梦想照进现实,微软果然不愧是微软,开源了贾维斯(J.A.R.V.I.S.)人工智能助理系统,贾维斯(jarvis)全称为Just A Rather Very Intelligent System(只是一个相当聪明的人工智能系统),它可以帮助钢铁侠托尼斯塔克完成各种任务和挑战,包括控制和管理托尼的机甲装备,提供实时情报和数据分析,帮助托尼做出决策等等。
如今,我们也可以拥有自己的贾维斯人工智能助理,成本仅仅是一块RTX3090显卡。
一般情况下,深度学习领域相对主流的入门级别显卡是2070或者3070,而3090可以算是消费级深度学习显卡的天花板了:
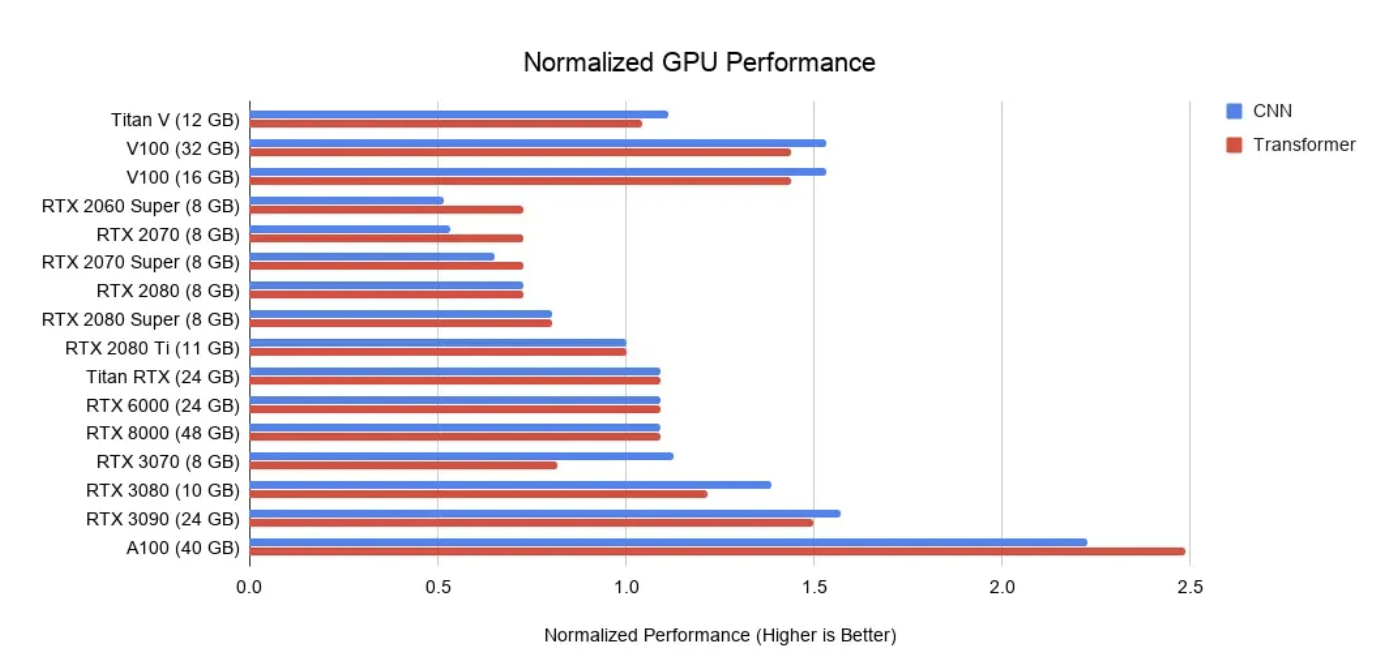
再往上走就是工业级别的A系列和V系列显卡,显存是一个硬指标,因为需要加载本地的大模型,虽然可以改代码对模型加载进行“阉割”,但功能上肯定也会有一定的损失。如果没有3090,也可以组两块3060 12G的并行,显存虽然可以达标,但算力和综合性能抵不过3090。
确保本地具备足以支撑贾维斯(Jarvis)的硬件环境之后,老规矩,克隆项目:
git clone https://github.com/microsoft/JARVIS.git
随后进入项目目录:
cd JARVIS
修改项目的配置文件 server/config.yaml:
openai:
key: your_personal_key # gradio, your_personal_key
huggingface:
cookie: # required for huggingface inference
local: # ignore: just for development
endpoint: http://localhost:8003
dev: false
debug: false
log_file: logs/debug.log
model: text-davinci-003 # text-davinci-003
use_completion: true
inference_mode: hybrid # local, huggingface or hybrid
local_deployment: minimal # no, minimal, standard or full
num_candidate_models: 5
max_description_length: 100
proxy:
httpserver:
host: localhost
port: 8004
modelserver:
host: localhost
port: 8005
logit_bias:
parse_task: 0.1
choose_model: 5
这里主要修改三个配置即可,分别是openaikey,huggingface官网的cookie令牌,以及OpenAI的model,默认使用的模型是text-davinci-003。
修改完成后,官方推荐使用虚拟环境conda,Python版本3.8,私以为这里完全没有任何必要使用虚拟环境,直接上Python3.10即可,接着安装依赖:
pip3 install -r requirements.txt
项目依赖库如下:
git+https://github.com/huggingface/diffusers.git@8c530fc2f6a76a2aefb6b285dce6df1675092ac6#egg=diffusers
git+https://github.com/huggingface/transformers@c612628045822f909020f7eb6784c79700813eda#egg=transformers
git+https://github.com/patrickvonplaten/controlnet_aux@78efc716868a7f5669c288233d65b471f542ce40#egg=controlnet_aux
tiktoken==0.3.3
pydub==0.25.1
espnet==202301
espnet_model_zoo==0.1.7
flask==2.2.3
flask_cors==3.0.10
waitress==2.1.2
datasets==2.11.0
asteroid==0.6.0
speechbrain==0.5.14
timm==0.6.13
typeguard==2.13.3
accelerate==0.18.0
pytesseract==0.3.10
gradio==3.24.1
这里web端接口是用Flask2.2高版本搭建的,但奇怪的是微软并未使用Flask新版本的异步特性。
安装完成之后,进入模型目录:
cd models
下载模型和数据集:
sh download.sh
这里一定要做好心理准备,因为模型就已经占用海量的硬盘空间了,数据集更是不必多说,所有文件均来自huggingface:
models="
nlpconnect/vit-gpt2-image-captioning
lllyasviel/ControlNet
runwayml/stable-diffusion-v1-5
CompVis/stable-diffusion-v1-4
stabilityai/stable-diffusion-2-1
Salesforce/blip-image-captioning-large
damo-vilab/text-to-video-ms-1.7b
microsoft/speecht5_asr
facebook/maskformer-swin-large-ade
microsoft/biogpt
facebook/esm2_t12_35M_UR50D
microsoft/trocr-base-printed
