摘要:TDSC 2022发表了安全补丁识别最新的方案“Enhancing Security Patch Identification by Capturing Structures in Commits” (E-SPI)。
本文分享自华为云社区《【论文推荐】TDSC2022 安全补丁识别最新的方案E-SPI》,作者: 华为云软件分析Lab。
TDSC 2022发表了安全补丁识别最新的方案“Enhancing Security Patch Identification by Capturing Structures in Commits” (E-SPI),该方案同时考虑代码提交的Message和Changed Code的拓扑特征,通过实验表明,该方案超过了当前业界的SOTA,达到业界领先。
根据《2021年开源安全与风险分析报告》统计,平均每个代码仓含158个安全漏洞,84%的代码仓都至少存在1个安全漏洞。相比20年,21年高风险漏洞环比增长了11%。开源软件带来便利的同时,也引入了潜在的安全风险。大多数软件漏洞都在公开源组件被静默修复,这就导致集成它们的已部署软件无法及时更新,鉴于此,如何高效的识别开源组件的安全补丁成为学术界一个热门的问题。
最近几年,随着深度学习的飞速发展,基于深度学习的安全补丁识别模型快速提升了安全补丁识别模型的有效性。但是,目前大多数现有的安全补丁识别方案直接把代码提交修改的代码、提交信息当成Token,忽略了代码的结构信息,这篇文章提出了E-SPI模型,有效的利用了隐藏在提交中的结构信息,进一步提升识别模型的效果。
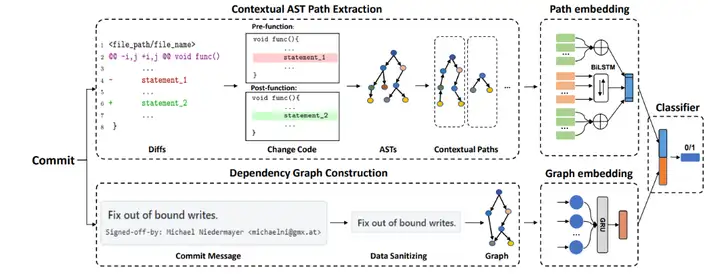
E-SPI整体的架构入上图所示,该方案分别对代码提交中的代码修改以及提交信息进行Embedding,最终联合两者的特征,来识别安全补丁。
代码修改编码器:对于代码提交中代码修改,该方案首先抽取代码修改前的函数Pre-function 和代码修改后的函数Post-function ;接着对着两个函数进行AST解析,为了适配序列模型的输入,该方案创新的提出了AST Path提取方法,将、对应AST的图转换成两类AST Paths:Within-context paths、Within-changes paths,其中Within-context paths代表AST树上开始的节点在修改代码中,结束节点不在修改的代码中的路径,Within-changes path代表AST树上开始和结束都在修改代码中的路径;最终以1:1的比例随机分别选取K个Within-context paths 和Within-context paths,来表征代码修改,输入Bi-LSTM完成代码修改的Embedding。

提交信息编码器:对于代码提交中的提交信息,该方案将原始的自言语言进行Dependency Graph解析,从而获取自言语言的依赖关系,针对该图结构,使用Gated Graph Neural Network完成编码。
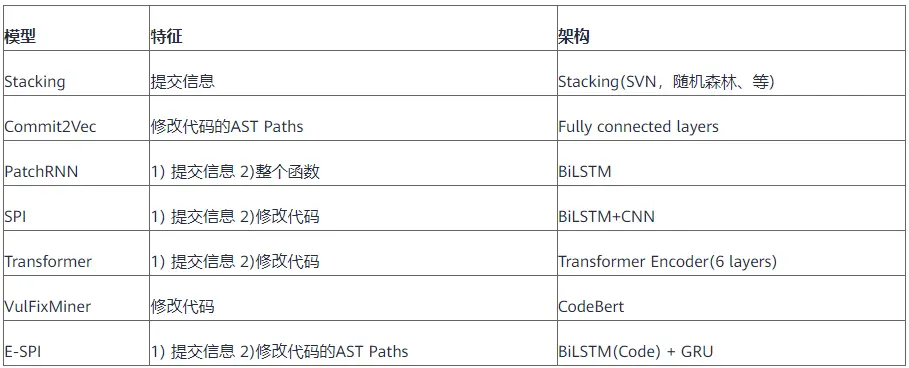
为了对比,这篇文章选取了学术界7个典型的安全补丁识别算法,这些模型主要的特征以及架构如下
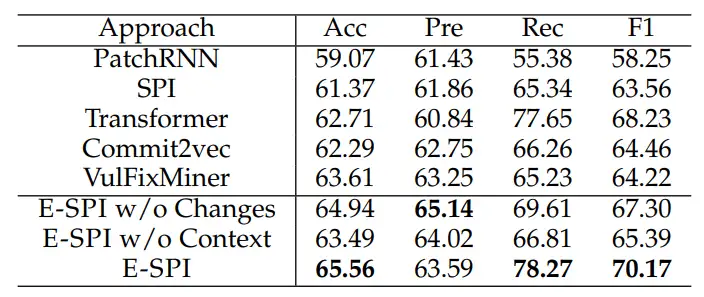
首先,这篇文章从整体上对所有的模型进行了比较,结果(见下图)显示E-SPI达到了SOTA,这表明,相对其他的方案,E-SPI能更好的对代码提交进行建模。通过进一步观察发现,代码提交信息是安全补丁识别问题的重要特征,加入提交信息的模型(Stacking、PatchRNN、SPI、Transformer、E-SPI)显著比没有加入代码提交信息的模型(Commit2Vec、VulFixMiner)要好,即使架构最简单的Stacking模型(添加了代码提交信息特征)也比只使用修改代码的模型Commit2Vec,VulFixMiner结果要好;另外可以发现,在特征相同的情况下,Transformer-Based的模型(Transformer)反而没有BiLSTM-Based的模型(PatchRNN,SPI,E-SPI)结果好,这有可能是样本不足,导致Transformer-Based模型训练不充分。

为了进一步比较不同模型对代码的建模能力,该篇文章在只使用代码修改作为特征的前提下,也对不同模型进行了比较,结果见下图。结果显示Transformer-Based的模型(Transformer)对代码的建模能力会显著优于其他的架构模型(PatchRNN、SPI、Commit2vec、E-SPI w/o changes、E-SPI w/o context);另外我们可以发现AST Paths在代码特征建模有显著的增益,这就导致,在整体上E-SPI对代码的建模能力依然超过了Transformer模型。
文章来自:PaaS技术创新Lab,PaaS技术创新Lab隶属于华为云,致力于综合利用软件分析、数据挖掘、机器学习等技术,为软件研发人员提供下一代智能研发工具服务的核心引擎和智慧大脑。我们将聚焦软件工程领域硬核能力,不断构筑研发利器,持续交付高价值商业特性!加入我们,一起开创研发新“境界”!
PaaS技术创新Lab主页链接:https://www.huaweicloud.com/lab/paas/home.html
【1】Enhancing Security Patch Identification by Capturing Structures in Commits,
论文地址:https://arxiv.org/pdf/2207.09022.pdf