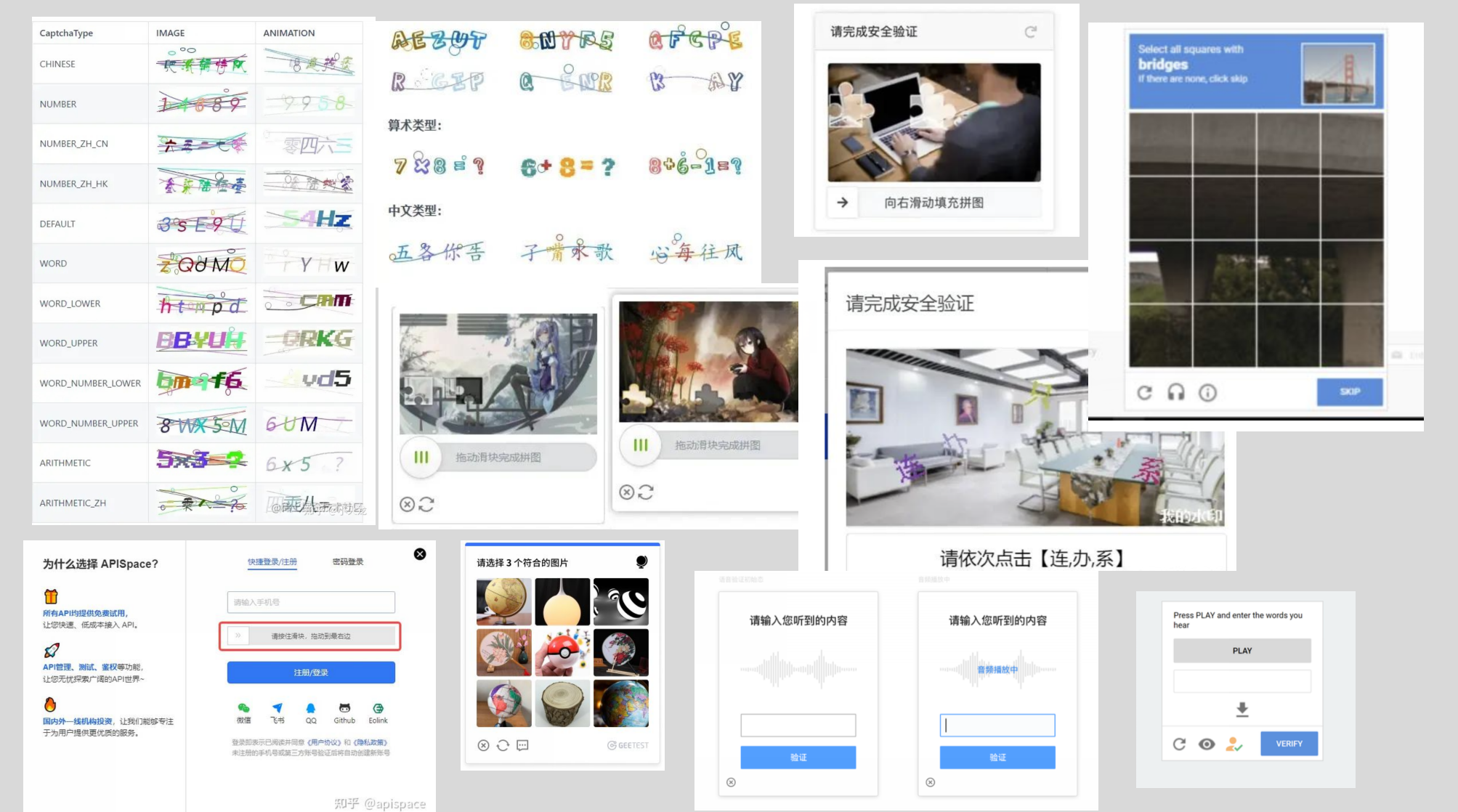
验证码(CAPTCHA),全称为"Completely Automated Public Turing test to tell Computers and Humans Apart",是一种区分用户是计算机还是人的公共全自动程序。最初,验证码主要是一些混杂字母和数字的图片,但随着技术的发展,出现了更多种类的验证码,例如reCAPTCHA、GeeTest拼图验证码、hCaptcha、KeyCaptcha等。
Normal CAPTCHA是一种常见的验证码类型,它包含字母和数字的图片进行扭曲和变形。
清晰文字问题的验证码主要是对问题的理解和答案的回答,比如“What is the capital of China?”,回答应该是“Beijing”。
这种验证码要求用户旋转一个3D物体到正确的方向。
reCAPTCHA V2是Google开发的验证码系统,要求用户选择一组与给定主题相关的图像。
GeeTest验证码是一种常见的滑动拼图验证码,用户需要将一个不完整的图像拼凑完整
hCaptcha是一种验证人类的验证码,要求用户选择与给定主题相关的答案。
KeyCaptcha是一种交互式验证码,需要用户进行一些操作,比如拖动一个物体到指定位置。
Capy是另一种拼图验证码,它将一个图像切分成多个小块,需要用户通过拖动小块拼凑成完整的图像。
Grid法验证码是一种基于网格的图像识别验证码,要求用户识别网格中的特定对象或图案。
Canvas验证码是一种在HTML5 canvas元素中绘制的验证码,它可以是文本,也可以是图像。
ClickCaptcha会返回验证码图片的点坐标,用户需要根据这些坐标点击正确的位置。
https://cn.2captcha.com/



| 验证码类型 | 每 1000 人的费率 | 描述 |
|---|---|---|
| Normal Captcha, Text Captcha | 0.5−1 | 费率是灵活的,取决于服务的当前负载。 您可以在帐户设置中查看当前速率和限制最大速率。 |
| reCAPTCHA V2 | $2.99 | 该费率适用于通过令牌解决的 Google 的 reCAPTCHA V2。 |
| reCAPTCHA V3 | 1.45,2.99 | score <= 0.3, score > 0.3 |
