AMD的三代服务器CPU都属于7000系列大锅,那么您如何知道要购买的产品呢? 只要看一下右边的最后一个数字,数字1代表第一代那不勒斯EPYC,数字2代表罗马型号,数字3代表新米兰产品。 始终从右到左,第二个数字是性能指标。 在这种情况下,它可以是1、4、6或F。这三个数字表示各种性能步骤,其中6表
目录 一、配置Nginx隐藏版本号1、第一种方法修改配置文件2、第二种方法修改源码文件,重新编译安装 二、修改Nginx用户与组三、配置Nginx网页缓存时间四、实现Nginx的日志分割五、配置Nginx实现连接超时六、更改Nginx运行进程数七、配置Nginx实现网页压缩功能八、配置Nginx防盗
开篇 📜 引言: 磨刀不误砍柴工 工欲善其事必先利其器 K8S 集群规模,有的公司倾向于少量大规模 K8S 集群,也有的公司会倾向于大量小规模的 K8S 集群。 如果是第二种情况,是否有一个简单的 kubectl 命令来获取一个 kubeconfig 文件并将其合并到 ~/.kube/config
根据给定的Node树节点,返回包含按级别排序的树中元素的列表,这意味着根元素位于第一位,然后根子元素(从左到右)位于第二位和第三位,依此类推。 1 public class Node 2 { 3 public Node Left; 4 public Node Right; 5 public int
编写一个函数/方法,它接受2个参数、一个字符串和轨道数,并返回ENCODED字符串。 编写第二个函数/方法,它接受2个参数、一个编码字符串和轨道数,并返回DECODED字符串。 然后使用围栏密码对其进行解码。 这种密码用于通过将每个字符沿着一组“竖状轨道”依次放在对角线上来对字符串进行编码。首先开始
# 前言 本篇其实是承接前面两篇的,都是讲定位线上的c3p0数据库连接池,发生连接泄露的问题。 第二篇讲到,可以配置两个参数,来找出是哪里的代码借了连接后没有归还。但是,在我这边的情况是,对于没有归还的连接,借用者的堆栈确实是打印到日志了,但是我在本地模拟的时候,发现其实这些场景是有归还连接的,所以
插入排序实现原理 插入排序算法是一种简单、直观的排序算法,其原理是将一个待排序的元素逐个地插入到已经排好序的部分中。 具体实现步骤如下 首先咱们假设数组长度为n,从第二个元素开始,将当前元素存储在临时变量temp中。 从当前元素的前一个位置开始向前遍历,比较temp与每个已排序元素的值大小。 如果已
# springboot jar thin springboot 应用 jar 瘦身。springboot jar 太大。jar与依赖包分离。 两种方法,第一种,spring-boot-thin-launcher,他将依赖包以maven仓库的形式放到repository目录。 第二种,将依赖包以ja
Gavvmal springboot 官方文档说明了两种方式,一种使用插件,直接生成docker镜像,但是这需要本地安装docker环境,但是无论用windows还是mac,本地安装docker都感觉不好,太占用资源。 第二种方法,安装Gavvmal,下载相应版本的压缩包,可以把这个压缩版看做一个J
生活规划 0. 我希望近期做掉的事情(DDL: 2023.10.14 23:30) 最优化方法回看 物理实验报告+预习报告 (DDL: 2023.10.12) 笛卡尔第二个沉思 (DDL: 2023.10.12) 学物理 看计组:指令集 看计组/caaqa:存储器层次 看计组:补之前的笔记 组合数学
