大家好,我是沙漠尽头的狼。 本文首发于Dotnet9,介绍使用Lib.Harmony库拦截第三方.NET库方法,达到不修改其源码并能实现修改方法逻辑、预期行为的效果,并且不限于只拦截public访问修饰的类及方法,行文目录: 什么是方法拦截? 示例程序拦截 非public方法怎么拦截? 总结 1.
更多精彩内容,欢迎关注公众号:数量技术宅,也可添加技术宅个人微信号:sljsz01,与我交流。 大资金如何做现金管理 做B圈交易时,通常都会保留一部分以usd计价的稳定币,用来作为保证金的安全垫,或是备用等待可能的交易机会。例如,我们做USDT本位合约的交易,往往不会完全满仓,会预留一部分保证金应对
更多精彩内容,欢迎关注公众号:数量技术宅,也可添加技术宅个人微信号:sljsz01,与我交流。 大类资产轮动的概念 大类资产轮动,从定义上来说, 就是债券、股票、商品的轮动。从典型的学院派理论来讲,上述资产之间的轮动顺序往往是债券先走牛,然后股票牛市,股票走牛之后商品开始火爆,等商品行情结束后,最后
大模型材料收集 360安全大模型 推动大模型 B 端落地,360 想怎么做? 企业安全智控系统 安全问答 安全运营 通用大模型 数据安全问问题 专业知识缺乏 成本控制难 专业大模型 垂直专业性 安全合规性 使用成本 知识确权 B端:面向消费者 C端:面向商家 小米大模型 雷军:小米手机已跑通大模型,
转载:大模型研发核心:数据工程、自动化评估及与知识图谱的结合 本文将介绍大模型研发中数据工程,包括数据以及自动化相关的内容,并介绍在当前的情况下,知识图谱的定位以及如何融入到大模型的整个研发当中。 分享将会围绕下面四个方面展开: 大模型研发中的数据工程,起底当前一些大模型的数据构造以及360的构造方
[toc] # 简介 最近随着chatgpt的兴起,人工智能和大语言模型又再次进入了人们的视野,不同的是这一次像是来真的,各大公司都在拼命投入,希望能在未来的AI赛道上占有一席之地。因为AI需要大规模的算力,尤其是对于大语言模型来说。大规模的算力就意味着需要大量金钱的投入。那么对于小公司或者个人来说
大家好,我是陶朱公Boy. 今天跟大家分享一款基于“生产者消费者模式”下实现的组件。 该组件是作者偶然在翻阅公司一中间件源码的时候碰到的,觉得设计的非常精美、巧妙,花了点时间整理成文分享给大家。
大家好!我是sum墨,一个一线的底层码农,平时喜欢研究和思考一些技术相关的问题并整理成文,限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。 以下是正文! # 先看问题 首先上一串代码 ```java public String buy(Long goodsId, Integer goods
大家好!我是sum墨,一个一线的底层码农,平时喜欢研究和思考一些技术相关的问题并整理成文,限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。 以下是正文! 文章背景 我们最近做了很多项目,有些我们是总负责的,有些是合作的。这些项目涉及的系统各种各样,但基本上没有一家公司会主动去做『开放平台』
大家好!我是sum墨,一个一线的底层码农,平时喜欢研究和思考一些技术相关的问题并整理成文,限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。 以下是正文! # 对象存储是什么? >对象存储是一种数据存储方式,它将数据分割成不同的对象,并为每个对象分配一个唯一的标识符,用于访问和操作数据。这些