| reCAPTCHA Enterprise | $2.99 | 该费率适用于 Google 的 reCAPTCHA Enterprise。 |
| Geetest | $2.99 | 该费率适用于 Geetest 验证码。 |
| Grid Method, Coordinates | $1.20 | 该费率适用于您需要单击图像的任何验证码。 |
| RotateCaptcha | $0.50 | 该费率适用于您需要旋转图像的任何验证码。 |
| Arkose Labs FunCaptcha Token Method | $2.99 | 该费率适用于通过令牌解决的 Arkose Labs FunCaptcha。 |
| KeyCaptcha | $2.99 | 该费率适用于 KeyCaptcha。 |
| hCaptcha | $2.99 | 该费率适用于 hCaptcha。 |
| Capy | $2.99 | 该费率适用于 Capy。 |
| TikTok | $2.99 | 该费率适用于 TikTok captcha。 |
https://cn.2captcha.com/
官网提供了众多的代码脚本 https://cn.2captcha.com/for-customer

pip3 install 2captcha-python
代码GitHub链接:https://github.com/2captcha/2captcha-python
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.realpath(__file__))))
from twocaptcha import TwoCaptcha
api_key = os.getenv('APIKEY_2CAPTCHA', 'YOUR_API_KEY')
solver = TwoCaptcha(api_key)
try:
result = solver.recaptcha(
sitekey='6LfD3PIbAAAAAJs_eEHvoOl75_83eXSqpPSRFJ_u',
url='https://2captcha.com/demo/recaptcha-v2')
except Exception as e:
sys.exit(e)
else:
sys.exit('solved: ' + str(result))
验证码的难度随着技术发展越来越高,2Captcha服务可以有效帮助爬虫绕过验证码限制,开发集成简单,推荐使用。