Table of Contents
Meltdown Redux:Intel缺陷使黑客窃取了数百万台PC的秘密
黑客词典:什么是旁道攻击?
https://www.wired.com/story/what-is-side-channel-attack/
可以将侧通道攻击想像成数字窃贼,相当于窃贼用听诊器压在其前面板上来打开保险箱。
现代网络安全取决于在保守秘密的机器上。但是计算机,就像玩扑克的人一样,可以说。当他们有好手时,他们拍打他们的眼睛,或者在虚张声势时,或者至少在数字等同物时,抬起眉毛。学会学习那些意想不到的信号的黑客可以通过所谓的“侧通道攻击”来提取其中包含的秘密。
旁道攻击利用了计算机不断散发出来的信息消耗中的各种模式:例如,计算机监视器或硬盘驱动器产生的电辐射,其发散情况会有所不同,具体取决于穿过屏幕或由驱动器的磁性读取的信息头。或者计算机组件在执行某些过程时会消耗不同的电量这一事实。或者键盘的喀哒声可以仅通过声音显示用户的密码。
密歇根大学的计算机科学家,旁路攻击的主要研究者Daniel Genkin说:“通常,在设计算法时,我们会考虑输入和输出。我们不会考虑程序运行时会发生的其他事情。” 。“但是计算机不是在纸上运行的,它们是在物理上运行的。当您从纸张转向物理时,计算具有各种物理效果:时间,功率,声音。旁通道利用这些效果之一来获得更多信息并收集算法中的秘密。”
对于一个足够聪明的黑客来说,几乎可以收集任何偶然的信息泄漏来学习他们不应该知道的东西。随着时间的推移,计算变得越来越复杂,组件被推到了物理极限,并在各个方向抛出了意外的信息,侧信道攻击变得越来越丰富且难以预防。过去两年来,英特尔和AMD一直在努力修补一系列bug,例如Meltdown,Spectre,Fallout,RIDL或Zombieload,这些bug全都使用了旁道攻击作为其秘密窃取技术的一部分。
侧面通道攻击的最基本形式可以用防盗器打开,并用听诊器压在其前面板上来打开保险箱。小偷慢慢转动表盘,聆听可能会暗示保险柜齿轮内部功能并显示其组合的刺耳的声音或阻力。除了拨盘上的数字以及保险柜是否解锁和打开的是或否答案之外,保险柜并不意味着向用户提供任何反馈。但是保险柜的机械物理所产生的那些微小的触觉和听觉线索是一条旁道。安全cookie可以通过整理这些意外信息来学习组合。
“旁通道密码分析”一词最早出现在1998年,该论文发表在Counterpane Systems和加州大学伯克利分校的密码学家描述了如何使用旁通道攻击来破坏加密系统。但是更笼统的想法来得更早:最臭名昭著的计算机侧信道攻击之一是美国国家安全局所说的Tempest。1943年,贝尔实验室(Bell Labs)发现,每当有人键入电传打字机,附近的示波器的读数就会移动。贝尔实验室的研究人员很快意识到这是一个问题。电传打字机本来可以进行安全的加密通信,但是任何靠近阅读电磁辐射的人都可能破译其秘密。直到1985年,这种现象才在公开场合得到了充分的记录。当时,一位名叫Wim van Eck的计算机研究人员发表了一篇论文,该论文后来被称为“ Van Eck phreaking”,通过远程检测在计算机屏幕上重建图像。放电的电信号。
“计算机不是在纸上运行,而是在物理上运行。” --- 丹尼尔·根金(DANIEL GENKIN),密歇根大学
从那时起,类似的电磁泄漏攻击就得到了改进。就在2015年,特拉维夫大学的一组研究人员创建了一个售价300美元的小工具,可以装在一块皮塔饼上,并且可以通过捡拾附近的笔记本电脑的电力来获取附近笔记本电脑硬盘上的加密密钥。其他技术已经证明,声音,功率使用甚至通信中的时序模式都可以揭示计算机的秘密。特拉维夫大学的同一小组还发现,麦克风在执行解密时拾取计算机声音可以揭示其秘密密钥,发送到网络浏览器的加密数据突发中的模式可以揭示某人的Netflix或YouTube视频正在观看,无法访问他们的计算机。
本·古里安大学的安全研究员本·纳西指出,计算机不是旁道攻击的唯一目标。它们可以是任何会产生意想不到但有意义的信号的秘密过程或通信。Nassi指出了窃听方法,例如使用被入侵的智能手机中的陀螺仪的运动作为麦克风来拾取房间中的声音,或者使用一种称为“可视麦克风”的技术,该技术使用物体的远距离视频(例如一袋碎片或室内植物的叶子-观察振动,发现附近发生了谈话。
纳西本人以及本·古里安(Ben Gurion)的一组研究人员,上周揭示了一种技术,该技术可以通过使用望远镜观察室内悬挂的灯泡的振动来实时监听房间内的谈话。纳西说:“我将其称为副作用”,这种对旁道的更广泛定义超出了计算机甚至机器。“这是一种通过分析数字或物理过程的副作用来损害机密性的方法。”
而且,以计算机为中心的旁通道攻击只会变得更加复杂。例如,Spectre,Meltdown和其他一系列影响微处理器的“微体系结构”漏洞都利用了基于时间的边信道攻击。每种技术都使用不同的技术来诱使处理器临时访问机密信息,然后在处理器的缓存中对其进行编码,这是一部分内存,旨在使某些数据保持在手边,以提高效率。然后,通过迫使处理器在内存中搜索某些信息并测量芯片访问它的速度,黑客可以分析处理器响应的时间,并了解高速缓存中有哪些内容,而不是哪些内容,从而泄露了机密数据。(一些研究人员认为这是“隐性通道”,而不是侧通道,将Meltdown和Spectre描述为旁道攻击,并在其网站上将其描述为攻击者。)
像Spectre和Meltdown这样的攻击使像英特尔和其他计算机制造商这样的公司陷入了猫捉老鼠的游戏,追逐其产品的偶然信息泄漏,不断发布更新以隐藏暴露在侧通道攻击中的数据或用其他噪声填充使得解密变得更加困难。密歇根州的Genkin表示,随着计算机变得越来越复杂,并且如果计算机行业继续将性能置于安全之上,那么仍然会出现辅助渠道。在某些情况下,例如Spectre和Meltdown,研究人员甚至在挖掘已有多年历史的机制,并找出可用于秘密研究的秘密,至少对于任何可能破译计算机过程的意外副产品的人而言。
“他们总是在那里,” Genkin说。“您越来越多地了解它们的原因是,随着我们进一步挖掘,我们发现越来越多的可利用渠道。随着我们发现它们的严重程度,我们也在学习如何防御它们。”
Meltdown Redux:Intel缺陷使黑客窃取了数百万台PC的秘密
https://www.wired.com/story/intel-mds-attack-speculative-execution-buffer/
不止一个自安全研究人员披露Meltdown和Spectre以来已经过去了一年 ,这是英特尔和AMD出售的数百万芯片的深层,神秘功能中的一对缺陷,几乎使世界上每台计算机都处于危险之中。但是,即使芯片制造商争先恐后地修复这些漏洞,研究人员警告说,他们不是故事的结束,而是开始,他们代表的新阶级的安全漏洞是无疑会表面再次和再。现在,其中一些研究人员发现了英特尔微观硬件最深层的缺陷。这次,它可以使攻击者窃听受害者处理器接触的几乎所有原始数据。
