分布式实现的前提条件:
1.master机器和奴隶机的jmeter要一致
a. jmeter版本要一致
b.jdk主要版本要一致,比如都是jdk1.8,后面的小版本不一样不影响
c.jmeter脚本中csv文件要一致(特别注意csv路径,建议csv路径使用相对路径,放在脚本的同级目录)
d.jmeter插件要一致
2.同一局域网,防火墙要开放端口,不然访问会被拒绝
保持一致性的方法:直接压缩本地jmeter包,然后上传到各个奴隶机进行解压
奴隶机配置
1.本地打包的jmeter发送到奴隶机,然后解压。奴隶机可以是windows、mac或linux,这个没有特殊要求
2.修改配置文件 jmeter.properites 主要修改以下几个配置
a. 修改server_port 端口,我设置的是6789,你也可以设置别的值,但是主要要符合规则,且端口没有被占用

b. 修改server.rmi.port 端口,跟a步骤设置的端口保持一致

c. 设置server.rmi.ssl.disable=true,要去掉注释

3. 启动服务
./jmeter-server -Djava.rmi.server.hostname=192.168.114.128 hostname是助攻机器的ip,要填写你的奴隶机ip,我这个命令是在linux下启动的,windows中把./jmeter 换成 ./jmeter.bat 就可以了,linux下如果发现无法执行,要修改权限赋予可执行权限,出现下面的输出就算启动成功了
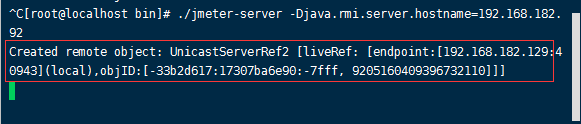
master机器配置
1.修改jmeter.properites配置,主要是以下几点
a.remote_hosts 配置为奴隶机的ip加端口,如果你有多个奴隶机就用逗隔开,例如localhost:1099,localhost:2010

b.server.rmi.ssl.disable=true

c.设置mode=Standard

配置已经完成!!!配置完成记得重启jmeter
配置完成后如果脚本设置了30个线程,有3台奴隶机,那么对于被压服务器就会有30*3个并发用户
主控机器就可以让奴隶机去执行力压测了

奴隶机已经开始执行了
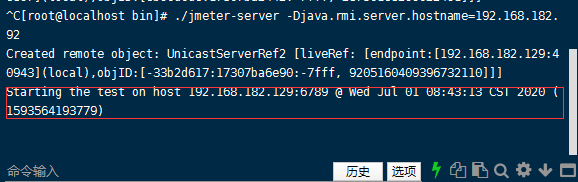
1.可能遇到的问题

连接奴隶机被拒绝,原因是奴隶机的防火墙没有开放对应端口
2.报证书错误:解决办法是在奴隶机执行![]() 这两个文件,linux执行下面的,windows执行上面的,然后根据提示enter就行,什么都不用写,但是最后一步要填y
这两个文件,linux执行下面的,windows执行上面的,然后根据提示enter就行,什么都不用写,但是最后一步要填y