microsoft/trocr-base-handwritten
JorisCos/DCCRNet_Libri1Mix_enhsingle_16k
espnet/kan-bayashi_ljspeech_vits
facebook/detr-resnet-101
microsoft/speecht5_tts
microsoft/speecht5_hifigan
microsoft/speecht5_vc
facebook/timesformer-base-finetuned-k400
runwayml/stable-diffusion-v1-5
superb/wav2vec2-base-superb-ks
openai/whisper-base
Intel/dpt-large
microsoft/beit-base-patch16-224-pt22k-ft22k
facebook/detr-resnet-50-panoptic
facebook/detr-resnet-50
openai/clip-vit-large-patch14
google/owlvit-base-patch32
microsoft/DialoGPT-medium
bert-base-uncased
Jean-Baptiste/camembert-ner
deepset/roberta-base-squad2
facebook/bart-large-cnn
google/tapas-base-finetuned-wtq
distilbert-base-uncased-finetuned-sst-2-english
gpt2
mrm8488/t5-base-finetuned-question-generation-ap
Jean-Baptiste/camembert-ner
t5-base
impira/layoutlm-document-qa
ydshieh/vit-gpt2-coco-en
dandelin/vilt-b32-finetuned-vqa
lambdalabs/sd-image-variations-diffusers
facebook/timesformer-base-finetuned-k400
facebook/maskformer-swin-base-coco
Intel/dpt-hybrid-midas
lllyasviel/sd-controlnet-canny
lllyasviel/sd-controlnet-depth
lllyasviel/sd-controlnet-hed
lllyasviel/sd-controlnet-mlsd
lllyasviel/sd-controlnet-openpose
lllyasviel/sd-controlnet-scribble
lllyasviel/sd-controlnet-seg
"
# CURRENT_DIR=$(cd `dirname $0`; pwd)
CURRENT_DIR=$(pwd)
for model in $models;
do
echo "----- Downloading from https://huggingface.co/"$model" -----"
if [ -d "$model" ]; then
# cd $model && git reset --hard && git pull && git lfs pull
cd $model && git pull && git lfs pull
cd $CURRENT_DIR
else
# git clone 包含了lfs
git clone https://huggingface.co/$model $model
fi
done
datasets="Matthijs/cmu-arctic-xvectors"
for dataset in $datasets;
do
echo "----- Downloading from https://huggingface.co/datasets/"$dataset" -----"
if [ -d "$dataset" ]; then
cd $dataset && git pull && git lfs pull
cd $CURRENT_DIR
else
git clone https://huggingface.co/datasets/$dataset $dataset
fi
done
也可以考虑拆成两个shell,开多进程下载,速度会快很多。
但事实上,真的,别下了,文件属实过于巨大,这玩意儿真的不是普通人能耍起来的,当然选择不下载本地模型和数据集也能运行,请看下文。
漫长的下载流程结束之后,贾维斯(Jarvis)就配置好了。
如果您选择下载了所有的模型和数据集(佩服您是条汉子),终端内启动服务:
python models_server.py --config config.yaml
随后会在系统的8004端口启动一个Flask服务进程,然后发起Http请求即可运行贾维斯(Jarvis):
curl --location 'http://localhost:8004/hugginggpt' \
--header 'Content-Type: application/json' \
--data '{
"messages": [
{
"role": "user",
"content": "please generate a video based on \"Spiderman is surfing\""
}
]
}'
这个的意思是让贾维斯(Jarvis)生成一段“蜘蛛侠在冲浪”的视频。
当然了,以笔者的硬件环境,是不可能跑起来的,所以可以对加载的模型适当“阉割”,在models_server.py文件的81行左右:
other_pipes = {
