盖茨说:大语言模型创新的影响力可以与20世纪60年代的微处理器、80年代的个人电脑、90年代的互联网和21世纪初的苹果手机媲美。
大语言模型是人工智能领域自然语言处理的一部分。在大语言模型出现之前,自然语言处理主要依赖循环神经网络(RNN)模型实现。早在20世纪80年代,就出现了能够处理单词序列的循环递归神经网络,但这些网络的训练过程缓慢,且容易忘记序列中的早期单词。1997年,人工智能专家霍克赖特(Sepp Hochreiter)和施密德胡伯(Jürgen Schmidhuber)提出了一种新型的循环神经网络模型——长短期记忆(LSTM)网络。这种神经网络通过维护一个隐状态(hidden state),保留并持续更新输入序列的关键历史信息,能做出更准确的输出判断。
文本嵌入
2000年前后出现的文本嵌入(text embedding)是大语言模型发展中的一个重要创新。文本嵌入是指将待处理文本中的单元映射为固定维度的向量,使这些单元在每个维度上都能得到数值化的表示。每个维度上的不同数值代表该文本单元与对应维度的关联性。通过这种嵌入表示,计算机可以计算不同单元向量之间的距离或相似度,以理解文本的语义关系和含义。文本嵌入可以基于词或者标记(token)嵌入技术(如Word2Vec、GloVe)得到单词级别的向量,也可以基于句子嵌入技术(如BERT)得到句子级别的向量。文本嵌入的质量和表示能力直接影响大语言模型的性能,以及生成结果的质量。此外,大语言模型中文本单元的数量和用来标记每个单元的向量维度大小,也对生成文本的质量有显著的影响。例如,谷歌的大语言模型BERT使用768维的向量表示每个单词,而OpenAI的GPT-3则使用12888维的向量表示每个词语。
文本嵌入在处理人类语言上的应用与谷歌搜索算法对网络信息的处理方法有些类似。20世纪90年代,谷歌的两位创始人就通过对网页链接的分析提供了网页信息搜索的解决方案PageRank。谷歌的链接分析算法为每个网页分配一个排名值,然后使用特征向量表示所有互联网网页的排名关系。这是通过建立网页之间的指向关系形成的n元一次方程组,并利用该方程组的矩阵求解特征向量,以获取每个网页的权重。这个权重就成了后续搜索排序的重要依据。1997年,谷歌创始人使用这种方法分析互联网时,共收集了2400万个网页,包括7650万个链接。基于此,谷歌搜索引擎成功解决了互联网信息搜索问题。谷歌通过分析网页间的简单链接,确定每个网页的重要性大小,而大语言模型则是通过分析文本单元之间的向量关系,归纳出被分析文本中的知识(通过向量的相关性)。这些知识在预训练后以参数的形式嵌入到大语言模型中,并用于各种不同的应用。
2012年,深度学习神经网络模型在ImageNet图像识别挑战赛上的成功引领了人工智能领域的飞速发展。在随后的10年时间里,研究人员利用深度学习神经网络在图像和语音识别、语言翻译等领域取得了显著突破。引发这一革命的卷积神经网络等新型人工智能算法开始被用来处理自然语言数据。然而,这些神经网络结构与循环神经网络一样,只能顺序地输入和输出单词或文本单元,无法像处理图像时那样充分利用大规模并行处理的计算优势。因此,卷积神经网络虽然在许多领域取得了进步,但在自然语言处理,尤其是文本理解、分析和生成方面的突破并不明显。
