问题现象
1、远程Oracle数据库通过IP:PORT/SERVICE_NAME连接
2、应用服务通过Docker容器部署,访问Oracle联通性测试接口,需要50s左右才能返回连接成功;
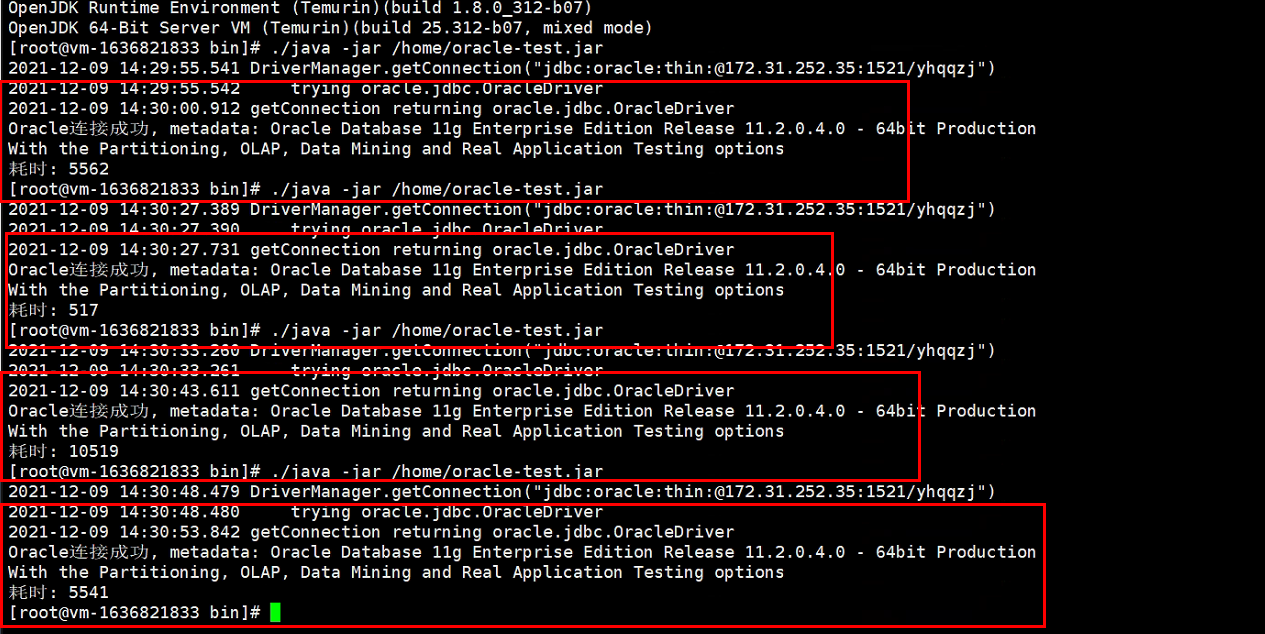
3、写了个JDBC测试程序,放在宿主机进行JDBC连接Oracle数据库测试,发现连接耗时不稳定,时快时慢,下图为宿主机连接数据库耗时截图;
4、通过Windows运维机器安装Navicat客户端,连接目标Oracle数据库,连接速度很快;
5、Linux宿主机安装SQLPLUS客户端,连接目标Oracle数据库,连接速度很快;
初步排查
看了很多技术博客,基本都是将file:/dev/random修改为file:/dev/urandom、file:/dev/./urandom、file:/dev/../dev/urandom等,实测无效,可能碰到的不是一个问题
问题定位
排查到DNS时,发现宿主机DNS配置清空后,通过JDBC连接目标Oracle数据库速度很快
进入容器中进行测试,发现清空DNS配置后连接速度也很快了,至此问题解决
清空DNS配置命令:echo > /etc/resolv.conf