如何将用户名和密码等环境变量如第一小节所示抽取出来?config.js 允许我们访问 process.env.MYSQL_USERNAME,但 MYSQL_USERNAME 究竟应该如何让流水线知道呢?
site2share 使用 Azure DevOps 作为 CI/CD 工具。很遗憾 Azure DevOps 并没有如 App Service 那样提供一个最优解,一种解决思路是我可以使用 Azure KeyVault 服务用作密钥存储,在构建的时候读取;而我选择的是一种更为简单粗暴的方式:
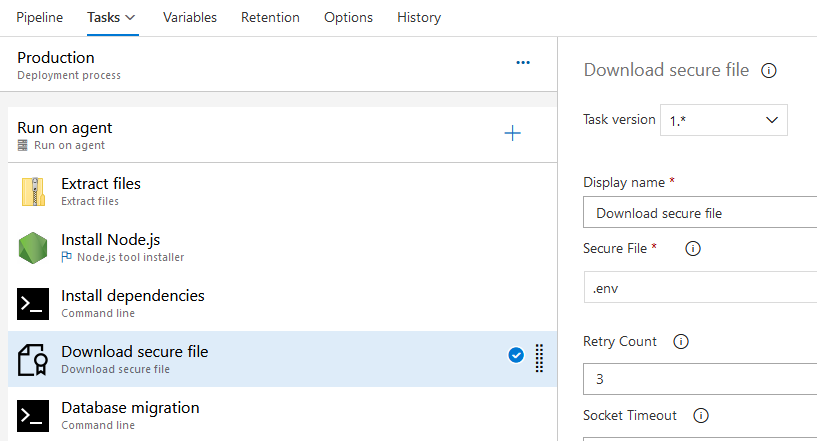
和在界面上编辑环境变量的行为类似,这种方法看上去同样不具有可持续性的。它依赖人的手工操作
所以在这里我们看到另一道鸿沟:环境变量从开发环境到流水线的同步问题
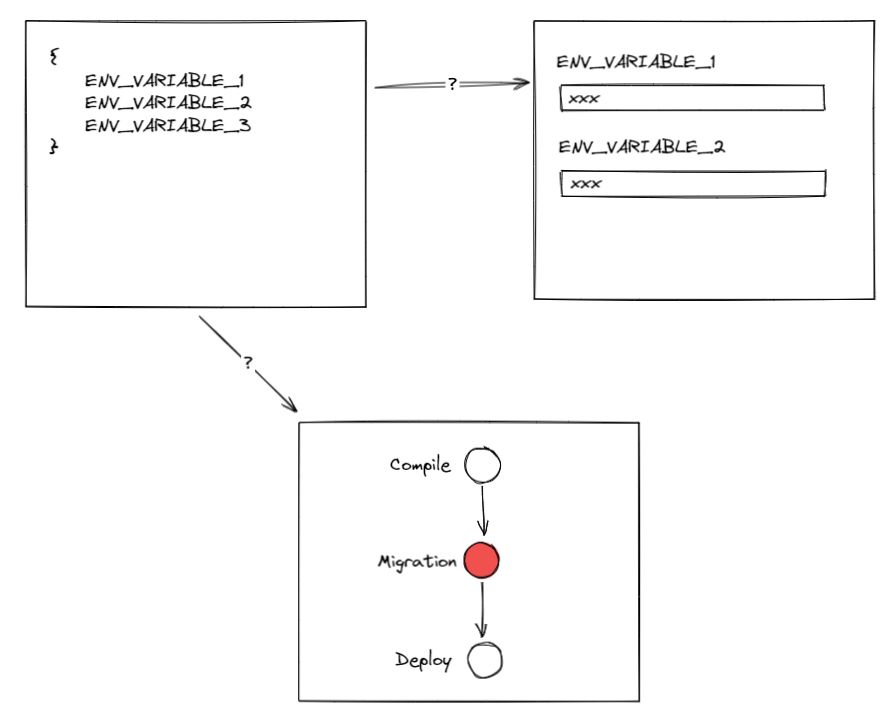
DevOps 话题很大我们这里暂且只看技术层面。我这里不是对 DevOps 批评,更不是对 Azure 的批评。这类问题在不同的平台都会存在,例如你如果使用阿里云效,他们甚至不允许你以 yaml 代码去编辑和保存流水线(IaC),但 IaC 也不是万能的,当你的 yaml 文件长达800行时基本等同于不可读时,它起到的效果等同于不存在。云平台本身的 vendor-lock 的问题也是原罪
在这里我们可以想象没有它们运维工作会比现在难上不知道多少倍——不能因为美中不足就否认它们给我们带来的帮助。
我们要接纳这样的一个现实:并不是所有的问题都可以用工具完美解决,“手工”暂且无法被彻底消灭。承认不完美的存在,尽所能把风险降到最小就好。
你可能也会喜欢: