http://blog.itpub.net/28285180/viewspace-2940749/
一、引言
闲鱼作为C2C电商交易平台,消息系统是导购链路上关键的一环。用户依赖聊天建立买家与卖家的信任,进一步获取商品信息。闲鱼消息的稳定性直接影响到闲鱼用户体验,成交效率。为强化闲鱼消息系统的稳定性,保障用户体验。闲鱼消息团队在2022年8月份对消息系统稳定性进行了体系化治理。本文将从闲鱼消息团队视角出发,讲讲我们怎么做稳定性治理。
二、问题定义
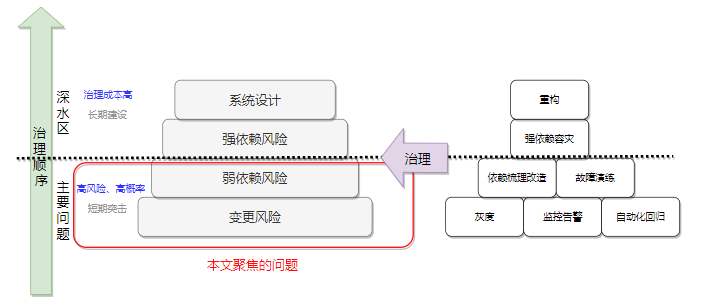
我们的目标很明确:减少线上问题。我们通过分析系统现状、回顾历史问题,将问题分为两类,一类是高风险高概率,需要重点突击解决的主要问题,包括变更风险、弱依赖风险。另一类是存在潜在风险,但治理成本高,需要长期投入建设的深水区问题,包括强依赖风险,系统设计。我们针对问题,制定了对应的治理措施。包括:灰度、监控告警、自动化回归、强弱依赖治理、演练、重构等。因篇幅有限,本文将聚焦于主要问题的治理措施。
三、问题治理
1、灰度
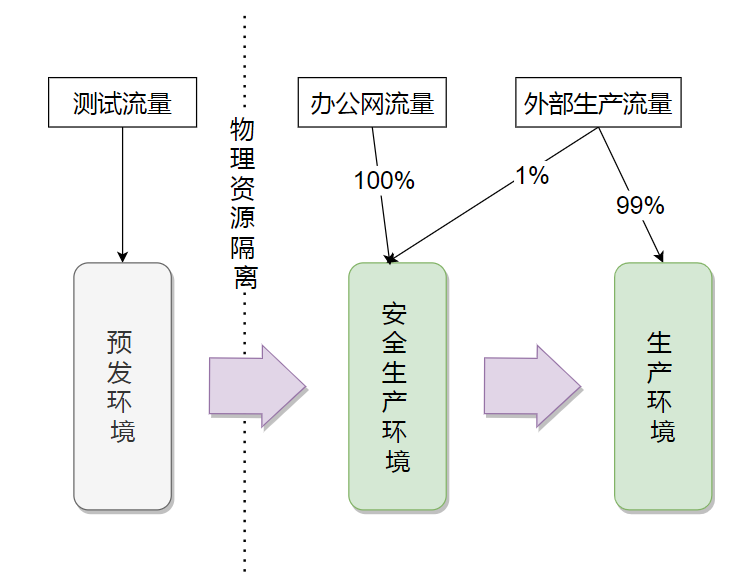
安全生产环境是由集团层面为保障线上稳定性的灰度流量生产环境。通过接入层网关的流量控制为环境提供1%线上流量+100%办公网流量,还原线上环境为系统验证提供场所。
我们以安全生产环境为基础展开一系列治理:
安全生产流量闭环
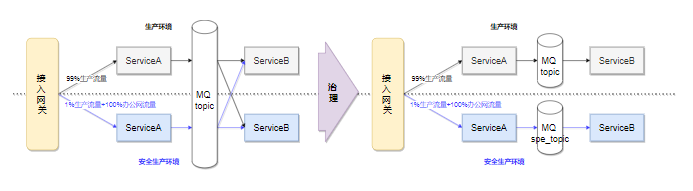
常规场景下,安全生产流量能保证从入口到后续全链路都在安全生产环境闭环。但在闲鱼消息场景里,强依赖MQ做流量的负载均衡,而安全生产流量经过MQ之后会被均匀打散,逃逸到线上,失去灰度观察能力。针对该问题,我们通过spring的Conditional条件注入能力,将线上和安全生产的MQ bean隔离,从而将线上和安全生产MQ topic隔离,使流量能够在安全生产环境完整闭环。
安全生产独立的监控告警,监控大盘
安全生产环境和生产环境的监控基线不同,告警阈值不同,为了能及时发现灰度问题,我们以安全生产环境的水位单独配置了监控告警。覆盖调用量、RT、错误量、消息延迟等多个指标维度,覆盖发送消息、创建会话等所有核心链路场景。我们将安全生产监控聚合成监控大盘,实时和线上监控水位做对比,不仅能发现变更引起的问题,还能发现变更对性能指标的影响。
安全生产独立的离线监控报表
监控告警是实时的异常指标监控,而离线报表是更长时间窗口的指标聚合。我们针对安全生产环境配置独立的离线监控报表,它不仅能发现细微波动的异常指标,也能发现变更对业务指标(例如消息到达率、点击率)的影响。
安全生产的自动化回归
自动化回归保障系统的底线,核心场景回归能避免引起严重的问题。我们将自动化回归与CICD集成,当发布到安全生产环境时自动执行自动化回归。
发布规范
在完善安全生产建设后,如果没有规范去标准化流程,建立行为准则同样达不到保障稳定性的目标。我们结合消息本身的业务特点,约定了消息团队内部的发布规范:发布必须在安全生产停留一晚,第二天灰度放量。确保:1. 覆盖时间相关的代码逻辑。2. 足够久的灰度观测。3. 产出t+1的离线监控报表
