概述 书接上回:《Rancher 系列文章-Rancher 升级》, 我们提到:将 Rancher 用 Helm 从 v2.6.3 升级到 v2.6.4. 接下来开始进行 K3S 集群的升级:将 K3S 集群从 v1.21.7+k3s1 升级到 v1.22.5+k3s2 相关信息 本次升级的 K3S
概述 最近在玩 Rancher, 先从最基本的功能玩起, 目前有几个已经搭建好的 K8S 集群, 需要批量导入, 发现官网已经有批量导入的文档了. 根据 Rancher v2.6 进行验证微调后总结经验. 1. Rancher UI 获取创建集群参数 访问Rancher_URL/v3/cluster
概述 只要是个公司,基本上都有邮箱和 AD(Active Directory). 在 AD 里,已经有了: 用户 账号密码 邮箱 用户组 组织架构 所以对于一些仅限于本公司一定范围内人员使用的管理或后台或运营运维类系统,其实是非常适合对接 AD 来进行认证、分组,以及根据分组来进行权限分配的。 对于
概述 之前在 天翼云上用 4 台机器安装了一个 1 master(及 etcd) 3 node 的 K3S 集群,并在其上使用 Helm 安装了 Rancher 2.6.3 版本。 前几天发现 Rancher 官方推荐的最新版为:v2.6.4 所以决定先后对 Rancher 和 K3S 集群进行升级
一 基础信息 1.1 前提 本次安装的为 20220129 最新版:Rancher v2.6.3 VM 版本为 RHEL 7.8, 7.9 或 8.2, 8.3, 8.4(Rancher 官网要求) VM YUM 仓库:已配置对应版本的 RHEL 和 EPEL YUM 仓库 VM 提供 root 权
插件打包 这种方式是平时最常用的,首先要下载并安装maven环境,然后在被打包的项目中引入插件,有各种各样的打包插件,比如springboot自带插件: org.springframework.boot spring-b
DHorse系列文章之镜像制作 制作镜像常用的工具 使用Docker制作镜像 1.使用docker commit制作 该命令使用比较简单,可以自行网上搜索教程。 2.使用Dockerfile制作 这种方式,需要编写如下的Dokerfile文件: FROM openjdk:openjdk:13-jdk
金融社区优惠文章是基于京东商城优惠商品批量化自动生成的,每日通过不同的渠道获取到待生成的SKU列表,并根据条件生成优惠文章。 但是,生成优惠文章之后续衍生问题:该商品无优惠了,对应文章需要做取消推荐或下架处理,怎样能更快的知道该商品无优惠了呢?
之前写过一篇有关TRE优化模型详解的博文: https://www.cnblogs.com/zoubilin/p/17270435.html 这篇文章里面的附录给出了非线性模型化线性的方式,具体内容如下: 首先是篇文章的变量和原模型(具体见我上面那篇笔记): 其次这篇文章附录给出的非线性化线性的方法
## 前言 本文介绍博客文章相关接口的开发,作为接口开发介绍的第一篇,会写得比较详细,以抛砖引玉,后面的其他接口就粗略带过了,着重于WebApi开发的周边设施。 涉及到的接口:文章CRUD、置顶文章、推荐文章等。 开始前先介绍下AspNetCore框架的基础概念,MVC模式(前后端不分离)、WebA
这些方法在.NET7中变得更快 照片来自 CHUTTERSNAP 的 Unsplash 欢迎阅读.NET性能系列的第一章。这一系列的特点是对.NET世界中许多不同的主题进行研究、比较性能。正如标题所说的那样,本章节在于.NET7中的性能改进。你将看到哪种方法是实现特定功能最快的方法,以及大量的技巧和
批量删除wordpress的方法有两种:1.从wp后台可以调整展示:最多999条 2.选择“Bulk”--“Apply” 通过批量删除wordpress文章和页面的数据库命令的步骤: 备份数据库:在执行任何数据库操作之前,务必备份您的数据库以防万一。 进入数据库:使用您的数据库管理工具(例如 php
自从最近微软开源Semantic-kernel (SK) 来帮助开发人员在其应用程序中使用AI大型语言模型(LLM)以来,Microsoft一直在忙于改进它,发布了有关如何使用它的新指南并发布了5篇文章介绍他的功能。 开发人员可以使用Semantic-kernel (SK) 创建自然语言提示、生成响
linux 使用FIO测试磁盘iops 方法详解 FIO是测试IOPS的非常好的工具,用来对硬件进行压力测试和验证,支持13种不同的I/O引擎, 包括:sync,mmap, libaio, posixaio, SG v3, splice, null, network, syslet, guasi,
https://www.jianshu.com/p/9d8296562806 跳表是一种神奇的数据结构,因为几乎所有版本的大学本科教材上都没有跳表这种数据结构,而且神书《算法导论》、《算法第四版》这两本书中也没有介绍跳表。但是跳表插入、删除、查找元素的时间复杂度跟红黑树都是一样量级的,时间复杂度都是
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品。我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值。 本文作者:琉易 https://liuxianyu.cn 本次分享基于『袋鼠云数栈UED团队』新发布的 UED Landing 页 实践得来,UED Landing 页
Kafka 和传统的消息系统(也称作消息中间件)都具备系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。与此同时,Kafka 还提供了大多数消息系统难以实现的消息顺序性保障及回溯消费的功能。
## 前言 上一篇留的坑,火速补上。 在之前的第6篇中,已经有初步介绍,本文做一些补充,已经搞定这部分的同学可以快速跳过,[基于.NetCore开发博客项目 StarBlog - (6) 页面开发之博客文章列表](https://www.cnblogs.com/deali/p/16286780.ht
# 1. 简介 ## 1.1 线性回归模型概述 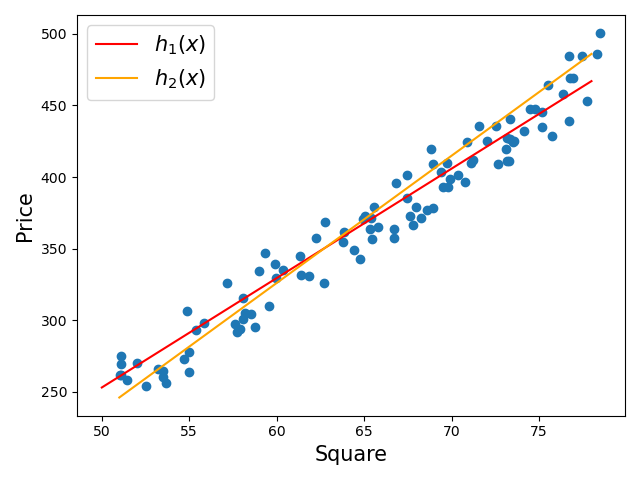 线性回归是一种统计学中的预测分析,该方法用于建立两种或两种以
更多精彩内容,欢迎关注公众号:数量技术宅,也可添加技术宅个人微信号:sljsz01,与我交流。 获取数字货币的历史行情数据可以通过一些专门的数字货币数据API或者第三方数据服务来实现。以下是一些获取数字货币历史行情数据的方法: 1 CoinGecko API CoinGecko是一个数字货币市场数据