问题排查---应用程序不在接收新请求
关键词:springboot,jstack,Arthas
查看前端网页,发现所有请求都pending,都超时。但是查看后端程序发现并没有挂掉,cpu,内存都正常。但是日志不打印了。看起来应用程序整体卡死了。
然后重启应用程序,发现又能正常运行了,但是过了半小时后,应用程序又会卡死,不再接受新请求。但是看起来cpu和内存等都是正常的。
使用top命令,查看到应用进程cpu内存正常,占用不高。
使用Arthas查看线程信息,使用dashboard,thread -n 10等命令,看到线程cpu和内存也都占用不高。但是发现大量线程处于WAITING状态:
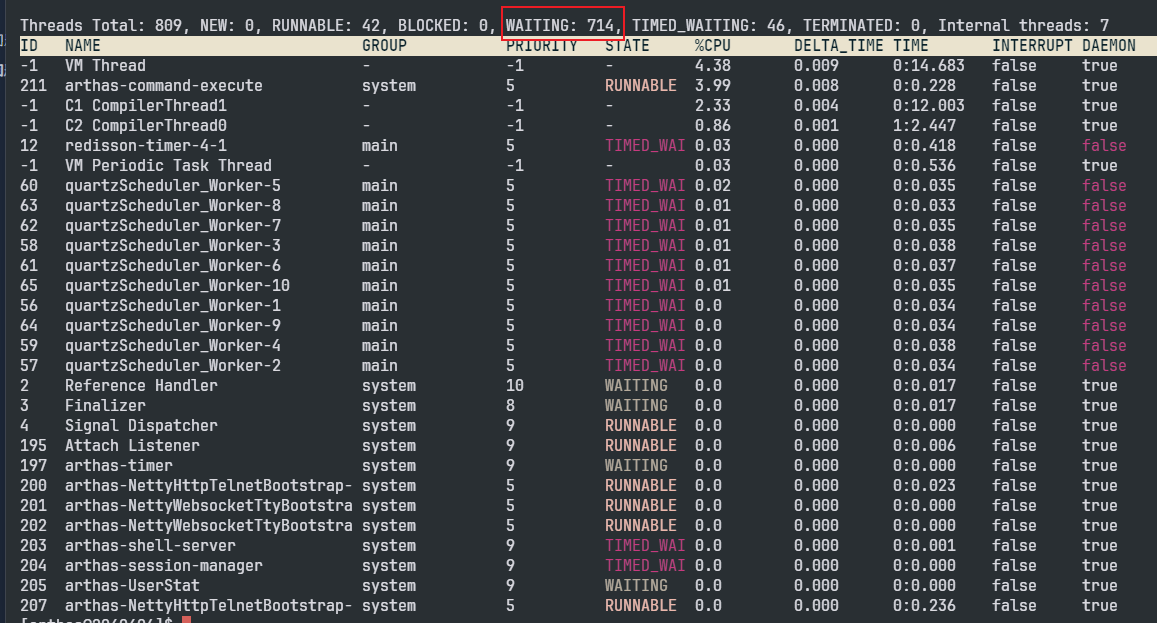
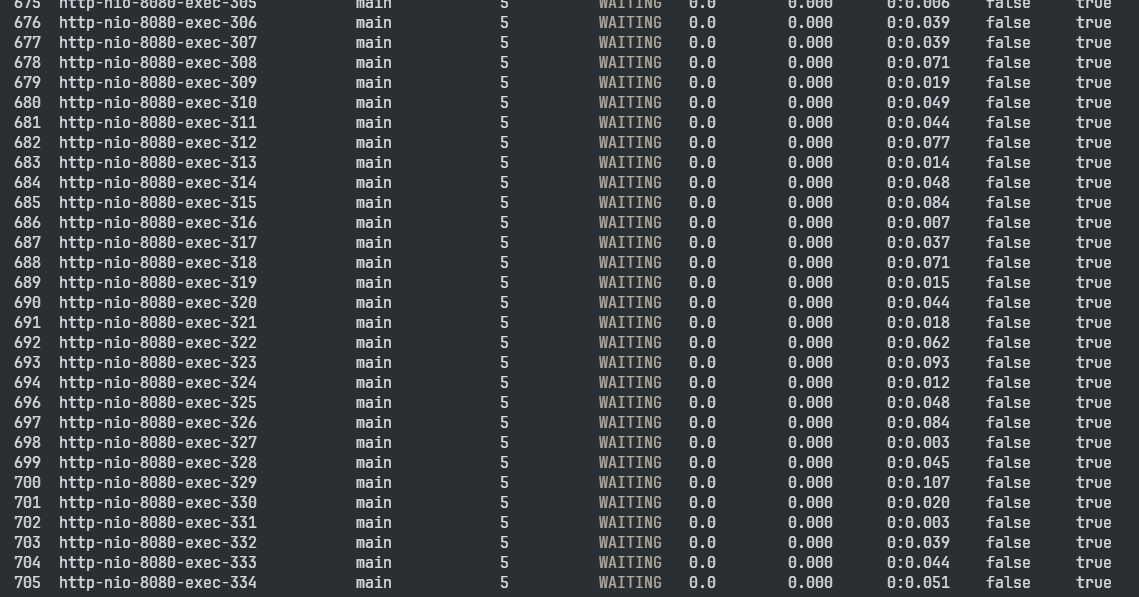
使用thread --state WAITING --all,可以看到很多http-nio-8080-exec-开头的线程:
随便选中其中一个线程,查看其堆栈信息,thread 700:
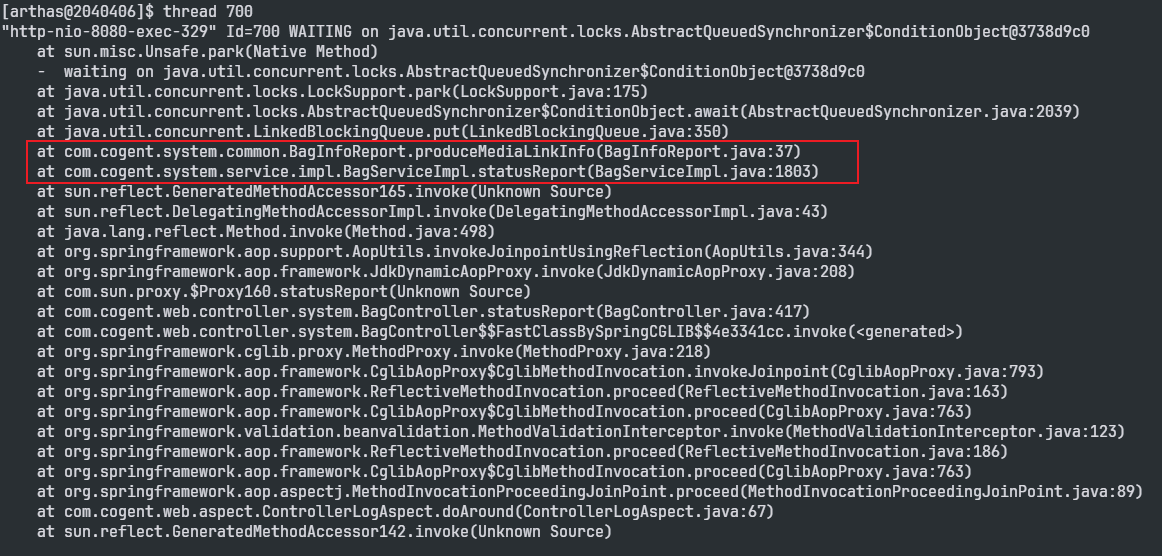
找到了相关的代码,经过分析发现produceMediaLinkInfo方法是向一个阻塞队列放入数据,当阻塞队列满了的时候,则该线程将阻塞。其实这个阻塞队列就是一个生产者-消费者模型,现在生产者的生产速率过快,而消费者的消费速率相对较慢,导致大量的线程往阻塞队列中put数据时,阻塞住了,因此大量线程进入WAITING状态。
由于大量线程处于WAITING状态,导致tomcat没有多余的线程处理其他新的请求,因此才看起来程序卡死,但是其cpu和内存都正常。
除了使用Arthas,我也使用了jstack命令,也是能够看出大量线程处于WAITING状态,并且jstack会打印每个线程的堆栈信息。
定位好问题后,其实就是想办法加快消费者的消费速率,减小生产速度,扩大阻塞队列容量。