"nlpconnect/vit-gpt2-image-captioning":{
"model": VisionEncoderDecoderModel.from_pretrained(f"{local_fold}/nlpconnect/vit-gpt2-image-captioning"),
"feature_extractor": ViTImageProcessor.from_pretrained(f"{local_fold}/nlpconnect/vit-gpt2-image-captioning"),
"tokenizer": AutoTokenizer.from_pretrained(f"{local_fold}/nlpconnect/vit-gpt2-image-captioning"),
"device": "cuda:0"
},
"Salesforce/blip-image-captioning-large": {
"model": BlipForConditionalGeneration.from_pretrained(f"{local_fold}/Salesforce/blip-image-captioning-large"),
"processor": BlipProcessor.from_pretrained(f"{local_fold}/Salesforce/blip-image-captioning-large"),
"device": "cuda:0"
},
"damo-vilab/text-to-video-ms-1.7b": {
"model": DiffusionPipeline.from_pretrained(f"{local_fold}/damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16"),
"device": "cuda:0"
},
"facebook/maskformer-swin-large-ade": {
"model": MaskFormerForInstanceSegmentation.from_pretrained(f"{local_fold}/facebook/maskformer-swin-large-ade"),
"feature_extractor" : AutoFeatureExtractor.from_pretrained("facebook/maskformer-swin-large-ade"),
"device": "cuda:0"
},
"microsoft/trocr-base-printed": {
"processor": TrOCRProcessor.from_pretrained(f"{local_fold}/microsoft/trocr-base-printed"),
"model": VisionEncoderDecoderModel.from_pretrained(f"{local_fold}/microsoft/trocr-base-printed"),
"device": "cuda:0"
},
"microsoft/trocr-base-handwritten": {
"processor": TrOCRProcessor.from_pretrained(f"{local_fold}/microsoft/trocr-base-handwritten"),
"model": VisionEncoderDecoderModel.from_pretrained(f"{local_fold}/microsoft/trocr-base-handwritten"),
"device": "cuda:0"
},
"JorisCos/DCCRNet_Libri1Mix_enhsingle_16k": {
"model": BaseModel.from_pretrained("JorisCos/DCCRNet_Libri1Mix_enhsingle_16k"),
"device": "cuda:0"
},
"espnet/kan-bayashi_ljspeech_vits": {
"model": Text2Speech.from_pretrained(f"espnet/kan-bayashi_ljspeech_vits"),
"device": "cuda:0"
},
"lambdalabs/sd-image-variations-diffusers": {
"model": DiffusionPipeline.from_pretrained(f"{local_fold}/lambdalabs/sd-image-variations-diffusers"), #torch_dtype=torch.float16
"device": "cuda:0"
},
"CompVis/stable-diffusion-v1-4": {
"model": DiffusionPipeline.from_pretrained(f"{local_fold}/CompVis/stable-diffusion-v1-4"),
"device": "cuda:0"
},
"stabilityai/stable-diffusion-2-1": {
"model": DiffusionPipeline.from_pretrained(f"{local_fold}/stabilityai/stable-diffusion-2-1"),
"device": "cuda:0"
},
"runwayml/stable-diffusion-v1-5": {
"model": DiffusionPipeline.from_pretrained(f"{local_fold}/runwayml/stable-diffusion-v1-5"),
"device": "cuda:0"
},
"microsoft/speecht5_tts":{
"processor": SpeechT5Processor.from_pretrained(f"{local_fold}/microsoft/speecht5_tts"),
"model": SpeechT5ForTextToSpeech.from_pretrained(f"{local_fold}/microsoft/speecht5_tts"),
"vocoder": SpeechT5HifiGan.from_pretrained(f"{local_fold}/microsoft/speecht5_hifigan"),
"embeddings_dataset": load_dataset(f"{local_fold}/Matthijs/cmu-arctic-xvectors", split="validation"),
"device": "cuda:0"
},
"speechbrain/mtl-mimic-voicebank": {
"model": WaveformEnhancement.from_hparams(source="speechbrain/mtl-mimic-voicebank", savedir="models/mtl-mimic-voicebank"),
"device": "cuda:0"
},
"microsoft/speecht5_vc":{
"processor": SpeechT5Processor.from_pretrained(f"{local_fold}/microsoft/speecht5_vc"),
"model": SpeechT5ForSpeechToSpeech.from_pretrained(f"{local_fold}/microsoft/speecht5_vc"),
"vocoder": SpeechT5HifiGan.from_pretrained(f"{local_fold}/microsoft/speecht5_hifigan"),
"embeddings_dataset": load_dataset(f"{local_fold}/Matthijs/cmu-arctic-xvectors", split="validation"),
"device": "cuda:0"
},
"julien-c/wine-quality": {
"model": joblib.load(cached_download(hf_hub_url("julien-c/wine-quality", "sklearn_model.joblib")))
},
"facebook/timesformer-base-finetuned-k400": {
"processor": AutoImageProcessor.from_pretrained(f"{local_fold}/facebook/timesformer-base-finetuned-k400"),
"model": TimesformerForVideoClassification.from_pretrained(f"{local_fold}/facebook/timesformer-base-finetuned-k400"),
"device": "cuda:0"
},
"facebook/maskformer-swin-base-coco": {
"feature_extractor": MaskFormerFeatureExtractor.from_pretrained(f"{local_fold}/facebook/maskformer-swin-base-coco"),
"model": MaskFormerForInstanceSegmentation.from_pretrained(f"{local_fold}/facebook/maskformer-swin-base-coco"),
"device": "cuda:0"
},
"Intel/dpt-hybrid-midas": {
"model": DPTForDepthEstimation.from_pretrained(f"{local_fold}/Intel/dpt-hybrid-midas", low_cpu_mem_usage=True),
"feature_extractor": DPTFeatureExtractor.from_pretrained(f"{local_fold}/Intel/dpt-hybrid-midas"),
"device": "cuda:0"
}
}
把不需要的模型屏蔽即可。
与此同时,还可以不通过本地服务接口,修改config.yaml的inference_mode: huggingface
随后直接在终端运行ChatGPT版本的贾维斯:
cd server
python3 awesome_chat.py --config config.yaml --mode cli
运行效果:
Welcome to Jarvis! A collaborative system that consists of an LLM as the controller and numerous expert models as collaborative executors. Jarvis can plan tasks, schedule Hugging Face models, generate friendly responses based on your requests, and help you with many things. Please enter your request (`exit` to exit).
[ User ]: Given a collection of image A: /examples/cat.jpg, B: /examples/z3.jpg, C: /examples/z1.jpg, please tell me how many zebras in these picture?
[ Jarvis ]: Based on your request, I have used several models to process the images you provided. For the image A: /examples/cat.jpg, I used the image-to-text model nlpconnect/vit-gpt2-image-captioning to generate the text "a cat sitting on a window sill looking out". Then I used the object-detection model facebook/detr-resnet-50 to generate the image with predicted box '/images/a3dc.jpg', which contains two objects with labels 'potted plant' and 'cat'. For the image B: /examples/z3.jpg, I used the image-to-text model nlpconnect/vit-gpt2-image-captioning to generate the text "two zebras standing in a field of dry grass". Then I used the object-detection model facebook/detr-resnet-50 to generate the image with predicted box '/images/f5df.jpg', which contains three objects with labels 'zebra'. For the image C: /examples/z1.jpg, I used the image-to-text model nlpconnect/vit-gpt2-image-captioning to generate the text "a zebra standing in a field of tall grass". Then I used the object-detection model facebook/detr-resnet-50 to generate the image with predicted box '/images/69c7.jpg', which contains one object with label 'zebra'. Finally, I used the canny-control model canny-control to generate the image '/images/7e18.png' based on the image /examples/savanna.jpg. Therefore, there are four zebras in these pictures. Is there anything else I can help you with?
[ User ]: Please answer all the named entities in the sentence: Iron Man is a superhero appearing in American comic books published by Marvel Comics. The character was co-created by writer and editor Stan Lee, developed by scripter Larry Lieber, and designed by artists Don Heck and Jack Kirby.
[ Jarvis ]: Sure, I understand your request. Based on the inference results of the models, I will answer your request step by step. Firstly, I used the token-classification model dslim/bert-base-NER to recognize the named entities in the sentence. The inference result is that the named entities are Iron Man, Stan Lee, Larry Lieber, Don Heck and Jack Kirby. Then, I used the question-answering model deepset/roberta-base-squad2 to answer your request. The inference result is that there is no output since the context cannot be empty. Therefore, I cannot make it. I hope this answer your request. Is there anything else I can help you with?
[ User ]: Please generate a canny image based on /examples/savanna.jpg
[ Jarvis ]: Sure. I have generated a canny image based on /examples/savanna.jpg. To do this, I first used the image-to-text model nlpconnect/vit-gpt2-image-captioning to generate the text description of the image, which is "a herd of giraffes and zebras grazing in a field". Then I used the canny-control model to generate the canny image of the original image, which is stored in the path "/images/1ea2.png". Finally, I used the canny-text-to-image model lllyasviel/sd-controlnet-canny to generate the canny image based on the text description and the canny image, which is stored in the path "/images/ba66.png". Do you need anything else?
可以理解为ChatGPT版本的文字生成图片,外面套了个贾维斯(Jarvis)的壳儿,演出效果满分。
总的来说,和微软之前开源的“可视化图形ChatGPT”一样,此类项目的象征意义要远远大于现实意义。贾维斯(Jarvis)代表的是大多数技术同仁的共同愿景,对于这类人工智能技术的发展,可以肯定,但由于硬件门槛过高的原因,短期内还不能过于期待。