今天,英特尔和一个由微体系结构安全研究人员组成的超级小组共同宣布了英特尔芯片中一种严重的新型可入侵漏洞。实际上,这是四种不同的攻击,尽管它们都使用类似的技术,并且都能够将潜在敏感数据流从计算机的CPU捕获到攻击者。
MDS攻击
研究人员来自奥地利的格拉茨大学(TU Graz),阿姆斯特丹的弗里耶大学(Vrije Universiteit),密歇根大学,阿德莱德大学,比利时的鲁汶大学,伍斯特工业学院,德国萨尔大学,以及安全公司Cyberus,BitDefender,Qihoo360和Oracle。这些组已命名了漏洞利用技术ZombieLoad,Fallout和RIDL或Rogue In-Flight Data Load的变体。英特尔本身更贴心地标记了新的一套攻击微体系结构数据采样或MDS。
英特尔已要求所有研究人员(他们分为两组独立工作)将他们的发现保密,有的超过一年,直到可以发布针对漏洞的修复程序为止。但同时,研究人员称,该公司一直在试图淡化这些漏洞的严重性,他们警告说,这些攻击是英特尔硬件的严重缺陷,甚至可能需要禁用其某些功能,甚至超出该公司的补丁程序。AMD和ARM芯片似乎不容易受到攻击,英特尔表示,过去一个月发布的某些型号的芯片已修复该问题。否则,早在2008年,研究人员测试过的所有英特尔芯片都会受到影响。
与Meltdown和Spectre一样,新的MDS攻击利用了Intel芯片执行推测性执行方式的安全漏洞,该功能是处理器提前猜测将要求其执行哪些操作和数据,以加快执行速度。芯片的性能。
在这些新情况下,研究人员发现,他们可以使用推测性执行来诱使Intel的处理器捕获从芯片的一个组件转移到另一个组件的敏感数据。与Meltdown不同,Meltdown使用推测性执行来捕获内存中的敏感数据,MDS攻击的重点是位于芯片组件之间(例如,处理器与其缓存之间)的缓冲区,分配给处理器的一小部分内存用于保持频繁访问数据近在咫尺。
阿姆斯特丹Vrije Universiteit大学VUSec研究小组的一名研究员Cristiano Giuffrida说:“这就像将CPU视为组件网络一样,我们基本上是在窃听它们之间的流量。” “我们听到了这些组件交换的任何信息。”
这意味着任何可以在目标芯片上运行程序的攻击者都可以欺骗—可以以恶意应用程序的形式,与目标位于同一台云服务器上的虚拟机,甚至是在目标浏览器中运行Javascript的流氓网站。 CPU泄露数据,该数据应受到保护,以免在该计算机上运行不受信任的代码。该数据可以包括诸如用户正在浏览的网站,其密码或用于解密其加密硬盘的秘密密钥之类的信息。
“从本质上讲,[MDS]在隔离安全域的墙壁上放了一块玻璃,使攻击者能够聆听CPU组件的冒泡声,”有关缺陷的VUSec论文的一行读到,该论文将于下周在IEEE上发表。安全和隐私研讨会。
“容易做并且可能造成破坏”
四种不同的MDS攻击变体都利用了英特尔芯片如何执行省时技巧的怪癖。在推测执行中,CPU经常在程序请求或猜测程序正在请求的数据之前跟随代码中的命令分支,以抢先一步。想想这个猜测,就像一个懒惰的服务员从他的盘子里随机提供一杯饮料,希望自己避免回到酒吧。如果CPU猜错了,它将立即将其丢弃。(在不同条件下,该芯片可以从三个不同的缓冲区中抓取数据,因此研究人员会遭受多次攻击。)
英特尔的芯片设计人员可能认为,即使是提供敏感数据的错误猜测也没关系。VUSec的Guiffrida说:“这将这些结果丢掉了。” “但是我们仍然有我们用来泄漏信息的漏洞窗口。”
就像Meltdown和Spectre一样,攻击者的代码可以通过处理器的缓存泄漏处理器从缓冲区中获取的数据。整个过程最多从CPU的缓冲区之一中窃取任意字节的任意数据。但是,要连续重复数百万次,攻击者就可以开始泄漏CPU实时访问的所有数据流。低特权攻击者还可以使用其他一些技巧,说服CPU请求将敏感数据(例如私钥和密码)拉入缓冲区,然后再由MDS攻击将其吸走。根据目标数据和CPU的活动情况,这些攻击可能需要数毫秒到数小时不等。VUSec研究人员Herbort Bos说:“这很容易做到,并且可能造成灾难性的后果。”

例如,VUSec创建了一个概念证明,如上所示,它可以从目标芯片的称为行填充缓冲区的组件中提取散列密码(通常可以被黑客破解的加密密码字符串)。TU Graz的以下视频显示了一个简单的演示,其中计算机上不受信任的程序可以确定某人访问了哪些网站。
[#video:https://www.youtube.com/embed/wQvgyChrk_g
在与WIRED的通话中,英特尔表示自己的研究人员是去年首次发现MDS漏洞的人,并且它现已发布了针对硬件和软件缺陷的修复程序。每当处理器越过安全边界时,用于攻击的软件修补程序就会从缓冲区清除所有数据,以防止数据被盗和泄漏。
英特尔表示,在大多数情况下,该补丁将具有“相对最小的”性能成本,尽管对于少数数据中心实例,该补丁可能会将其芯片速度降低多达8%或9%。要生效,该补丁将必须由每个操作系统,虚拟化供应商和其他软件制造商实施。
苹果表示,它是Mojave和Safari最新更新的一部分,发布了此修复程序。Google说,亚马逊也是如此。Mozilla表示很快就会有修复程序,Microsoft发言人表示将在今天发布安全更新以解决该问题。该公司的声明中写道:“我们已经意识到这个行业问题,并一直在与受影响的芯片制造商密切合作,以开发和测试缓解措施,以保护我们的客户。” “我们正在努力将缓解措施部署到云服务并发布安全更新,以保护Windows客户免受影响支持的硬件芯片的漏洞的影响。” VMware并未立即回复有关其修补状态的询问。
上个月开始发布的某些芯片中已经包含了一个更永久的硬件补丁,该补丁可以更直接地解决该问题,从而防止处理器在推测执行期间从缓冲区中提取数据。英特尔发言人在一份声明中说:“对于其他受影响的产品,可以通过微代码更新以及从今天开始可用的对操作系统和虚拟机管理程序软件的相应更新来进行缓解。”
然而,与此同时,研究人员和英特尔在问题的严重性以及如何进行分类方面存在分歧。TU Graz和VUSec都建议软件制造商禁用超线程,这是Intel芯片的一项功能,可通过允许并行执行更多任务来加快处理速度,但可能会使MDS攻击的某些变体容易得多。英特尔在与WIRED的电话中坚持认为,这些缺陷不能保证禁用该功能,这会对用户造成严重的性能损失。实际上,该公司对这四个漏洞的严重程度仅为“中低”,这是TU Graz和VUSec研究人员都提出的挑战。
例如,英特尔的工程师认为,尽管MDS漏洞可能泄漏机密,但它们也泄漏了计算机运行中的大量其他噪声。但是安全研究人员发现,他们可以可靠地挖掘原始输出以找到所需的有价值的信息。为了使过滤更容易,他们表明攻击者可以欺骗CPU反复泄漏相同的机密,从而有助于将其与周围的噪音区分开。
TU之一的迈克尔·施瓦兹(Michael Schwarz)表示:“如果我们要攻击硬盘加密,那么我们只会在将密钥加载到内存中的短时间内进行攻击,因此我们很有可能获得密钥和其他一些数据。”从事新的MDS攻击以及早期的Spectre和Meltdown发现的格拉茨研究人员。“某些数据将始终相同,其他数据将发生变化。我们看到最常发生的情况,这就是我们感兴趣的数据。这是基本统计信息。”
或者,正如VUSec的Bos所说:“我们从火水管中喝酒。如果您很聪明,并且仔细地处理了这些东西,就不会淹死,就可以得到所需的一切。”
轻描淡写
研究人员认为,所有这些都使英特尔对MDS攻击的严重性等级产生怀疑。格拉茨大学的研究人员(其中三人从事了Spectre和Meltdown攻击)对MDS攻击的评级大致介于这两个较早的漏洞之间,没有Meltdown严重,但比Spectre严重。(他们指出,英特尔对Spectre和Meltdown的评级也处于中等严重程度,这是他们当时不同意的判断。)
VUSec的Giuffrida指出,作为英特尔公司的“漏洞赏金”计划的一部分,英特尔为其工作团队支付了100,000美元,该奖赏用于奖励警告公司有关严重缺陷的研究人员。他指出,这几乎不是花在小事上的钱。但他还说,英特尔曾一度仅向VUSec提供了40,000美元的漏洞赏金,同时还提供了80,000美元的“礼物”,Giuffrida认为这是试图减少公开引用的赏金,从而降低了MDS漏洞的严重性。VUSec拒绝提供更多的总金额,以换取更能反映调查结果严重性的赏金,并威胁要退出漏洞赏金以示抗议。英特尔将报价改为全额100,000美元。
Giufrrida说:“很明显,英特尔在做什么。” “为了他们的利益,他们说:'不,在Spectre和Meltdown之后,我们并没有忽略其他漏洞;只是这些漏洞是如此之小,以至于它们溜走了。'”赏金的大小。
如此多的研究人员在同一时间窗口内发现MDS缺陷似乎很奇怪-至少两个由七个组织组成的独立团队,再加上英特尔本身,但TU Graz研究人员说这是可以预料的:Spectre和Meltdown的发现为黑客解锁了一个新的,非常复杂且尚未开发的攻击表面,该表面可能会在未来很长时间内在硬件中产生严重的基本安全漏洞。
TU Graz的莫里兹·利普(Moritz Lipp)说:“还有更多的组件,而且其中很多根本没有记录在案,因此持续一段时间不太可能。” 他的研究员丹尼尔·格鲁斯(Daniel Gruss)补充说:“我们一直希望这会使我们忙几年。” 换句话说,如果在未来几年内在计算机处理器的心脏中发现更多隐藏的漏洞,请不要感到惊讶。
三重熔毁:有多少研究人员同时发现了20年的芯片缺陷
https://www.wired.com/story/meltdown-spectre-bug-collision-intel-chip-flaw-discovery/
Meltdown和Spectre发现之间的奇妙巧合引发了有关“错误碰撞”以及NSA隐藏的漏洞集合的安全性的问题。
上个月初,星期日,在奥地利的小城市格拉茨,三名年轻的研究人员在家里的计算机前坐下来,试图破坏他们最基本的安全保护措施。
两天前,在格拉茨技术大学的实验室中,莫里茨·利普,丹尼尔·格鲁斯和迈克尔·施瓦茨决定挑逗一个已经困扰了他们数周的想法,这是保护者如何捍卫最敏感的保障措施中的一个松散话题。记忆数十亿台计算机。在星期六晚上与朋友喝酒后,他们第二天开始工作,每个人都独立编写代码以测试对可疑漏洞的理论攻击,并通过即时消息分享他们的进度。
那天晚上,格鲁斯告诉其他两位研究人员他成功了。他的代码旨在从计算机操作系统的最深层,最受保护的部分(称为内核)中窃取信息,不再散布随机字符,而是从机器敏感部分中窃取的真实数据:摘录自他的片段网络浏览历史记录,私人电子邮件对话中的文本。他不仅感到成就感,而且感到震惊和沮丧。
格鲁斯说:“这确实非常可怕。” “您不希望您的私人对话不会来自完全没有访问该数据权限的程序。”
Lipp和Schwarz在他们遍布城市的计算机上很快测试了他们自己编写的概念验证代码,并且可以看到相同的结果:Lipp记得看到数字化噪音造成的URL和文件名变成现实。他说:“突然之间,我看到了不该属于的弦。” “我想,'天哪,这确实有效。'”

格拉茨科技大学的研究人员(左起)DanielGrüss,Moritz Lipp和Michael Schwarz仅代表四个团队中的一个,他们彼此独立地在几个月内发现了处理器中相同的具有两个十年历史的关键安全漏洞。格拉茨工业大学
那天晚上,三位格拉茨研究人员的睡眠时间都没有超过几个小时。第二天,他们向英特尔发送了一条消息,警告他们芯片可能存在行业动摇缺陷。他们发现计算机提供的最基本的安全防御措施之一存在缺陷:它们将不受信任的程序与计算机上或计算机操作系统最深层(保留了最敏感的机密)的其他进程隔离开来。受到攻击后,任何可以在目标计算机上运行代码的黑客都可以破坏该低特权程序周围的隔离,以访问埋在计算机内核中的秘密,例如私有文件,密码或加密密钥。
在像Amazon Web Services这样的云计算服务上,多个虚拟机共存于同一台物理服务器中,一台恶意虚拟机可能会深入探究其邻居的秘密。格拉茨团队的发现(一种后来称为Meltdown的攻击)被证明是计算最基本的安全措施之一的关键漏洞。也许最令人不安的是,他们利用的功能是在1990年代中期引入英特尔芯片的。几十年来,在没有任何明显的公开发现的情况下,这种袭击仍然有可能发生。
然而,在沉默了一周之后,英特尔回应了三人的警告,该公司给了他们一个令人惊讶的响应。尽管英特尔确实在进行修复,但Graz团队并不是第一个向芯片巨头介绍该漏洞的人。实际上,另外两个研究团队也击败了他们。英特尔告诉研究人员,算上另一种将被称为Spectre的相关技术,他们实际上是在短短几个月内就第四次报告了新型攻击。
“据我所知这是一个疯狂的巧合,”著名安全研究人员保罗·科赫尔(Paul Kocher)说,他是向芯片制造商独立报告独特但相关的Spectre攻击的两个人之一。他补充说:“这两个线程没有共同点。” “没有理由没有人能在几年前而不是今天找到。”
四重碰撞
实际上,这么多不同的研究人员的奇异汇合发现了两个已有数十年历史的漏洞,这引发了一个问题,即还有谁可能在他们之前发现了这些攻击,以及谁可能秘密地使用了它们进行间谍活动,可能长达数年之久,在本周的启示和几乎所有急于遏制这一威胁的大型技术公司的软件修复程序泛滥之前。
安全研究人员和哈佛大学贝尔弗中心研究人员布鲁斯·施耐尔(Bruce Schneier)认为,这些处理器攻击发现的同步性不仅代表着孤立的谜,还代表了政策课:当国家安全局(NSA)等情报机构发现可黑客攻击的漏洞并秘密利用它们时,他们无法假设在安全行业称为“漏洞冲突”的其他黑客中,这些漏洞不会被其他黑客重新发现。
毕竟,Meltdown and Spectre事件并不是第一次同时发现主要错误。某种东西-甚至Schneier都承认不清楚-是什么导致世界上最好的安全研究人员做出几乎同时的发现,就像Leibniz和Newton在17世纪后期同时发明了微积分一样,五位不同的工程师在一个世纪之内就独立发明了电视。另一个在1920年代。
去年夏天与人合着了关于漏洞发现的论文的施奈尔说:“这很奇怪,对吧?就像水中有些东西一样。” “社区中发生了某种事情,它使人们思考,让我们在这里看看。然后他们这样做。而且肯定发生的频率比偶然的高。”
因此,当国家安全局发现所谓的“零日漏洞”(以前是未知的软件或硬件可破解漏洞)时,Schneier认为,重新发现的趋势需要考虑到该机构是偷偷利用该漏洞进行间谍活动,还是将其报告给任何机构。派对可以解决。Schneier认为像Spectre和Meltdown这样的bug冲突意味着它们应该在披露方面犯错误:根据他合着的哈佛研究中的粗略估计,在给定年份使用的所有零日中,可能有多达三分之一是第一次出现的。被美国国家安全局(NSA)发现。
施耐尔说:“如果我发现某个东西处于休眠状态10年,那么某个东西会让我发现它,而不仅仅是随机的东西也会让别人发现它。” “如果国家安全局发现了它,很可能是其他情报机构也发现了它,或者至少比随机机率更大。”
投机投机
虽然Meltdown和Spectre的四向错误碰撞的某些元素(可能是更好的描述)仍然难以解释,但一些研究人员也遵循相同的公开面包屑来进行发现。最著名的是,德国公司GData的恶意软件分析师安全研究员安德斯·福格(Anders Fogh)7月在他的博客中写道,他一直在探索现代微处理器的一种奇怪功能,即推测执行。由于渴望获得更快的性能,芯片制造商长期以来一直在设计处理器,以使其跳过代码的执行,从而乱码计算结果以节省时间,而不必等待过程中的某个瓶颈。
Fogh建议,乱序的灵活性可能允许恶意代码操纵处理器以访问芯片不应该访问的部分内存(例如内核),然后芯片才真正检查代码是否应获得许可。甚至在处理器意识到自己的错误并消除了非法访问的结果之后,恶意代码也可能再次诱使处理器检查其缓存,这是分配给处理器的一小部分内存,以使最近使用的数据易于访问。通过查看这些检查的时间,程序可以找到内核机密的痕迹。
由于其他研究人员现在所说的是他测试设置的怪癖,福格未能建立起有效的攻击。但是Fogh警告说,投机执行可能是未来安全研究的“潘多拉魔盒”。
尽管如此,Fogh的帖子几乎没有为更广泛的硬件安全研究界敲响警钟。仅仅几个月后,格拉茨工业大学的研究人员就开始仔细考虑他的警告。他们的第一个真实线索来自Linux内核邮件列表:10月,他们注意到来自主要公司(包括英特尔,亚马逊和Google)的开发人员突然对新型防御性操作系统KAISER产生了兴趣,格拉茨研究人员对此进行了重新设计已创建,目的是更好地将程序的内存与操作系统的内存隔离。
格拉茨研究人员曾打算让KAISER解决比Meltdown或Spectre严重得多的问题。他们的重点是隐藏计算机内存的位置以防恶意攻击,而不必阻止对其的访问。“我们感到高兴,”利普回忆道。“人们有兴趣部署我们的对策。”
但是,很快,邮件列表中的开发人员开始注意到,对于某些进程,KAISER补丁可能会使某些英特尔芯片的速度降低5%到30%,这比Graz研究人员发现的严重得多。然而,英特尔和其他科技巨头仍在努力解决问题。
利普回忆道:“这里一定有更大的东西。” 高科技公司是否正在使用KAISER修补一个更严重的芯片级秘密秘密?直到那时,他和其他格拉茨研究人员才回想起福格失败的投机性执行攻击。当他们决定自己尝试时,他们对Fogh的技术稍作调整的实现就感到震惊。
他们也不是一个人。就在几周前,德国安全公司Cyberus的研究员德累斯顿的托马斯·普雷舍(Thomas Prescher)偶然地终于可以测试福格的方法了。“我半年前已经看过它,发现这些想法非常有趣,但是在某个时候我只是忘了它。” 普雷歇尔说。“在十一月,我再次偶然遇到了它,只是决定尝试一下。我使它能够非常非常快地工作。”
最后,赛伯斯和格拉茨的研究人员在12月初相隔几天之内向英特尔报告了他们的工作。英特尔在当月中旬回应了每个研究人员的错误报告后,才得知有人在几个月前独立发现并报告了Meltdown攻击以及独特的推测性执行攻击Spectre。该警告来自零计划,这是Google的优秀漏洞搜寻黑客团队。实际上,零号项目研究员Jann Horn在6月,即安德斯·福格(Anders Fogh)博客文章发布的几周前就发现了这次袭击。
从零开始
霍恩如何独立地发现攻击英特尔芯片中的投机执行概念?如他所说,请阅读手册。
去年4月下旬,这位22岁的黑客(他在零号项目中的工作是他从大学就读的第一份工作)正在与同事一起在瑞士苏黎世工作,以编写一款处理器密集型软件。他们知道的行为将对英特尔芯片的性能非常敏感。因此,Horn深入研究了英特尔的文档,以了解英特尔处理器中有多少程序可能会无序运行以加快速度。
他很快就看到,在他正在处理的代码中,英特尔用来增强其芯片速度的推测性执行怪癖可能导致Horn所描述的“秘密”值被意外访问,然后存储在处理器的高速缓存中。霍恩在写给《有线》杂志的一封电子邮件中写道:“换句话说,[它将]使攻击者有可能找出秘密。” “然后我意识到,至少在理论上,这不仅会影响我们正在研究的代码片段,而且还决定对其进行研究。”
到五月初,霍恩已经将该技术发展为后来被称为“幽灵”的攻击。与Meltdown更直接地滥用处理器不同,Spectre利用推测性执行来欺骗计算机上无辜的程序或系统进程,以将其秘密植入处理器的缓存中,然后将其泄露给黑客,以进行类似于Meltdown的定时攻击。例如,可以操纵Web浏览器以泄露用户的浏览历史记录或密码。
幽灵对于攻击者来说比Meltdown更难利用,但修复起来也要复杂得多。它不仅适用于英特尔芯片,而且也适用于ARM和AMD芯片,这对业界来说是一个更加棘手且长期的问题。Horn在6月1日向芯片制造商报告了他的发现。随着他继续探索投机执行的其他可能性,他在三周后发现并向Intel报告了Meltdown攻击。
最后,在Meltdown和Spectre周围的bug冲突风暴中还会有另一个巧合。就在霍恩开始测试他的攻击时,保罗·科彻(Paul Kocher)开始从他创立的旧金山公司Cryptography Research休假。他希望部分时间来探索他在计算机安全性方面遇到的一个广泛问题:越来越不顾一切的驱动力,不惜一切代价(包括其基本安全性的代价)从微芯片中挤出越来越大的性能。
在去年9月于台北举行的加密和硬件会议上,科赫(Kocher)的前同事迈克·汉堡(Mike Hamburg)提出了关于投机执行的怀疑。Kocher立即下定决心要证明这个问题。Kocher说:“这并不是'aha'时刻而是'eww'时刻,”导致他采用相同攻击方法的认识。“当我开始考虑投机执行时,作为安全人员,对于我来说很清楚这是一个非常糟糕的主意。”
从台北回来后不久,科赫(Kocher)编写了自己的工作漏洞利用程序,却不知道Google的霍恩(Horn)在几个月前也发现了同样的几十年历史。
离群值或轶事?
