https://zhuanlan.zhihu.com/p/432234496
本人lino,即将毕业的研究生,在此记录下学习过程。本次记录跟随是苏黎世邦理工大学的计算机体系结构课程。
相比于单核系统,在多核系统里面,我们想要的是:
N times the system performance with the N times the cores.
但是在多核的机器上,两个各自在不同核上跑的程序,理论上运行的速度应该跟它们在各自在单核机器上跑的速度差不多。然而现实情况却是程序的运行速度会大幅度下降,性能也下降好几倍。
下面是Onur Mutlu大佬讲课时做的实验,他们跑两个程序在双核的机器上,并且计算每个程序相比于独自跑一个程序会下降多少。core0跑matlab同时core1跑gcc,相比于单核去跑matlab,它的performance下降了仅0.07,没有下降太多,但gcc相比于单核去跑它的performance下降了3x,不符合上面提到的“N times the system performance with the N times the cores”。针对这个问题大佬引出在操作系统中可能存在优先级,并且改变matlab为低优先级,gcc为高优先级,但是发现nothing change。

接下来大佬继续深挖并提出了三个问题:
why is there slowdown?
why is there disparity in slowdowns?
how can we solve this problem if we do not want that disparity?
然后抽象了系统的架构:
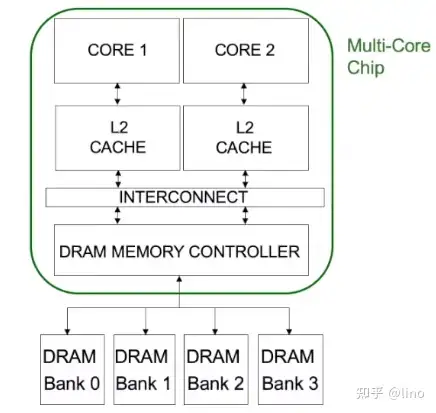
DRAM system 共享于core1以及core2。当运行matlab以及gcc时,matlab会向DRAM传输的十分密集,并且miss L2 Cache的非常多,以streaming的方式通过memory,而gcc确以很少的request通过dram controller。因此matlab的performance下降不多,而gcc由于poor request single is getting delayed behind matlab's request for 导致其performance下降的多。因此产生memory controller 的unfair问题。于是继续深挖,memory controller。
每个memory bank抽象成行列的二维矩阵,我们想要获取某一个block的信息时,是先通过Row Address Decoder获取第row行的数据,放在一个叫ROW BUFFER的地方,然后再Column Decoder获取第row行第col列的数据。
假设memory controller 接受控制器的请求row0,column0,首先row address0 进行decode,and then row 0 is activated,意味着dram将row0放入了row buffer,然后memory controller发送column0给dram bank,通过column mux选择column0。当该请求完成时,接着发送row0,column1,此时的row0是activated,因此直接从column mux选择出column1。
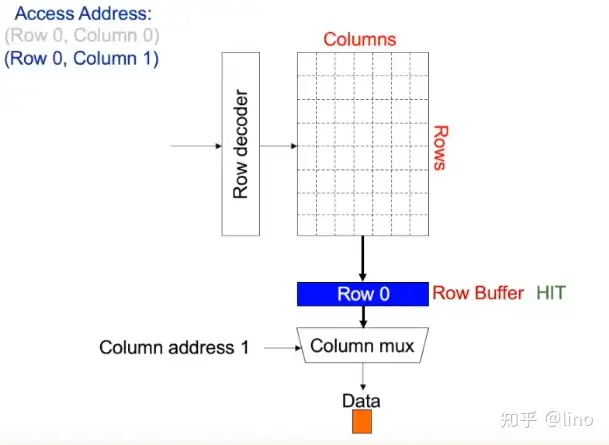
当新的请求是row1,column0时,首先进行pre-charge(相当于把row0 clear),然后再activate row1。
然后总结如下:
A row-conflict memory access takes significantly longer than a row-hit access
Current controllers take advantage of this fact
Commonly used scheduling policy(FR-FCFS)---first ready,first come,first server
首先由于CPU比memory的处理速度快,因此会有很多requests,并存入一个buffer中,并且遵循一个优先级的顺序,如果这个request是high row-buffer locality(即 row-hit的requerst)就优先处理这个request,如果nothing is a row-hits,那么就处理待在缓冲区里时间更长的request。这样做的目的在于保障DRAM拥有最大的throughout。
总结如下:
Row-hit first:unfairly prioritizes apps with high row buffer locality
Threads that keep on accessign the same row
Oldest-first:unfairly prioritizes memory-intensive applications
因此这个policy是个unfair的。接下来举了high/low row buffer locality的例子如下。
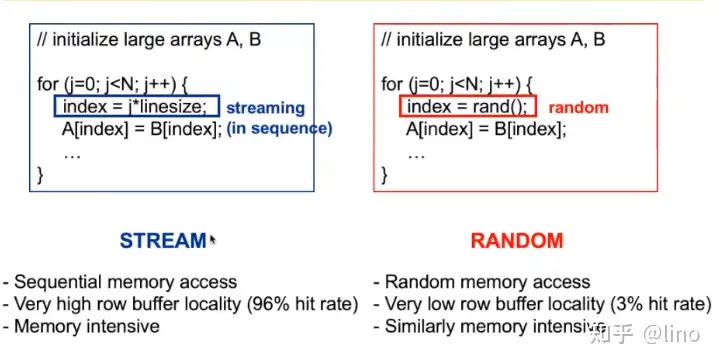
左边这个有high row buffer locality因为这是一个stream,有着memory intensive因为index = j* linesize使得cache miss很普遍。

并且假设row size大小为8k,requerst size大小为64B,那么就先服务128次左边的程序,然后在服务右边的程序。这就造成了很大的延时。实际的performance如下。

然后讨论了解决方法,分别从programmer、System software,Compiler,Memory controller以及DRAM进行探讨。
然后推荐读物:
Memory Performance Attacks:Denial of Memory Service in Multi-Core Systems