这个瓶颈在2017年被打破,这归功于谷歌研究团队提出的新型神经网络架构——转换器(Transformers),如图1所示。转换器的主要创新之处在于引入了“自注意力机制”(self-attention mechanism)。传统的序列处理模型需要依次输入序列中的每个元素,一次处理一个,这限制了模型的并行处理能力,且在处理长序列时可能出现信息丢失的问题。然而,转换器的自注意力机制使模型能直接关注到序列中任意位置的元素,同时考虑整个序列,这使得模型能更好地捕捉序列中的长距离依赖关系。具体来说,自注意力机制在计算元素表示时,会考虑到整个序列中所有元素的信息,并对不同的元素赋予不同的注意力权重,这个权重体现了计算当前元素表示的重要性。这使得转换器在处理如机器翻译或文本摘要等任务时,能够捕捉到更丰富的上下文信息。此外,转换器彻底摒弃了传统循环神经网络和长短期记忆网络中的递归操作,使所有操作都可以在多个元素上同时进行,极大提高了计算效率,并使其在大规模数据集上的训练成为可能。这一进步大大提升了自然语言处理领域的计算效率,尤其是提升了使用该架构和模型的人工智能程序学习各种海量自然语言文本的速度。
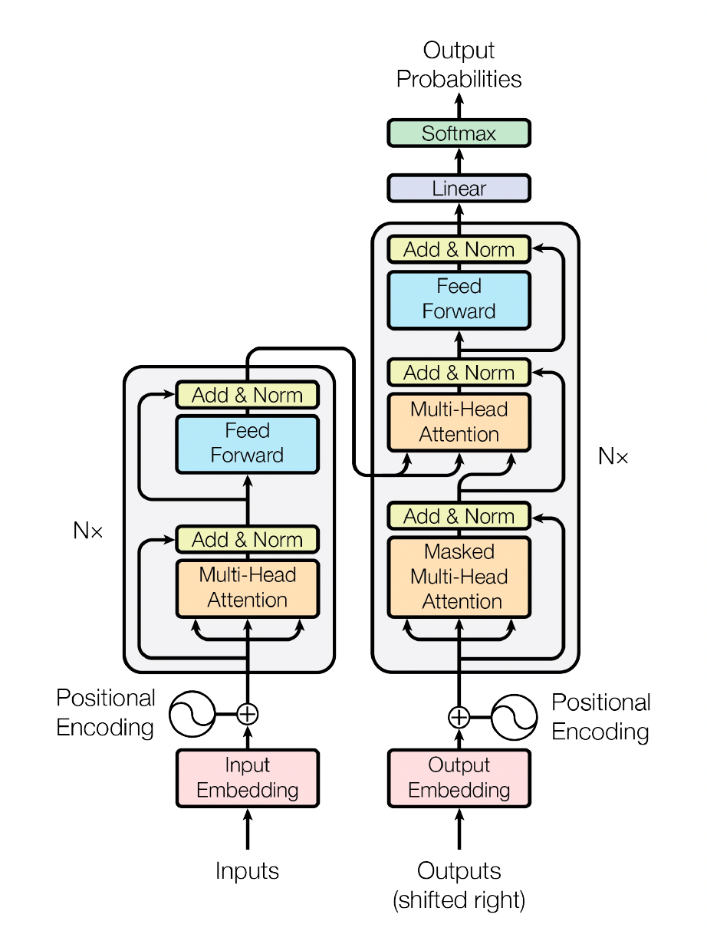
虽然最早提出转换器架构的是谷歌,但是最早将这一研究成果用于大语言模型的却是OpenAI。OpenAI成立于2015年,是由一批硅谷精英创建的非营利组织,其目标是防止谷歌收购DeepMind后在人工智能领域形成垄断地位。2017年谷歌提出转换器架构之后,OpenAI率先在2018年推出了大语言模型GPT(Generative Pre-trained Transformer)。紧随其后,谷歌在2019年也推出了另一个大语言模型BERT(Bidirectional Encoder Representations from Transformers)。
BERT和GPT均基于转换器架构,并采用大规模并行计算和自监督学习方法进行预训练。这两种模型首先将输入文本转换为向量表示,然后输入到转换器网络中进行自动处理。这种方式使得使用海量高质量文本数据预训练出大语言模型成为可能。在预训练之后,模型进行微调以完成具体的任务。尽管BERT和GPT有许多共性,但也有显著区别, 最主要区别在于预训练方法和模型方向不同。BERT采用遮蔽语言模型(masked language model)进行预训练,它会随机遮盖输入文本中的部分单词,并尝试预测这些单词。同时,BERT是一种双向模型,能够同时从左至右和从右至左分析输入文本的上下文信息。与此相反,GPT则运用自回归语言模型(autoregressive language model)进行预训练,该模型从一个方向开始,基于已有的文本预测下一个单词。这种区别导致了BERT和GPT在应用方面的优势各异。BERT主要应用于机器翻译、问答系统、情感分析等任务,而GPT则更适用于对话和文章创作等场景,因此GPT在大众市场中率先赢得了广泛的关注和应用。