无状态和有状态 无状态 Deployment 认为Pod 都是一样的。javademo1-6fb64c4664-dj4dh、javademo1-6fb64c4664-dj54s 它们的内容是一样的。 没有顺序要求,先启第一个还是启第二个无所谓 不用考虑在哪个 node 上运行 随意进行伸缩和扩展 有
ES 对 from + size 有限制,两者之和不能超过1W Scroll查询方式,不适合做实时的查询,每次都是从数据文档中的ID去获取,效果高了,但文档中的ID(第二步)不是实时更新的,一般后台管理的方式用 Scroll 比较方便
[TOC] 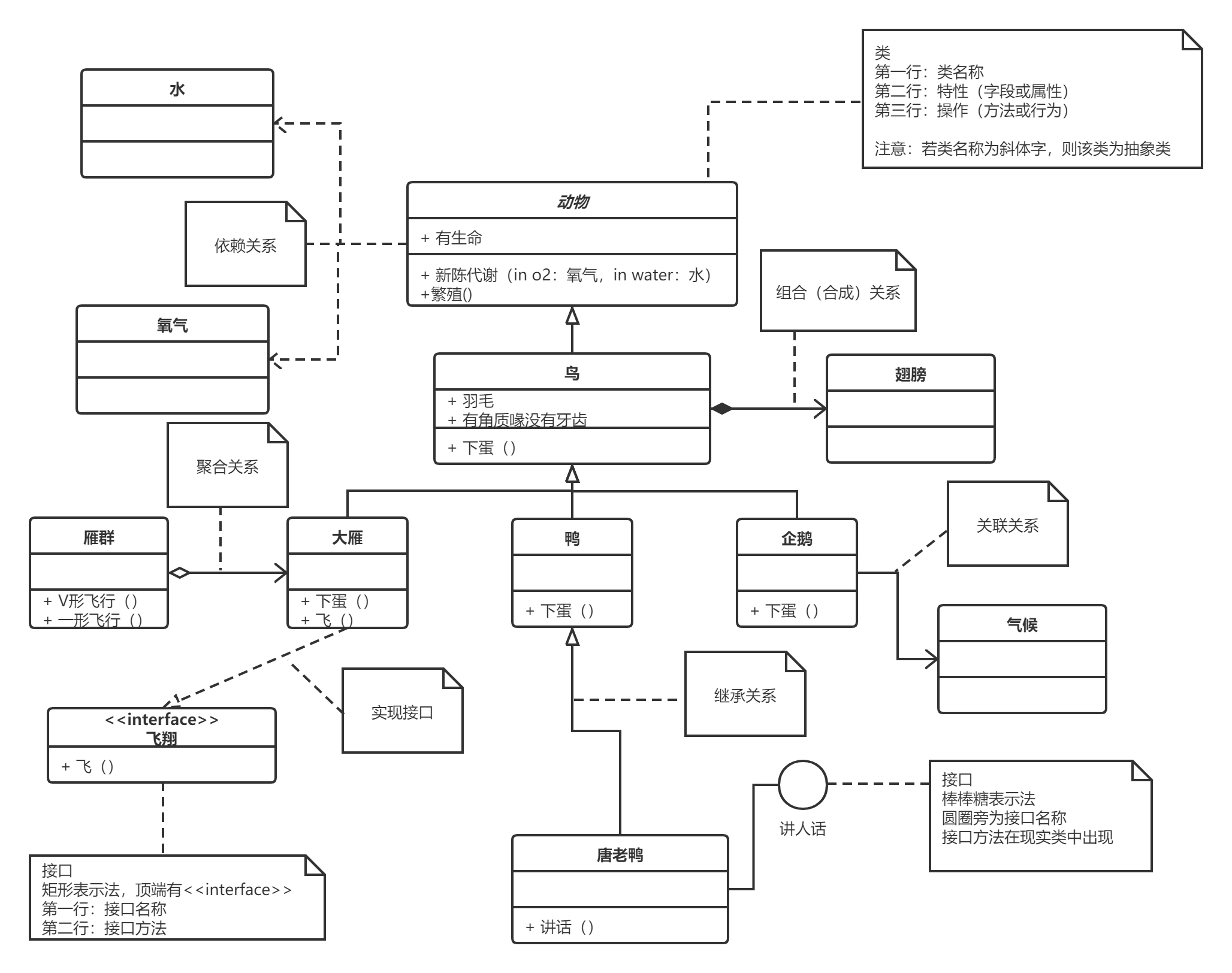 ## 类的表示(Class) 第一层:显示类的名称,如果是抽象类,则就用斜体显示。 第二层:是类的
作者:郑志杰 mybatis 操作数据库的过程 // 第一步:读取mybatis-config.xml配置文件 InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml"); // 第二步:构建SqlSes
背景 系统需要交付,客户要求提供交维材料,包括系统的表结构,安排开发人员进行梳理,效率比较慢,遂自己花点时间捣鼓一下,发现有此插件,记录一下方便与同事分享 前提条件 必须有 go语言环境,有的话直接看第二点 一、安装 go语言环境 1、检查本机是否安装 go go version 2、如果没有,安装
1.简介 有些测试场景或者事件,playwright根本就没有直接提供方法去操作,而且也不可能把各种测试场景都全面覆盖提供方法去操作。比如:就像鼠标悬停,一般测试场景鼠标悬停分两种常见,一种是鼠标悬停在某一个元素上方,然后会出现下拉子菜单,第二种就是在搜索输入过程,选择自动补全的字段。关于鼠标悬停,
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是《Strimzi Kafka Bridge(桥接)实战之》系列的第二篇,咱们直奔bridge的重点:常用接口,用实际操作体验如何用brid
什么是单例模式 单例模式 (Singleton Pattern)又称为单体模式,保证一个类只有一个实例,并提供一个访问它的全局访问点。也就是说,第二次使用同一个类创建新对象的时候,应该得到与第一次创建的对象完全相同的对象。 简单的说就是保证一个类仅有一个实例,并提供一个访问它的全局访问点,这样的模式
一:背景 1. 讲故事 前段时间有位朋友微信找到我,说他的程序使用 hsl 库之后,采集 plc 时内存溢出,让我帮忙看一下怎么回事,哈哈,貌似是分析之旅中的第二次和 hsl 打交道,既然找到我,那就上 windbg 说话吧。 二:WinDbg 分析 1. 为什么会内存溢出 简单观察程序的提交内存之
转载请注明出处: 1.交换机与路由器 交换机与路由器的特点: 交换机(Switch): 用于在局域网中传输数据帧 基于MAC地址进行转发和过滤 工作在数据链路层(第二层) 具有多个端口,可以连接多台计算机或其他网络设备 支持全双工通信,提供高速的内部数据传输 路由器(Router): 用于在不同网络