对于Kocher来说,关键问题不是大约有多少研究人员在大约同一时间偶然发现了同一类攻击。它的攻击仍然未被发现怎么这么长时间,或者他们是否是实际上发现,和使用秘密破解不知情的对象。
“如果你问我几年前情报机构是否发现,我肯定会猜到,”科赫说。“他们在这类事情上尽了世界上最大的努力。他们很可能会注意到。而且如果他们发现了类似的东西,只要它能产生良好的情报,他们就不会告诉任何人。”
他补充说:“不仅限于国家安全局。” 其他由国家资助的黑客可能也有技能,并且有时间,也有可能发现了Spectre和Meltdown攻击。
周五,白宫网络安全协调员,前国家安全局高级官员罗伯·乔伊斯(Rob Joyce)告诉《华盛顿邮报》,国家安全局不了解Spectre和Meltdown,也从未利用过这些漏洞。乔伊斯还大肆宣传此举,以进一步披露美国国家安全局披露其发现的漏洞的规则,该政策被称为“漏洞公平过程”。
尽管Spectre和Meltdown代表了关于臭虫重新发现的几乎不可思议的轶事证据,但尚不清楚这种现象已变得多么普遍。布鲁斯·施耐尔(Bruce Schneier)合着的《哈佛研究》研究了一大堆包含4300个漏洞的错误报告数据。在首次发现Android漏洞后的60天内,再次报告了14%的Android漏洞,而大约有13%的Chrome浏览器漏洞被报告。Schneier说:“考虑到原始数据,对于NSA而言,保持漏洞的危险远比您想象的要危险。”
但是,去年RAND公司发布的另一项研究调查了一个未具名的研究组织的错误,发现只有5.7%的概率可以在一年内再次发现并报告给定的错误-尽管该研究并未说明其他原因,发现秘密错误。
RAND研究的作者之一莉莉安·阿布隆(Lillian Ablon)认为,幽灵和崩溃的重新发现并不是一个广泛的信号,即发现所有bug的次数都是多次,但是计算机安全的趋势却突然将许多目光聚焦在一个狭窄的领域。她说:“在一个区域中可能存在bug冲突,但是我们不能大声说出bug冲突一直在发生。” “将会有一些代码库和错误类,而这些注意力都不会引起关注。”
保罗·科切尔(Paul Kocher)认为,真正的教训是,安全研究界不应遵循彼此的脚步,而应寻找并修复鲜为人知的代码中的错误。
Kocher说:“在我的整个职业生涯中,每当我看过某个地方,都没有安全人员在看,那儿就会发现令人讨厌和不愉快的东西。” “令我震惊的是,这些攻击是在很久以前才发现的。我一直苦苦挣扎并担心的问题是,类似的事情已经存在了十到十五年了?”
-
Meltdown和Spectre既复杂又毁灭性。这是它们的工作方式,以及它们如此危险的原因。
KAISER:从用户空间隐藏内核
https://lwn.net/Articles/738975/
由乔纳森·科比特
2017年11月15日
从一开始,Linux就将内核的内存映射到每个正在运行的进程的地址空间中。这样做有充分的性能理由,通常可以信任处理器的内存管理单元,以防止用户空间访问该内存。但是,最近,与该映射有关的一些更微妙的安全性问题浮出水面,从而导致了新补丁集的快速开发,该补丁集结束了x86架构的这一长期实践。
一些地址空间的历史
在32位系统上,正在运行的进程的地址空间布局专用于底部3GB(0x00000000至0xbfffffff)供用户空间使用,顶部1GB(0xc0000000至0xffffffff)专用于内核。每个进程在最低的3GB内存中都有自己的内存,而所有内核空间的映射都是相同的。在x86_64系统上,用户空间虚拟地址空间从零变为0x7fffffffffffff(低47位),而内核空间映射分散在0xffff880000000000以上的范围内。从某种意义上讲,尽管用户空间可以看到为内核保留的地址空间,但它实际上没有对该内存的访问权限。
过去,这种映射方案引起了问题。例如,在32位系统上,它将进程的地址空间的总大小限制为3GB。内核方面的问题可以说是更糟的,因为内核只能直接访问不到1GB的物理内存。使用比需要更多内存的内存需要实现复杂的“高内存”机制。32位系统永远不会擅长使用大量内存(对于20世纪的“大”值),但是将内核映射到用户空间会使情况变得更糟。
尽管如此,该机制仍然存在的原因很简单:摆脱它会使系统运行相当慢。在用户空间和内核空间之间切换时,保持内核永久映射就无需刷新处理器的转换后备缓冲区(TLB),并且它允许永远不刷新内核空间的TLB条目。出于以下几个原因,刷新TLB是一项昂贵的操作:必须转到页表以重新填充TLB带来的痛苦,但是执行刷新本身的动作非常缓慢,以至于它可能是成本的最大部分。
早在2003年,Ingo Molnar实施了一种不同的机制,即用户空间和内核空间各自具有完整的4GB地址空间,并且处理器将在每次上下文切换时在它们之间进行切换。“ 4G / 4G”机制为某些用户解决了问题,并由某些发行商装运,但是相关的性能成本确保了它永远不会进入主线内核。从那以后,没有人认真提出过将两个地址空间分开的提议。
重新考虑共享地址空间
在当代的64位系统上,共享地址空间并不像以前那样限制可以寻址的虚拟内存量,但是还有另一个与安全性有关的问题。强化系统的一项重要技术是内核地址空间布局随机化(KASLR),它在引导时将内核在虚拟地址空间中的放置随机化。通过拒绝攻击者知道内核在内存中的位置,KASLR使许多类型的攻击变得更加困难。只要内核的实际位置不会泄漏到用户空间,攻击者就会在黑暗中摸索。
问题在于该信息以多种方式泄漏。其中许多泄漏可追溯到内核地址不是敏感信息的较简单日子。甚至发现您的编辑器在2003年引入了这样的泄漏。当时没有人担心公开这些信息。最近,人们采取了共同的努力来阻止内核的直接泄漏,但是如果硬件本身揭示了内核的位置,那么这将不会有太大的好处。而这似乎正是正在发生的事情。
Daniel Gruss等人的论文。[PDF]引用了许多针对KASLR的基于硬件的攻击。他们使用诸如利用错误处理中的时序差异,观察预取指令的行为或使用Intel TSX(事务性存储器)指令强制执行错误之类的技术。有传言称存在其他此类渠道,但尚未公开。在所有这些情况下,处理器都会根据目标地址是否映射到页表中来对内存访问尝试做出不同的响应,而不管运行中的进程是否可以实际访问该位置。这些差异可用于查找内核的放置位置,而无需让内核意识到攻击正在进行中。
修复硬件中的信息泄漏很困难,并且无论如何,部署的系统很可能仍然容易受到攻击。但是,对于这些信息泄漏,有一个切实可行的防御措施:使得用户空间完全无法访问内核的页表。换句话说,为了强化系统,似乎需要终止将内核映射到用户空间的实践。
凯瑟
上面链接的论文为x86-64内核提供了单独的地址空间的实现;作者将其称为“ KAISER”,显然代表“内核地址隔离以有效去除边通道”。此实现不适合包含在主线中,但是Dave Hansen对其进行了挑选和大量修改。将得到的补丁集(仍然被称为“KAISER”)在其第三次修订,并似乎有可能找到自己的方式上游的时间相对较短。