对于增加消费速度,可以根据实际情况增加消费者线程,选择合适批量插入的数量(增加批量插入数据库的数量,看是否能提高效率)
对于减小生产速度,可以根据实际业务情况与同事商量,是否有必要减少上报的频率。因为我们之前是一个设备一秒一次上报状态,现在突然改成了100ms一次,也就是说生产的速率突然提高了十倍,感觉还是有点问题的,可以再去商议这个问题。
增大阻塞队列容量,或者不使用put方法,而是使用add或者offer来添加元素。
给大家做一个有意思的操作~~~
现在我们已经知道了阻塞队列满了,导致大量线程WAITING,那么现在我直接将阻塞队列clear,那么理论上线程就不会阻塞了。
thread命令查看现在有多少WAITING线程:
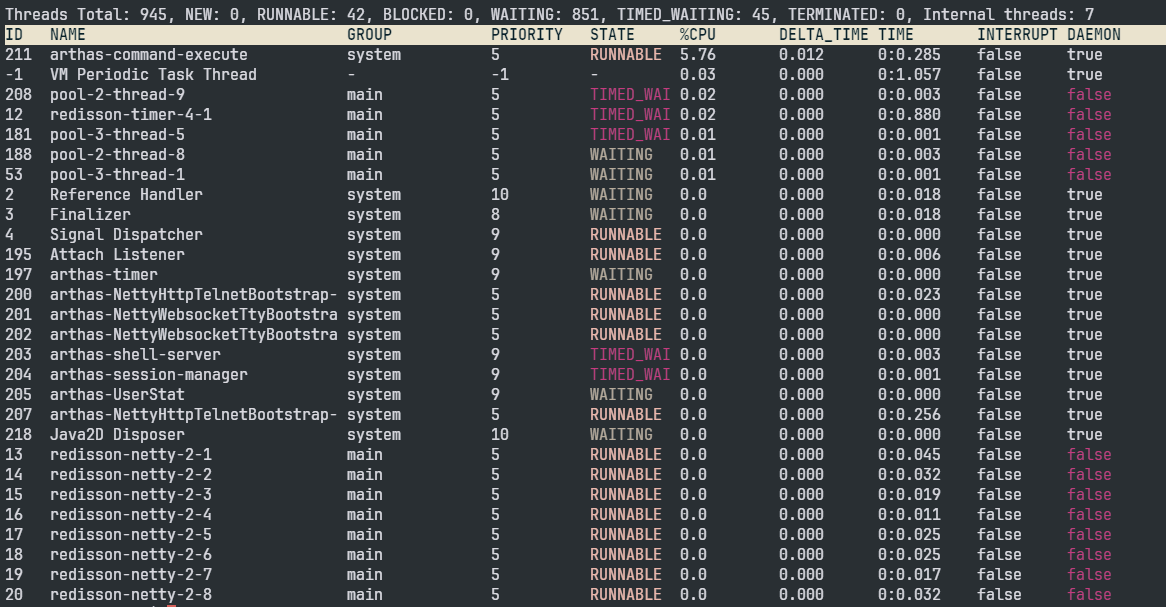
可以看到有851个WAITING
现在我们看看这个阻塞队列的大小(这个阻塞队列最大是50,mediaLinkInfoQueue是阻塞队列的名字):