大家好!我是sum墨,一个一线的底层码农,平时喜欢研究和思考一些技术相关的问题并整理成文,限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。 以下是正文! 一、写文背景 我们在写后端项目的时候,日志打印是必需的。支持SpringBoot项目的日志框架一般有log4j、logback,这二者各
大家好!我是sum墨,一个一线的底层码农,平时喜欢研究和思考一些技术相关的问题并整理成文,限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。 以下是『微信小程序生态系列文章』正文! # 需求背景 我们是一个提供SaaS服务的小程序服务商,会给每一个客户申请一个专属的小程序,到目前为止已经差不
大数据技术的发展是一个非常典型的技术工程的发展过程,荣辛通过对于谷歌经典论文的盘点,希望可以帮助工程师们看到技术的探索、选择过程,以及最终历史告诉我们什么是正确的选择。 何为大数据 “大数据”这个名字流行起来到现在,差不多已经有十年时间了。在这十年里,不同的人都按照自己的需要给大数据编出了自己的解释
### 大火的ChatGPT与表格插件结合会有哪些意想不到的效果? ChatGPT已经火了好久了,想探索一下ChatGPT在表格中的使用场景,思考了很久自己整理了三点: 一、使用助手:根据需求提供操作指南、按照描述生成公式。 二、数据分析:对表格中的数据提供数据分析建议,按照描述分析数据。 三、工作
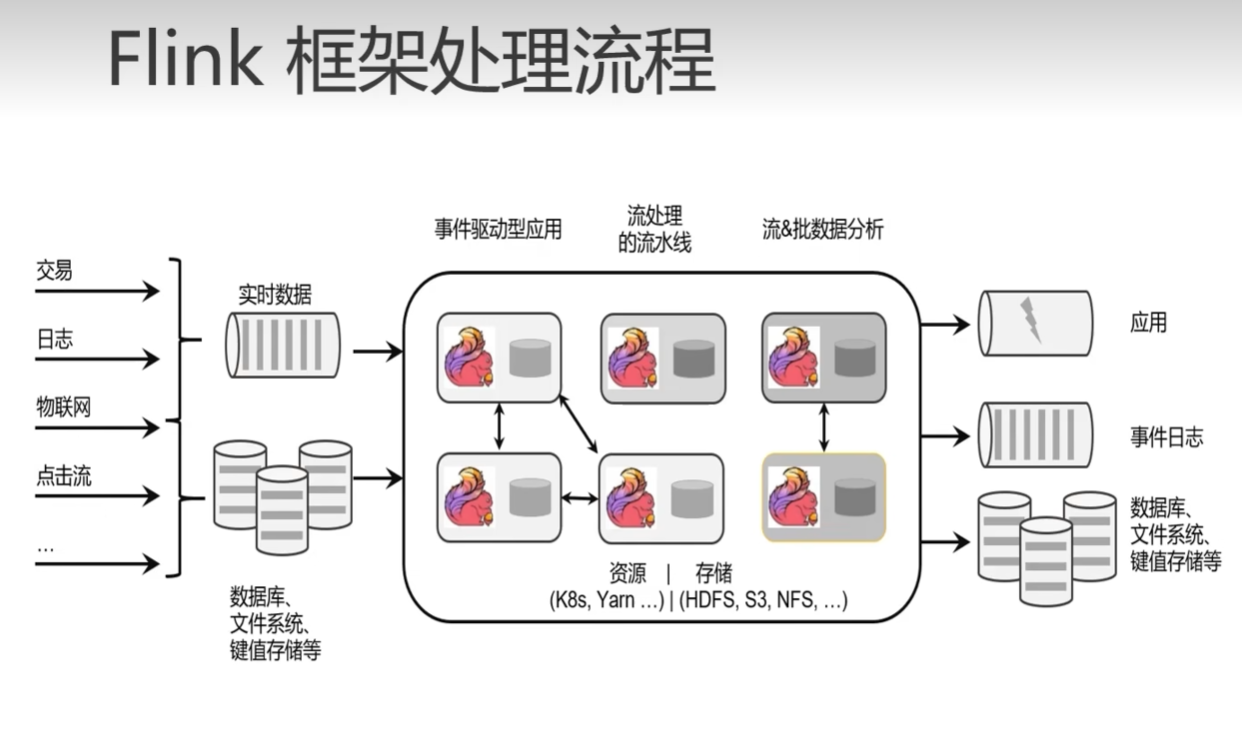 的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。 CDC 的种类 CDC 主要分为基于查询和基于 Binl
Caused by: org.apache.kafka.connect.errors.ConnectException: Error reading MySQL variables: The server time zone value '�й���ʱ��' is unrecognized or
Caused by: org.apache.kafka.connect.errors.ConnectException: The MySQL server is not configured to use a ROW binlog_format, which is required for this
| 目录 | 作用 | | | | | app | 产生各层数据的 flink 任务 | | bean | 数据对象 | | common | 公共常量 | | utils | 工具类 | app.ods.FlinkCDC.java package com.atguigu.app.ods; impo
我们前面采集的日志数据已经保存到 Kafka 中,作为日志数据的 ODS 层,从 Kafka 的ODS 层读取的日志数据分为 3 类, 页面日志、启动日志和曝光日志。这三类数据虽然都是用户行为数据,但是有着完全不一样的数据结构,所以要拆分处理。将拆分后的不同的日志写回 Kafka 不同主题中,作为日