2、监控告警
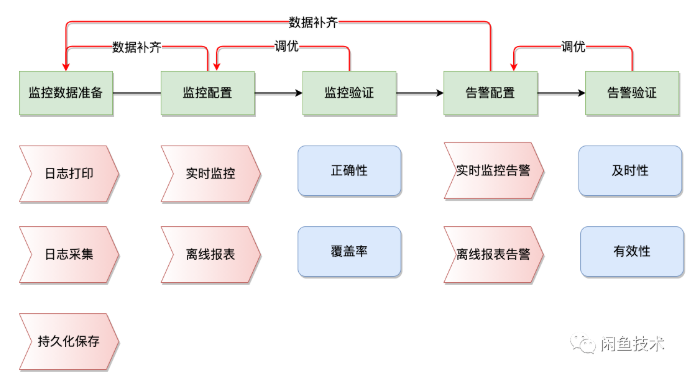
监控告警的生命周期可以分为监控数据准备、监控配置、监控验证、告警配置、告警验证五个环节。
监控数据准备环节我们有完善的基础设施。基于这个基础,我们对监控告警进行覆盖率、及时性、有效性治理:
监控覆盖率治理
治理的第一个目标是要确保监控覆盖全,不遗漏。我们分为三步确保覆盖完整:1. 梳理出系统的核心场景链路,链路上的核心观测指标,查缺补漏监控告警。2. 通用的监控告警作为兜底,覆盖资源水位、接口调用、中间件性能等基础指标。3. 最后,通过监控告警离线报表整体性review监控告警覆盖率。
告警及时性/有效性治理
治理的第二个目标是能及时发现问题、有效发现问题。告警的及时性与有效性是互斥的关系,为达到告警及时性与有效性的更优平衡,我们按照从严到松的方式逐步调整告警条件。同时为了持续维持告警及时性有效性,我们建立监控告警离线报表,定期review告警记录,对告警调优。
提供长效机制持续保鲜监控告警
监控告警治理需要持续投入,持续保鲜。我们搭建了监控告警离线报表,它包含所有的监控告警配置,告警历史流水,提供告警历史的聚合试图。为我们覆盖率治理、有效性治理提供全局视图,支撑我们定期对监控告警调优。
3、自动化回归
自动化回归的目标是保障底线,确保核心链路场景的稳定性。
端到端级别的自动化回归
端到端级别的自动化回归能从真实使用角度去验证稳定性。我们设计端到端的自动化回归用例,覆盖软件从安装、使用、卸载的完整生命周期,覆盖消息核心场景链路。我们将自动化回归与CICD集成,每天定时自动化回归,在发布流程做自动化回归卡口。
接口级别的流量回放
凤凰回放工具是基于JVMTI实现的流量回放测试工具。我们使用凤凰回放工具录制RPC流量,回放流量,diff结果,验证接口级别的稳定性。
4、依赖治理
依赖治理的目标是强弱依赖关系合理,并且弱依赖具备降级快恢能力。我们进行了以下治理:
依赖梳理:代码级别review依赖的合理性,review是否具备降级快恢能力
依赖改造:对不合理的强依赖降级为弱依赖,完善弱依赖的监控告警,降级快恢预案
依赖演练:依赖演练是对依赖治理的验收环节。目的是验证强弱依赖关系和预期一致,避免出现“我以为”但“实际是”的问题,同时验证弱依赖的问题发现能力,降级快恢能力。
四、总结思考
写这篇文章的时候,距离稳定性治理已经过去6个月。经过半年的实践,能体会到以上治理确实能有效解决问题。从主观来说,做线上变更时,灰度的停留规范+独立的监控告警让人心里有底。从过程来看,灰度环境的建设也确实帮我们规避了多起线上问题。从结果来看,这半年的线上问题趋近于0。稳定性治理我们经历了从一开始的无从下手,到后来逐渐找到思路,再逐渐找到确定性的路径,明确的解决了一些问题。对稳定性也有了几点思考:
1. 问题是消灭不完的,不要焦虑治理完还会出现问题,尽力减少问题;
2. 稳定性治理需要结合实际情况找到重点,网上大而全的治理经验不一定适用;
3. 稳定性治理需要持续投入,持续保鲜。例如告警问题跟进、告警降噪;
4. 最重要的还是要时刻绷紧一根弦,敬畏每次线上变更。