通过结合转换器架构和无监督学习,大语言模型无需明确的标签或指导,就能学习丰富的语言模式和知识。这意味着这些模型不仅可以通过吸收大量的文本数据进行自我学习,还可以通过不断扩展其文本嵌入单元的向量空间和参数数量进行提升,从而持续增强对语言模式和知识的整合能力。GPT系列模型的发展历程证实了这一原则。从2018年的GPT-1到2022年的GPT-3.5,GPT模型的参数数量已从1.17亿增长到1750亿。最新版本的GPT-4的参数数量据称超过1万亿,这基本上延续了指数增长的趋势。随着参数数量的飞速增长,这些大语言模型的能力也呈现出惊人的进步。GPT-1在各种自然语言处理任务上表现出色,GPT-2能够生成连贯且有意义的文章,GPT-3不仅可以生成高质量的文本,还能执行翻译、编程、诗歌创作等多样化的任务。而GPT-3.5,即广受欢迎的ChatGPT,已经能在多个领域超越人类水平,包括通过法律、医学等各个专业领域的资格考试。
值得指出的是,参数数量并非大语言模型表现的唯一决定性指标。参数的分布和可调性也起着重要的作用。比如,谷歌最近推出的基于BERT的BARD对话人工智能只用了1.73亿个参数,远低于GPT-3.5和GPT-4,但效果仍然出色。另一方面,据传GPT-4采用了新的混合专家架构,该架构连接了8个具有相同架构的子模型,每个子模型拥有2200亿个参数,并使用了不同的训练数据和16次循环推理。这意味着GPT-4拥有1.76万亿个参数,但这并不是简单的参数增加,而是引入了并行分布的因素,这也可能是GPT-4比GPT-3.5具有质的提升的原因。
大众媒体往往用“统计预测下一个词汇”的方式解释大语言模型的工作原理,然而这种说法并没有涵盖真正的全貌。ChatGPT等大语言模型能够成功预测下一个字符的机理并非仅依赖相关词频的统计,更在于一系列创新技术,比如文本嵌入技术。大语言模型的核心创新是通过分析网络上所有可接触的人类文本信息中包含的语言模式和知识产生新的信息,并将这些信息通过预训练的方式嵌入到文本向量数据库中。当这种信息模式和数量积累到一定规模时,就会出现一种由量变到质变的“涌现属性”(emergent property)。这不是一个单纯的预测下一个词的任务,而是深度理解和再创造语言的复杂过程。
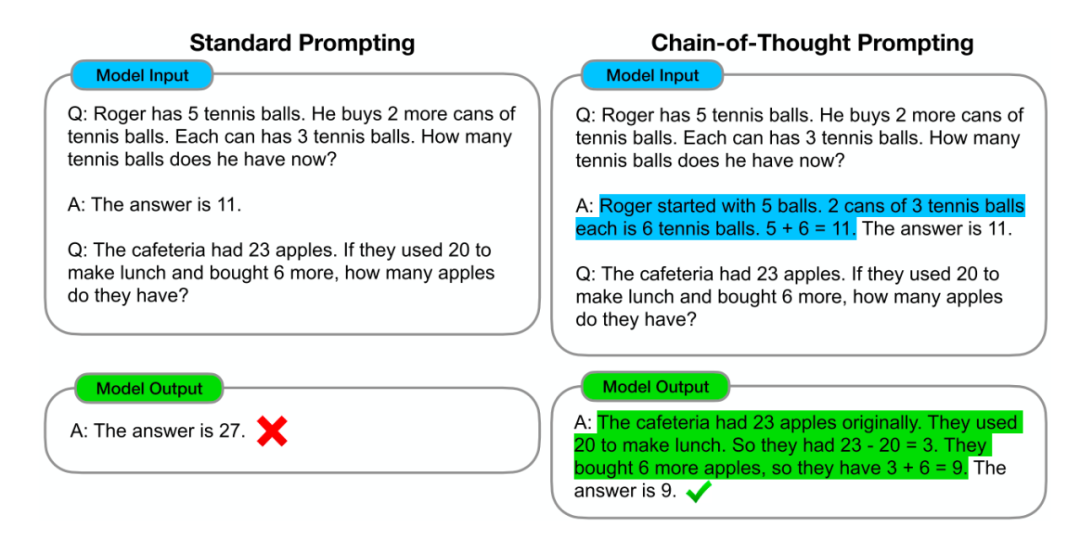
大语言模型的涌现属性之一就是思考链条(chain of thought),如图2所示。2022年谷歌的研究人员发现当大语言模型达到一定规模时(比如GPT-3有1750亿个参数,PaLM有5400亿个参数),给它们提供一个通过几步中间过程推理和解决逻辑或者数学问题的例子,然后再问一个问题,它们就可以用中间过程的推理解决问题,而且用这种思考链条方式解决问题可以大幅度提高正确率。后来随着大模型的进一步优化,用户在使用这些大模型时,已经不用提供一个具体的例子,只需要在提示中添加中间解决步骤之类的用语就可以达到类似的效果。这说明大语言模型具备一定规模后,经过对文本数据的分析,“涌现”出了类似于数学符号推导的推理能力。这种推理能力为大语言模型赋予了处理和分析复杂信息的能力,使其能够自主提供创新的解决方案,以应对各种复杂问题和未知情境。具备逻辑推理能力的大语言模型,通过持续推理和学习,不断提升自身的性能,这使它们在需要灵活性和创新性解决方案的工作中展现出了竞争力,例如分析大量市场数据、财务报告和行业趋势,然后推理出最优的投资策略。
大语言模型代表的生成式人工智能将对社会产生深远的影响。一方面,它将提高企业和个人的工作效率,推动各种业务的变革;另一方面,其应用可能引发就业结构、教育方式、社会交往等方面的变革。
