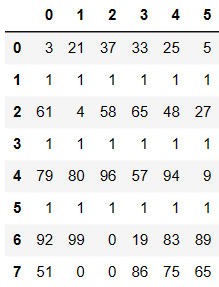
df = DataFrame(data=np.random.randint(0,100,size=(8,6)))
df.iloc[1] = [1,1,1,1,1,1]
df.iloc[3] = [1,1,1,1,1,1]
df.iloc[5] = [1,1,1,1,1,1]
df
# 检测哪些行存有重复的数据
df.duplicated(keep='first')
0 False
1 False
2 False
3 True
4 False
5 True
6 False
7 False
dtype: bool
df.loc[~df.duplicated(keep='first')]
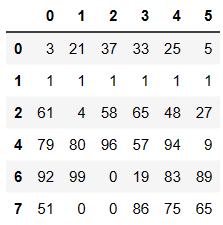
# 异步到位删除
df.drop_duplicates(keep='first')
