摘要:反向传播指的是计算神经网络参数梯度的方法。
本文分享自华为云社区《反向传播与梯度下降详解》,作者:嵌入式视觉 。
神经网络训练过程是:
以上步骤如此反复多次,一直到预测结果和真实结果之间相差无几,亦即 ∣a−y∣→0,则训练结束。
前向传播(forward propagation 或 forward pass)指的是: 按顺序(从输入层到输出层)计算和存储神经网络中每层的结果。
为了更深入理解前向传播的计算过程,我们可以根据网络结构绘制网络的前向传播计算图。下图是简单网络与对应的计算图示例:
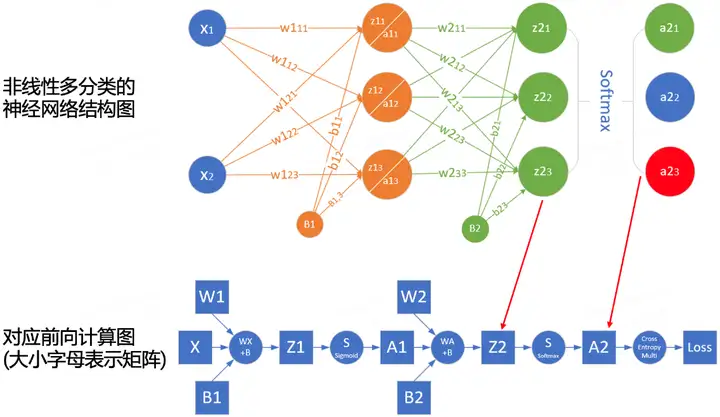
其中正方形表示变量,圆圈表示操作符。数据流的方向是从左到右依次计算。
反向传播(backward propagation,简称 BP)指的是计算神经网络参数梯度的方法。其原理是基于微积分中的链式规则,按相反的顺序从输出层到输入层遍历网络,依次计算每个中间变量和参数的梯度。
梯度的自动计算(自动微分)大大简化了深度学习算法的实现。
注意,反向传播算法会重复利用前向传播中存储的中间值,以避免重复计算,因此,需要保留前向传播的中间结果,这也会导致模型训练比单纯的预测需要更多的内存(显存)。同时这些中间结果占用内存(显存)大小与网络层的数量和批量(batch_size)大小成正比,因此使用大 batch_size 训练更深层次的网络更容易导致内存不足(out of memory)的错误!
大多数深度学习算法都涉及某种形式的优化。优化器的目的是更新网络权重参数,使得我们平滑地到达损失面中损失值的最小点。
深度学习优化存在许多挑战。其中一些最令人烦恼的是局部最小值、鞍点和梯度消失。
在深度学习中,大多数目标函数都很复杂,没有解析解,因此,我们需使用数值优化算法,本文中的优化算法: SGD 和 Adam 都属于此类别。
梯度下降(gradient descent, GD)算法是神经网络模型训练中最为常见的优化器。尽管梯度下降(gradient descent)很少直接用于深度学习,但理解它是理解随机梯度下降和小批量随机梯度下降算法的基础。
大多数文章都是以“一个人被困在山上,需要迅速下到谷底”来举例理解梯度下降法,但这并不完全准确。在自然界中,梯度下降的最好例子,就是泉水下山的过程:
示例参考 AI-EDU: 梯度下降。
梯度下降的数学公式:
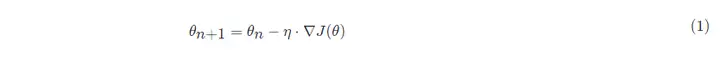
其中:
下图展示了梯度下降法的步骤。梯度下降的目的就是使得 x 值向极值点逼近。
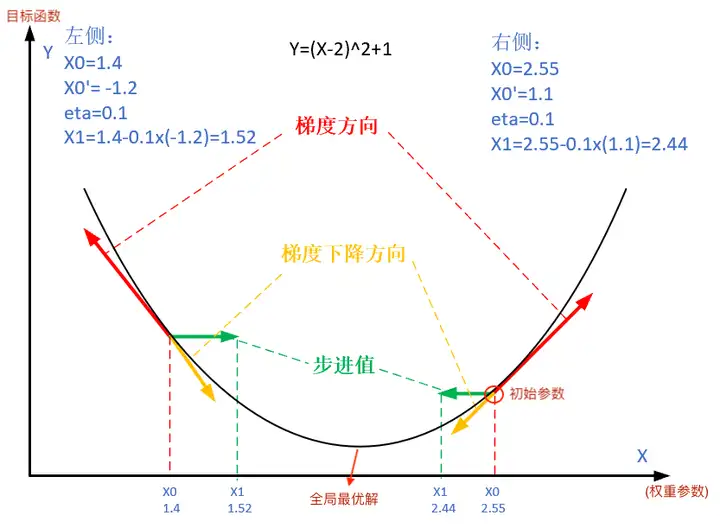

由于是双变量,所以梯度下降的迭代过程需要用三维图来解释。表2可视化了三维空间内的梯度下降过程。
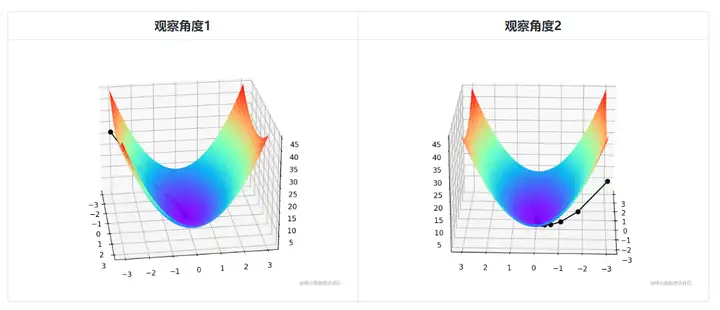
图中间那条隐隐的黑色线,表示梯度下降的过程,从红色的高地一直沿着坡度向下走,直到蓝色的洼地。
双变量凸函数 J(x,y)=x2+2y2的梯度下降优化过程以及可视化代码如下所示:
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D def target_function(x,y): J = pow(x, 2) + 2*pow(y, 2) return J def derivative_function(theta): x = theta[0] y = theta[1] return np.array([2*x, 4*y]) def show_3d_surface(x, y, z): fig = plt.figure() ax = Axes3D(fig) u = np.linspace(-3, 3, 100) v = np.linspace(-3, 3, 100) X, Y = np.meshgrid(u, v) R = np.zeros((len(u), len(v))) for i in range(len(u)): for j in range(len(v)): R[i, j] = pow(X[i, j], 2)+ 4*pow(Y[i, j], 2) ax.plot_surface(X, Y, R, cmap='rainbow') plt.plot(x, y, z, c='black', linewidth=1.5, marker='o', linestyle='solid') plt.show() if __name__ == '__main__': theta = np.array([-3, -3]) # 输入为双变量 eta = 0.1 # 学习率 error = 5e-3 # 迭代终止条件,目标函数值 < error X = [] Y = [] Z = [] for i in range(50): print(theta) x = theta[0] y = theta[1] z = target_function(x,y) X.append(x) Y.append(y) Z.append(z) print("%d: x=%f, y=%f, z=%f" % (i,x,y,z)) d_theta = derivative_function(theta) print(" ", d_theta) theta = theta - eta * d_theta if z < error: break show_3d_surface(X,Y,Z)
注意!总结下,不同的步长 η ,随着迭代次数的增加,会导致被优化函数 J 的值有不同的变化:
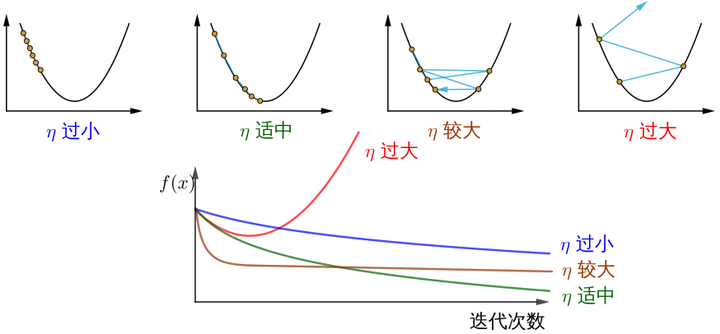
图片来源如何理解梯度下降法?。
在深度学习中,目标函数通常是训练数据集中每个样本的损失函数的平均值。如果使用梯度下降法,则每个自变量迭代的计算代价为 O(n),它随 n(样本数目)线性增⻓。因此,当训练数据集较大时,每次迭代的梯度下降计算代价将较高。
随机梯度下降(SGD)可降低每次迭代时的计算代价。在随机梯度下降的每次迭代中,我们对数据样本随机均匀采样一个索引 i,其中 i∈1,...,n,并计算梯度 ∇J(θ)以更新权重参数 θ:

每次迭代的计算代价从梯度下降的 O(n) 降至常数 O(1)。另外,值得强调的是,随机梯度 ∇Ji(θ) 是对完整梯度 ∇J(θ) 的无偏估计。
无偏估计是用样本统计量来估计总体参数时的一种无偏推断。
在实际应用中,随机梯度下降 SGD 法必须和动态学习率方法结合起来使用,否则使用固定学习率 + SGD的组合会使得模型收敛过程变得更复杂。
前面讲的梯度下降(GD)和随机梯度下降(SGD)方法都过于极端,要么使用完整数据集来计算梯度并更新参数,要么一次只处理一个训练样本来更新参数。在实际项目中,会对两者取折中,即小批量随机梯度下降(minibatch gradient descent),使用小批量随机梯度下降还可以提高计算效率。
小批量的所有样本数据元素都是从训练集中随机抽出的,样本数目个数为 batch_size(缩写 bs)
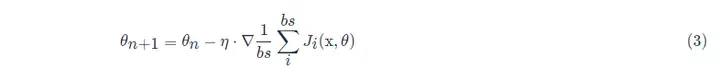
另外,一般项目中使用 SGD 优化算法都默认会使用小批量随机梯度下降,即 batch_size > 1,除非显卡显存不够了,才会设置 batch_size = 1。