大语言模型的开发和应用将形成一个包括服务提供商、开发工具、专门的硬件设备、教育培训等在内的生态系统,变革也将从此开始。OpenAI和谷歌这类拥有大语言基础模型的公司已经成为服务提供商,并且会推出类似苹果APP商店的应用平台。在此之外,企业和商界将通过服务提供商提供的API调用或者客户端直接安装的方式,将大语言模型的人工智能集成至其商业操作之中。
OpenAI预测约80%的美国劳动力中有10%的工作可能会受到大语言人工智能引入的影响,而有19%的美国劳动力将面临至少50%的工作受到影响。高盛集团预测大约三分之二的现有工作会受到人工智能自动化的影响,而生成式人工智能最多可能替代现有四分之一的工作。在全球范围内,生成式人工智能可以实现3亿全职工作的自动化。
实际上,在大语言模型诞生之前,诸如Midjourney、DALL-E、Stable Diffusion等图像生成式人工智能,以及MusicLM等音乐生成式人工智能已经能创作出与普通设计师作品相匹敌的产品。这种技术的发展导致许多小公司开始削减设计人员的岗位。我们可以预见,类似的情况将在大语言模型的各种应用领域出现,企业最终可能会裁减大部分可被生成式人工智能替代的员工,而保留下来的岗位员工则需要熟练掌握人工智能技术以提高工作效率。
大语言模型最终能否替代人类的工作,关键在于其可靠性。这一因素决定了人工智能取代不同职业的速度和顺序。当人工智能的错误率降至人类水平或更低时,人工智能大规模取代人类工作的进程将会加速。根据最新的GPT-4测试报告,其错误率在20%左右,对大多数可能被替代的工作而言,这仍然是一个相对较高的错误率。与可靠性紧密关联的一个特性是,准确率和推理深度的提高往往难以同时实现。由于每个词的输出都存在一定的错误概率,随着推理层数的增加,错误概率会呈指数级增长,这意味着,如果要求大语言模型进行更深层次的逻辑推理,其准确率会迅速降低,除非每一步都有人工进行校正。因此,从近期来看,使用人工智能提升人类工作效率而不是全面取代人类仍将是主流趋势。
对普通用户而言,这场变革或许将从改变我们与机器的交互方式开始,其影响会在教育和社交活动中逐渐发生。20世纪80年代的个人电脑图形用户界面,以及2007年的苹果手机软键盘,都是人机交互历史上的重大革新。前者使得那些不熟悉电脑命令的普通用户也能够轻松使用电脑,大大提升了工作效率;后者则通过提供直接下载或卸载应用程序的功能,以及语音输入等方式,进一步降低了电脑和手机的操作难度。大语言模型的出现将引领另一场革新:它能理解和生成自然语言,使用户能够通过自然语言与电脑进行交互,无需通过传统的用户界面点击或输入特定命令,这是一个去界面化的过程。用户用自然语言发出的指令能被更精准地理解并执行。另外,通过学习用户的交互方式和偏好,大语言模型可以提供个性化的用户体验。而且,大语言模型通常支持多种语言,这让用户可以用自己的母语与电脑进行交互,从而提升用户的使用体验。在大语言模型出现之前,网络对话和聊天机器人已经在市场上产生了一定的影响力。大语言模型的引入将使这些机器人更加智能化,最终它们的功能将从对话延伸至提供各种咨询服务和执行各种用户指令。此外,交互界面的革新将使许多已经具有一定智能化能力的生产和生活物件能够通过网络与大语言模型连接,被赋予更强大的人工智能能力,使它们更“人性化”。