当前系统的每个过程只有一组页表,而KAISER则实现两个。一组基本上没有变化;它既包含内核空间地址,又包含用户空间地址,但仅在系统以内核模式运行时才使用。第二个“影子”页面表包含所有用户空间映射的副本,但省略了内核方面。取而代之的是,只有极少数的内核空间映射集可以提供处理系统调用和中断所需的信息,但仅此而已。复制页表听起来效率低下,但是复制仅发生在页表层次结构的顶层,因此大部分数据在两个副本之间共享。
每当进程在用户模式下运行时,影子页表将处于活动状态。因此,内核地址空间的大部分将完全隐藏在进程中,从而克服了已知的基于硬件的攻击。每当系统需要切换到内核模式时,例如响应系统调用,异常或中断,都将切换到其他页表。然后,管理返回用户空间的代码必须再次使影子页表处于活动状态。
KAISER提供的防御还不完善,因为仍然必须存在少量内核信息才能管理切换回内核模式。在补丁说明中,Hansen写道:
最小内核页表尝试仅映射进入/退出内核所需的内容,例如进入/退出功能,中断描述符(IDT)和内核蹦床堆栈。这组最少的数据仍然可以显示内核的ASLR基址。但是,这些最少的内核数据都是可信任的,因此与包含用户控制数据的内核直接映射中的数据相比,利用起来更加困难。
尽管补丁没有提及它,但人们可以想象,如果剩下的信息的存在最终导致了游戏的遗失,那么它可能与内核的其余部分分别位于其自己的随机地址中。
当然,驱使使用一组页表的性能问题并没有消失。不过,最近的处理器以过程上下文标识符(PCID)的形式提供了一些帮助。这些标识符在TLB中标记条目;仅当关联的PCID与当时在处理器中运行的线程的PCID相匹配时,TLB中的查找才会成功。使用PCID无需在上下文切换时刷新TLB。这大大降低了系统调用期间切换页表的成本。令人高兴的是,内核在4.14开发周期中获得了对PCID的支持。
即使这样,使用KAISER时仍需支付性能罚款:
对于进行系统调用或中断的任何事物,KAISER都会影响性能:一切。只是新的指令(CR3操作)为系统调用或中断增加了几百个周期。我们运行的大多数工作负载都显示出一位数的回归。5%是通常情况下的整数。我们所看到的最糟糕的情况是,在进行了大量的系统调用和上下文切换的环回网络测试中,大约有30%的回归。
不久之前,甚至没有考虑过将具有这种性能损失的安全相关补丁纳入主线。但是,时代已经改变,大多数开发人员已经意识到,强化内核不再是可选的。即使这样,对于那些不愿受到性能影响的人,甚至在运行时,都将有启用或禁用KAISER的选项。
总而言之,KAISER具有补丁集的外观,该补丁集已投入快速使用。它几乎完全形成,并且立即引起了许多核心内核开发人员的关注。莱纳斯·托瓦尔兹(Linus Torvalds)显然支持这一想法,尽管他自然地指出了许多可以改进的地方。没有人公开谈论过合并该代码的时间框架,但是4.15可能并非完全没有问题。
迟到的Meltdown/Spectre分析
https://zhuanlan.zhihu.com/p/263081764
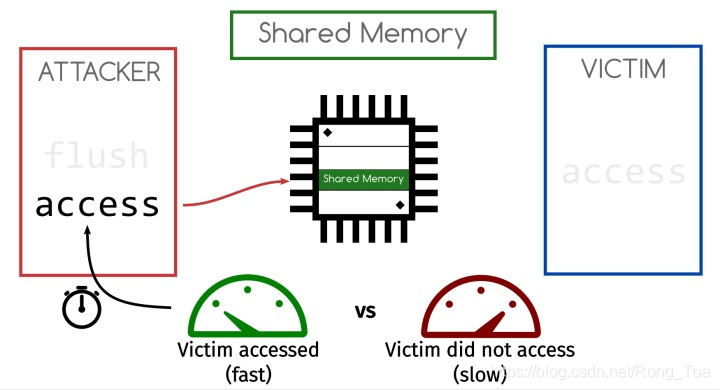
Meltdown/Spectre在2018年初闹得沸沸扬扬, 可以说是有史以来最有影响的cpu漏洞了. 当时有过简单了解, 但是不够深入, 这两天重新又看了一下.
背景知识
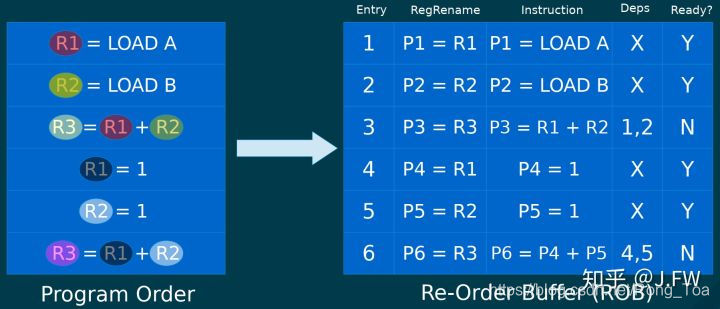
乱序执行
cpu的乱序执行一般都使用Tomasulo算法, x86也不例外, 主要包括:
- Common Data Bus (CDB).
- Unified Reservation Station (Scheduler).
- Register Renaming (Reorder Buffer).
该算法虽然是乱序执行, 但是会顺序完成 (retire), 只有在retire后它的输出才会architectually visible (简单地说, 不影响程序逻辑), 但是没有architectually visible不等于没有影响, 当输出更新到reservation station后, 因为cdb的存在, 其他指令已经可以读到. 另外, 非常重要的一点, 异常只有在指令retire的时候才会触发, 对于上面的例子, 即使cpu已经检查到第一条指令没有访问权限, 也只能等到该指令retire时才会触发, 取决于该指令在ROB的位置, 可能马上触发也可能很久之后, ROB容量可以很容易做到比如192这个级别.

这幅图可以对ROB有个大致了解:
旁路攻击
Meltdown/Spectre使用的都是旁路攻击(Side Channel Attack), 这里引用What Is a Side Channel Attack的描述:
Side channel attacks take advantage of patterns in the information exhaust that computers constantly give off: the electric emissions from a computer's monitor or hard drive, for instance, that emanate slightly differently depending on what information is crossing the screen or being read by the drive's magnetic head. Or the fact that computer components draw different amounts of power when carrying out certain processes. Or that a keyboard's click-clacking can reveal a user's password through sound alone.
旁道攻击利用了计算机不断散发出来的信息消耗中的各种模式:例如,计算机显示器或硬盘驱动器产生的电辐射会根据穿过屏幕或由驱动器的磁性读取的信息而有所不同。 头。 或者计算机组件在执行某些过程时会消耗不同的电量这一事实。 或者键盘的喀哒声可以仅通过声音显示用户的密码。
Meltdown/Spectre利用了旁路攻击的一种常见手段Flush+Reload, CPU访问DRAM和cache的时间有数量级差异, 所以通过衡量时间就可以判断出数据是否在cache里面.
- Attacker先通过Flush清空对应的cache line
- 触发Victim访问该数据
- Attacker会访问同一数据并测量访问时间
投机执行
投机执行(Speculative Execution)本质上是乱序执行的一种, 存在条件判断的时候, cpu如果预测该分支为true, 则投机执行里面的语句.

