摘要:openGemini的设计和优化都是根据时序数据特点而来,在面对海量运维监控数据处理需求时,openGemini显然更加有针对性。 IT运维诞生于最早的信息化时代。在信息化时代,企业的信息化系统,主要为了满足企业内部管理的需求。通常是集中、可控和固化的烟囱式架构。传统IT运维,以人力运维为主,
摘要:如流水般源源不断的数据都存放在哪里?云原生数据库到底是什么?企业基于云原生数据库如何随取随用,实现从 “上好云” 到 “用好云” 的跨越发展? 本文分享自华为云社区《探秘・云新知丨华为云解锁云原生数据库发展新动能》,作者:华为云头条 。 伴随数字化转型步入 “深水区”,企业的业务需求迭代迅速,
摘要:为了持续打造核心竞争力,英克康健联合华为云,基于云数据库RDS for PostgreSQL全新打造了一个高性能、大容量、高可用的SaaS医药管理系统,助力万千药企业务迈上新台阶。 乘借数字化东风,医药行业呈现出一片欣欣向荣之景。作为一家高新技术企业,北京英克康健科技有限公司(简称“英克康健”
摘要:通过云服务形式提供数据库功能的云数据库应运而生,但这还仅仅是数据库变革的开端。 本文分享自华为云社区《透视华为云云原生数据库的前世今生及未来演进,能给行业带来哪些启发?》,作者:万佳。 自云计算出现后,风云变幻十余载,硬件、软件行业都经历了重构变革所带来的机遇与激荡。企业 IT 基础设施逐渐云
摘要:斯坦福教授、Tcl语言发明者John Ousterhout的著作《A Philosophy of Software Design》提出了一个经久不衰的观点——软件设计的核心在于降低复杂性。 在新技术不断涌现的云时代,出现了一种“技术过载”现象——本应帮助企业提高效率的技术,反倒让企业心生焦虑,
摘要:华为云数据库营销专家Tony Chen和华为云数据库高级产品经理佳恩开展了一场关于云原生数据库与Serverless结合的直播对话。 云计算的迅猛发展推动了数据库的变革,云原生数据库成为当前数据库发展的重要方向之一。云原生数据库与Serverless的结合,则进一步加速了云原生数据库的演进。虽
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说)、深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云。更多精彩内容请单击此处。 摘要: GaussDB(DWS)支持根据业务系统的不同使用需求,对膨胀的数据进行冷热分级管理,将数据按照时间分为热数据、冷数
索引虽然能加速查询,但是会降低写操作的性能,以及耗费更多的磁盘空间。所以建立索引之前需要考虑是不是必要的。
SQL Server 2016 安装 数据库—属性—权限—选择用户或角色—勾选执行权限即可。
Secret 作用:加密数据(base64)存在 etcd 里面,让 Pod 容器以挂载 Volume 方式进行访问 场景:凭证 [root@k8smaster ~]# echo -n 'admin' | base64 # 创建 secret [root@k8smaster ~]# kubectl