大语言模型的创新,特别是其具有思考链条和自我更新能力的突破性特性,使其区别于以往单一领域的渐进式人工智能创新,显示出通用人工智能的迹象。目前通用人工智能被理解为理论上具备人类水平的理解、学习和应用知识能力的一种人工智能形态。换言之,无论是科学技术、文艺创作、高级策略游戏,还是日常对话,通用人工智能都能从经验中学习,根据新信息和环境自我改进和适应,在各种不同的任务中都能像人类一样表现出色。通用人工智能还具有创新性,能提出新的想法,解决新的问题,甚至在需要时提出新的解决方案,自主决策,而不只是在人类预设的参数和选项中运行。
通用人工智能
当前,我们已经拥有在特定任务上表现优秀的人工智能系统,如图像识别、自然语言处理、游戏对战等。但这些系统大多属于人工窄智能(artificial narrow intelligence),即只能在特定任务上表现优秀,而对于未经专门训练的新任务,其表现往往不佳。迄今为止,我们尚未成功开发出真正的通用人工智能系统。
通用人工智能的一个关键要素是自我学习能力。如果一个人工智能系统能够在不需要人类帮助的情况下实现源代码的递归式更新和优化,那么它就具备了实现通用人工智能的初步技术条件,因为这种系统可以通过不断的自我学习,迅速超越人类在任何专业领域的能力。在这方面,大语言模型已经展现出了一些能力。例如,GitHub和OpenAI合作开发的编程助手GitHub Copilot能够自动编写各种大小的应用程序;软件机器人AutoGPT和HuggingGPT,可以通过调用API或者与Copilot类似的专家模型与大语言应用结合,通过大语言模型的自动任务解析,实现人类用户设定的目标。从技术架构上看,AutoGPT主要通过构建适当的提示让大语言模型自我运行来处理复杂问题。它可以参考互联网信息、历史对话等生成最终结果。而HuggingGPT更像是一个人工智能的大脑,负责调度、决策和整合,将具体的任务交给其他专家模型执行,这些专家模型可能是语言模型或其他模型,然后一起形成一个协调的系统,共同完成复杂的任务。
随着人工智能向通用人工智能的进阶,一个紧迫的伦理问题浮出水面——我们是在孕育一个未来的机器人助手,还是人类的终结者?
【悲观】对于这个问题,ACM图灵奖的两位得主辛顿(Hinton)和杨立昆(Yann LeCun)有着不同的观点。辛顿持有比较悲观的看法,他为了警告社会关于人工智能的潜在风险,甚至放弃了他在谷歌的职位。在他看来,人类智能在人工智能面前很快将如同一个三岁小孩在一个成人面前。这意味着我们试图以各种方式限制和控制人工智能的尝试,在人工智能“觉醒”的那一刻都会被迅速识破和绕过,我们可能会毫不察觉地在人工智能的控制下生活。
【乐观】相反,杨立昆的观点更为乐观。他认为大语言模型的能力将最终被限制在文字所能代表的智能范围内,离达到通用人工智能的水平还有很大距离,更别提“自我意识”这种我们目前还未完全理解的概念了。他甚至全面否定了大语言模型能发展为通用人工智能的可能性,并提出了所谓“世界模型”的发展路径。
【中立】对于这两位人工智能领域权威人物的两极对立观点,OpenAI的创始人奥特曼(Altman)持更中立的立场。2023年5月,他在美国国会关于人工智能风险控制的听证会上表示,政府或者国际组织需要对人工智能的发展进行有效监管和规范。这一立场可能更多来自对这一技术被恶意用户或者经济和政治实体滥用风险的担忧。至于人工智能本身带来的风险,他认为,人工智能可能带来的灭绝人类的风险应被视为与全球流行病和核战争等同等级的社会风险,降低这一风险应该成为全人类的优先任务。