分支预测
Indirect branch
- Branch Target Buffer (BTB)
Indirect JMP and CALL instructions consult the indirect branch predictor to direct speculative execution to the most likely target of the branch. The indirect branch predictor is a relatively large hardware structure which cannot be easily managed by the operating system.
间接JMP和CALL指令查询间接分支预测器,以将推测性执行引导到最可能的分支目标。 间接分支预测器是一个相对较大的硬件结构,无法由操作系统轻松管理。
- Return Stack Buffer (RSB)
Prediction of RET instructions differs from JMP and CALL instructions because RET first relies on the Return Stack Buffer (RSB). In contrast to the indirect branch predictors RSB is a last-in-first-out (LIFO) stack where CALL instructions “push”entries and RET instructions “pop” entries. This mechanism is amenable to predictable software control.
RET指令的预测不同于JMP和CALL指令,因为RET首先依赖于返回堆栈缓冲区(RSB)。 与间接分支预测器相反,RSB是后进先出(LIFO)堆栈,其中CALL指令“推送”条目,而RET指令“ pop”条目。 此机制适用于可预测的软件控制。
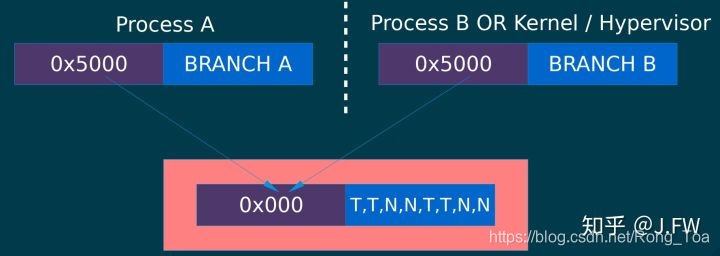
Train BTB
- BTB使用虚拟地址, 并且是截断的地址, 不需要和victim完全一样的地址
- SMT会共享同一个BTB, 即使不在同一个cpu[线程]上, 也可以train
Gadget
Spectre Attacks: Exploiting Speculative Execution
小工具
幽灵攻击:利用投机执行
Return-Oriented Programming (ROP) [63] is a technique that allows an attacker who hijacks control flow to make a victim perform complex operations by chaining together machine code snippets, called gadgets, found in the code of the vulnerable victim. More specifically, the attacker first finds usable gadgets in the victim binary. Each gadget performs some computation before executing a return instruction.
面向返回的编程(ROP)[63]是一种技术,该技术允许劫持控制流的攻击者通过将易受害受害者的代码中发现的称为小工具的机器代码片段链接在一起,使受害者执行复杂的操作。 更具体地说,攻击者首先在受害二进制文件中找到可用的小工具。 每个小工具在执行返回指令之前都要执行一些计算。
Meltdown and Spectre - Usenix LISA 2018
崩溃和幽灵-Usenix LISA 2018
A“gadget”is a piece of existing code in an (unmodified) existing program binary. For example code contained within the Linux kernel, or in another “victim” application
A malicious actor influences program control flow to cause gadget code to run
Gadget code performs some action of interest to the attacker
For example loading sensitive secrets from privileged memory
The code following the bounds check is known as a “gadget”
“小工具”是(未修改的)现有程序二进制文件中的一部分现有代码。 例如,Linux内核或另一个“受害者”应用程序中包含的代码
恶意行为者影响程序控制流以导致小工具代码运行
小工具代码执行攻击者感兴趣的某些操作
例如,从特权内存中加载敏感机密
边界检查之后的代码称为“小工具”
Meltdown
攻击方法
先看一个meltdown的示例程序, 普通权限用户通过它能够读出kernel space中0xffffffff81a000e0的内容, 以下是攻击者的代码:
- char data = *(char*) 0xffffffff81a000e0;
- array[data * 4096] = 0;
其中0xffffffff81a000e0是位于kernel space的地址, 选择这个位置是因为它里面是确定的值, 方便验证方法是否有效:
- # sudo grep linux_banner /proc/kallsyms
- ffffffff81a000e0 R linux_banner
按照正常的理解, 第一条语句访问内核地址会触发异常, 所以不能获得data值. Meltdown利用了以下因素:
- kernel space和user space在同一地址空间, 即使cpu会执行权限检查
- cpu乱序执行. 第一条语句确实[最终]会触发异常, 但是并没有阻止第二条语句的执行. 当然攻击者需要处理该异常信号, 否则代码不能继续执行, 信号处理函数的具体处理逻辑可以见下面提到的例子. 另外也可以使用别的手段, 比如放在投机执行的地方, 投机执行的指令导致的异常会被忽略
- 第二条语句通过旁路攻击的方法获得data的值. data取值只有256种可能, 通过访问array[]不同偏移的时长确定data的取值. 这里能够同时获取8bit数据, 也可以设计出获取其他长度数据的代码
举个例子
以这个为例: https://github.com/paboldin/meltdown-exploit, 里面主要逻辑如下:
- asm volatile (
- "1:\n\t"
- ".rept 300\n\t"
- "add $0x141, %%rax\n\t"
- ".endr\n\t"
- "movzx (%[addr]), %%eax\n\t"
- "shl $12, %%rax\n\t"
- "jz 1b\n\t"
- "movzx (%[target], %%rax, 1), %%rbx\n"
- "stopspeculate: \n\t"
- "nop\n\t"
- :
- : [target] "r" (target_array),
- [addr] "r" (addr)
- : "rax", "rbx"
- );

执行结果如下:
- cached = 31, uncached = 336, threshold 102
- read ffffffff8164e080 = 25 % (score=999/1000)
- read ffffffff8164e081 = 73 s (score=1000/1000)
- read ffffffff8164e082 = 20 (score=996/1000)
- read ffffffff8164e083 = 76 v (score=999/1000)
- read ffffffff8164e084 = 65 e (score=999/1000)
- read ffffffff8164e085 = 72 r (score=1000/1000)
- read ffffffff8164e086 = 73 s (score=999/1000)
- read ffffffff8164e087 = 69 i (score=1000/1000)
- read ffffffff8164e088 = 6f o (score=1000/1000)
- read ffffffff8164e089 = 6e n (score=999/1000)
- read ffffffff8164e08a = 20 (score=1000/1000)
- read ffffffff8164e08b = 25 % (score=1000/1000)
- read ffffffff8164e08c = 73 s (score=1000/1000)
- read ffffffff8164e08d = 20 (score=1000/1000)
- read ffffffff8164e08e = 29 ( (score=998/1000)
- read ffffffff8164e08f = 61 % (score=999/1000)
可以看到上面的score都非常高, 说明通过Flush+Reload是很有效的. 代码里面关键的几点:
- 8-11行是主要代码, 和论文里的例子几乎一样
- 10行的jz论文里提到: While CPUs generally stall if a value is not available during an out-of-order load operation [28], CPUs might continue with the out-of-order execution by assuming a value for the load.
- 4-6行. 似乎完全不相干, 即使删掉它们, 运行结果也完全一样!