ognl @com.cogent.system.common.BagInfoReport@mediaLinkInfoQueue.size()

可以看到阻塞队列满了。
我们执行clear方法:
ognl @com.cogent.system.common.BagInfoReport@mediaLinkInfoQueue.clear()
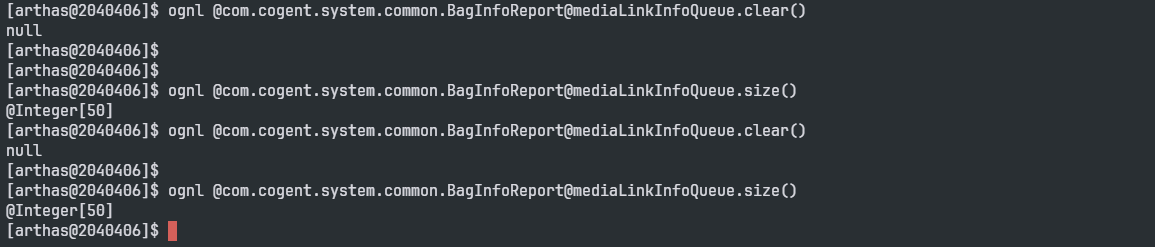
我执行了clear方法,但是很快阻塞队列又满了。
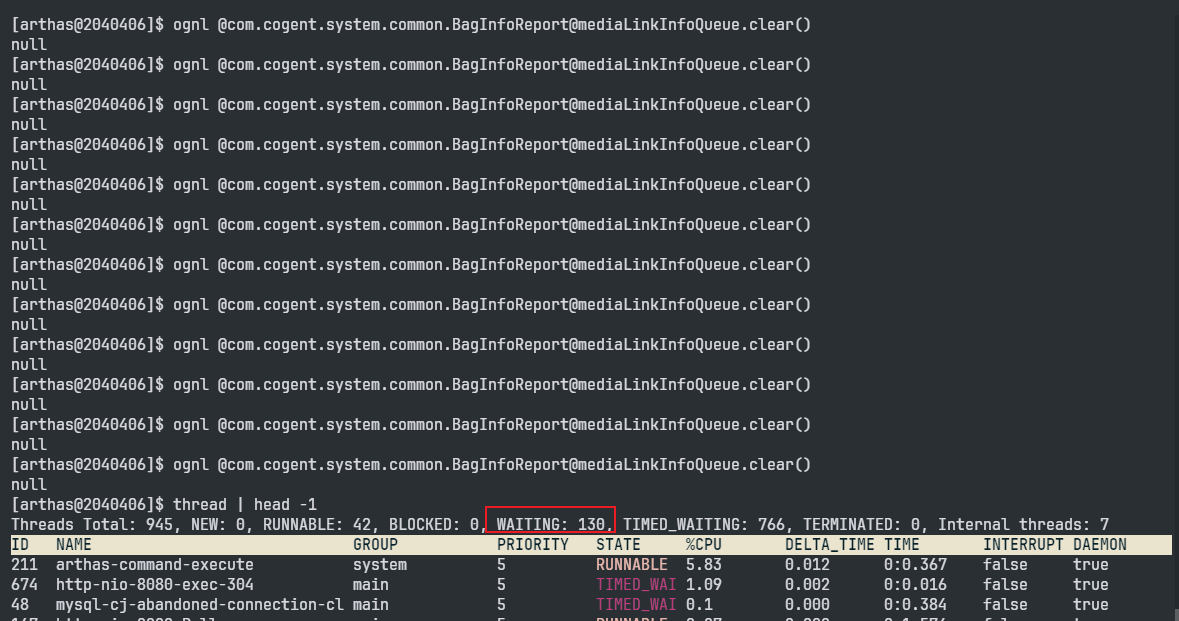
然后我又执行了很多次clear方法,我们可以看到WAITING状态的线程越来越少。
然后我的程序终于重新运行起来了,可以接受新的请求了。
我觉得这个ognl很有意思,但是现在我只看到他操作类变量,不知道ognl可不可以操作对象的成员变量,如果有网友了解,欢迎指出!!