作用:存储不加密数据到 etcd,让 Pod 以变量或者 Volume 挂载到容器中 场景:配置文件 创建配置文件 redis.properties redis.host=127.0.0.1 redis.port=6379 redis.password=123456 创建 ConfigMap # 根
Axhub Charts图表元件库: https://www.axureshop.com/a/100749.html
[Window bat expdp 数据库定时任务逻辑备份数据库 定时删除N天前的旧文件](https://www.cnblogs.com/vipsoft/p/6074077.html) [Linux shell crontab expdp 定时任务逻辑备份数据库 定时删除旧文件](https://
``` #输入查看数据库连接 neo4j$ :server status ``` 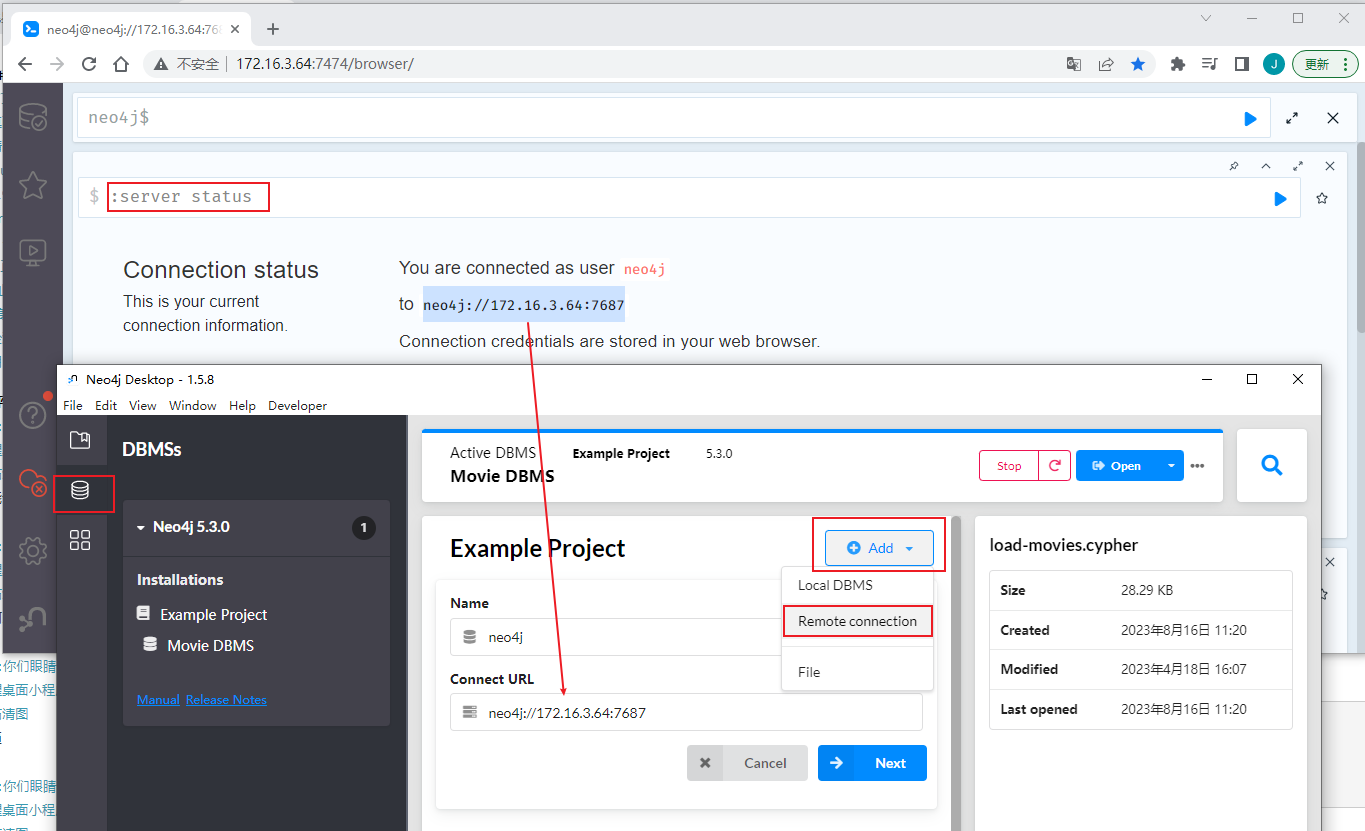 添加 远程连接,输入连接地址 !
### 前提条件 - 先往Neo4j 里,准备数据 参考:https://www.cnblogs.com/vipsoft/p/17631347.html#%E5%88%9B%E5%BB%BA%E4%BC%A0%E6%89%BF%E4%BA%BA - 搭建 FastAPI 项目:https://www
目录症状数据创建节点附学习 电子病历中,患者主诉对应的相关检查,得出的诊断以及最后的用药情况。症状一般可以从主诉中提取。 症状数据 symptom_data.csv CSV 中,没有直接一行一个症状,主要想后面将 症状 => 疾病 做关联,最后会在一个 Excel 中表达 所以每行实际对应一个症病,
目录饮食数据创建节点 根据疾病、症状,判断出哪些饮食不能吃,哪些建议多吃 饮食数据 foods_data.csv 建议值用“”引起来。避免中间有,号造成误识别 饮食 "辣椒" "大蒜" "芥末" "海鲜" "胡萝卜" "核桃仁" "菠菜" "西红柿" "香蕉" 创建节点 重构代码,将 def exe
使用场景: 由于表数据量巨大,导致一些统计相关的sql执行非常慢,使用户有非常不好的体验,并且sql和数据库已经没有优化空间了。(并且该统计信息数据实时性要求不高的前提下) 解决方案: 整体思路:创建预处理表——通过定时任务将数据插入到结果表——统计信息时直接通过结果表进行查询——大大提高响应速度
在表数据量很大的时候直接添加字段,以及其他表结构修改,会严重影响线上使用,而且耗费时间很长;使用这个工具可以很好的在线修改表结构。 好处: 降低主从延时的风险 可以限速、限资源,避免操作时MySQL负载过高 建议: 在业务低峰期做,将影响降到最低 直接原表修改缺点: 当表的数据量很大的时候,如果直接
mysql查询上季度数据 最近接口需要统计上个季度的数据统计,补一下sql 季度函数: QUARTER(date) 函数返回给定日期值(1到4之间的数字)的一年中的季度 语法: QUARTER(date) | 参数 | 描述 | | | | | date | 必须项。从中提取季度的日期或日期时间 |