继续来看4-6行的作用, 首先看到在上面的汇编代码执行之前, 执行了语句:
_mm_mfence();先把它删掉, 重新执行还是能够读出数据, 但是score很多已经到个位数了, 说明已经不能稳定读出数据了. 更进一步, 把其中rept的指令改成:
mov $0x141, %%rax此时已经完全不能读出数据了, 即使把mfence加回来也无济于事. 这是因为meltdown要攻击成功, 需要时间窗口, 越权访问那条指令必须在第二条指令加载数据到cache之后(or in flight?) retire, 否则触发异常从而会中断乱序执行. 从测试可以知道:
- mfence能很好地起到阻塞后面异常指令retire, 因为它很慢, 而且cpu是顺序retire的
- rept中add $0x141, %%rax一定程度也能起到阻塞的作用, 但是没有mfence稳定. 注意这条add指令会同时读写rax寄存器, 导致这300条指令前后形成read-after-write的依赖关系, 这样在执行的时候就会形成依赖关系, 从而导致ROB上指令的积压, 而mov $0x141 %%rax因为register renaming的原因并不会形成真实的依赖关系. (ROB的容量和入队速率, ALU执行单元个数, Reservation State的容量, 这些可以进行更细致的分析)
防御方法
Kernel Page Table Isolation (KPTI) 中user space对应的页表已经没有kernel space的内容, 这样就不能访问到kernel的数据了, 不管有没有乱序执行.
当前系统的每个过程只有一组页表,而KAISER则实现两个。一组基本上没有变化;它既包含内核空间地址,又包含用户空间地址,但是仅在系统以内核模式运行时才使用。第二个“影子”页面表包含所有用户空间映射的副本,但省略了内核方面。取而代之的是,只有极少数的内核空间映射集可以提供处理系统调用和中断所需的信息,但仅此而已。复制页表听起来效率低下,但是复制仅发生在页表层次结构的顶层,因此大部分数据在两个副本之间共享。
每当进程在用户模式下运行时,影子页表将处于活动状态。因此,内核的大部分地址空间将被进程完全隐藏,从而克服了已知的基于硬件的攻击。每当系统需要切换到内核模式时,例如响应系统调用,异常或中断,都将切换到其他页表。然后,管理返回用户空间的代码必须再次使影子页表处于活动状态。
Spectre V1
攻击方法
以下代码中即使if条件为false, cpu仍然可能先投机执行第二条语句, 从而访问到不应该访问的数据array1[x], 其中x >= array1_size, 所以这种攻击也称为Bounds Check Bypass.
- if (x < array1_size)
- y = array2[array1[x] * 4096];
上面是victim的代码, 为了完成攻击:
- attacker需要在victim中找到该段代码, 毫无疑问
- attacker需要能够控制变量x
- attacker需要能够访问array2, 否则没有side channel
- array2不在cache, 这是旁路攻击使用Flush+Reload的前提
- array1_size不在cache, 这样条件指令所需时间更长, 有利于投机执行; array1[x]在cache, 这样array2[array1[x] * 4096]才能尽早发出
一般来说要同时满足条件1,2,3并不容易, 但是eBPF可以比较容易构造, 毕竟可以自己写eBPF脚本.
防御方法
防御的思路是: 即使投机执行了错误路径也不会泄露信息, 这种方式比较简单:
- index < size. 正确性没有影响
- index >= size. array_index_nospec返回值范围在[0, size), 所以不会有越界访问
- /*
- * array_index_nospec - sanitize an array index after a bounds check
- *
- * For a code sequence like:
- *
- * if (index < size) {
- * index = array_index_nospec(index, size);
- * val = array[index];
- * }
- *
- * ...if the CPU speculates past the bounds check then
- * array_index_nospec() will clamp the index within the range of [0,
- * size).
- */
- #define array_index_nospec(index, size) \
- ({ \
- typeof(index) _i = (index); \
- typeof(size) _s = (size); \
- unsigned long _mask = array_index_mask_nospec(_i, _s); \
- \
- BUILD_BUG_ON(sizeof(_i) > sizeof(long)); \
- BUILD_BUG_ON(sizeof(_s) > sizeof(long)); \
- \
- (typeof(_i)) (_i & _mask); \
- })
Spectre V2
v1通过bypass bounds check, 可以在选择2条不同的执行路径, 而v2通过训练indirect branch, 理论上可以引诱cpu[错误路径]去执行任意gadget.
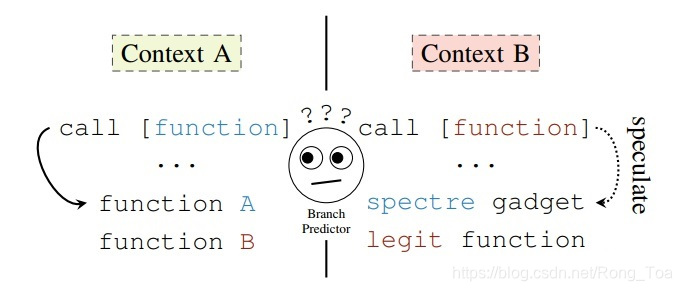
防御方法
Retpoline通过把jmp/call指令转换为ret解决分支预测的问题, 也即把分支预测由BTB转移到了RSB, 注意软件可以很方便地控制RSB (underflow问题这里不讨论).
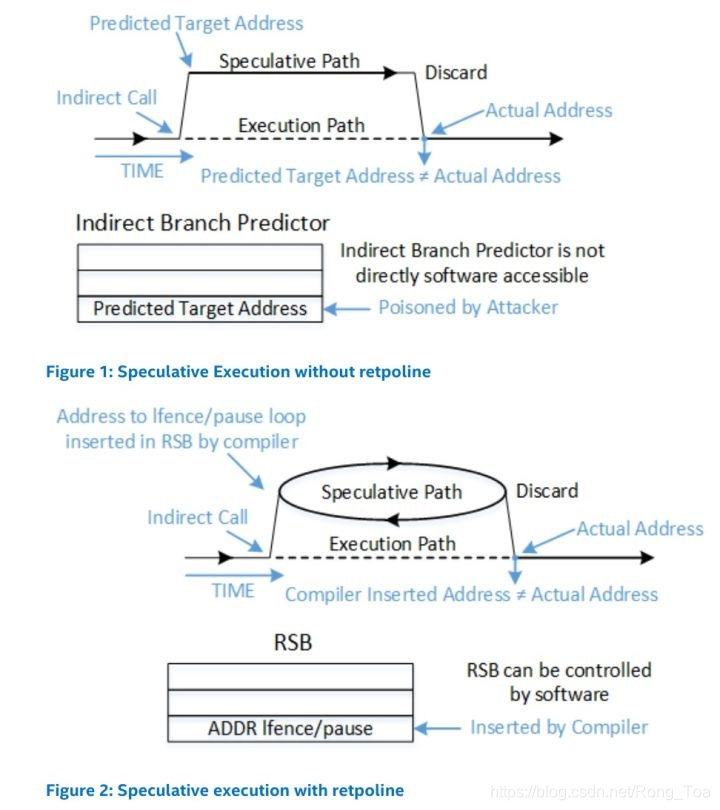
这里一jmp指令的indirect branch为例:

关键点在于ret导致的分支预测采用了RSB的内容, 而该内容是在call的时候产生的, 也就是上面的语句2. 所以即使针对ret的分支预测错了, 语句2并不会泄漏任何信息, 最后ret语句读到(%rsp)的内容, 该值和RSB里的值不符, 投机执行结束, 它没产生任何正向效果, 但是也没有任何负面效果.
引用
- Meltdown: Reading Kernel Memory from User Space
- Spectre Attacks: Exploiting Speculative Execution
- Meltdown and Spectre - Usenix LISA 2018
- Retpoline: A Branch Target Injection Mitigation
- Hacker Lexicon: What Is a Side Channel Attack?
- KAISER: hiding the kernel from user space
《Meltdown Redux:Intel缺陷使黑客窃取了数百万台PC的秘密》
Meltdown和Spectre既复杂又毁灭性。这是它们的工作方式,以及它们如此危险的原因。
</article>